Sådan opretter du en Apache Spark-jobdefinition i Fabric
I dette selvstudium kan du få mere at vide om, hvordan du opretter en Spark-jobdefinition i Microsoft Fabric.
Forudsætninger
Før du kommer i gang, skal du bruge:
- En Fabric-lejerkonto med et aktivt abonnement. Opret en konto gratis.
Tip
Hvis du vil køre spark-jobdefinitionselementet, skal du have en hoveddefinitionsfil og standardkontekst for lakehouse. Hvis du ikke har et lakehouse, kan du oprette et ved at følge trinnene i Opret et lakehouse.
Opret en Spark-jobdefinition
Spark-jobdefinitionsprocessen er hurtig og enkel. Der er flere måder at komme i gang på.
Indstillinger for oprettelse af en Spark-jobdefinition
Du kan komme i gang med oprettelsesprocessen på to måder:
arbejdsområdevisning: Du kan nemt oprette en Spark-jobdefinition via Fabric-arbejdsområdet ved at vælge Nyt element>Spark JobDefinition.
Fabric Home: Et andet indgangspunkt til at oprette en Spark-jobdefinition er Dataanalyse ved hjælp af et SQL ... felt på Fabric-startsiden. Du kan finde den samme indstilling ved at vælge feltet Generelt.


Du skal give definitionen af dit Spark-job et navn, når du opretter den. Navnet skal være entydigt i det aktuelle arbejdsområde. Den nye Spark-jobdefinition oprettes i dit aktuelle arbejdsområde.
Opret en Spark-jobdefinition for PySpark (Python)
Sådan opretter du en Spark-jobdefinition for PySpark:
Download parquet-eksempelfilen yellow_tripdata_2022-01.parquet, og upload den til filafsnittet i lakehouse.
Opret en ny Spark-jobdefinition.
Vælg PySpark (Python) på rullelisten Sprog .
Download createTablefromParquet.py-eksemplet, og upload det som den primære definitionsfil. Den primære definitionsfil (job. Main) er den fil, der indeholder programlogikken, og som er obligatorisk for at køre et Spark-job. For hver Spark-jobdefinition kan du kun uploade én hoveddefinitionsfil.
Du kan uploade den primære definitionsfil fra dit lokale skrivebord, eller du kan uploade fra et eksisterende Azure Data Lake Storage (ADLS) Gen2 ved at angive filens fulde ABFSS-sti. F.eks.,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Upload referencefiler som .py filer. Referencefilerne er python-moduler, der importeres af hoveddefinitionsfilen. På samme måde som den primære definitionsfil kan du uploade fra dit skrivebord eller en eksisterende ADLS Gen2. Flere referencefiler understøttes.
Tip
Hvis du bruger en ADLS Gen2-sti for at sikre, at filen er tilgængelig, skal du give den brugerkonto, der kører jobbet, den korrekte tilladelse til lagerkontoen. Vi foreslår to forskellige måder at gøre dette på:
- Tildel brugerkontoen rollen Bidragyder for lagerkontoen.
- Tildel tilladelsen Læs og Udførelse til brugerkontoen for filen via ADLS Gen2 Access Control List (ACL).
I forbindelse med manuel kørsel bruges kontoen for den aktuelle logonbruger til at køre jobbet.
Angiv kommandolinjeargumenter for jobbet, hvis det er nødvendigt. Brug et mellemrum som opdelingsfunktion til at adskille argumenterne.
Føj lakehouse-referencen til jobbet. Du skal have mindst én lakehouse-reference føjet til jobbet. Dette lakehouse er standardkonteksten for lakehouse for jobbet.
Flere lakehouse-referencer understøttes. Find navnet på det lakehouse, der ikke er standard, og hele OneLake-URL-adressen på siden Spark-indstillinger .
Opret en Spark-jobdefinition til Scala/Java
Sådan opretter du en Spark-jobdefinition til Scala/Java:
Opret en ny Spark-jobdefinition.
Vælg Spark(Scala/Java) på rullelisten Sprog .
Overfør hoveddefinitionsfilen som en .jar fil. Den primære definitionsfil er den fil, der indeholder programlogikken for dette job, og som er obligatorisk for at køre et Spark-job. For hver Spark-jobdefinition kan du kun uploade én hoveddefinitionsfil. Angiv navnet på hovedklassen.
Upload referencefiler som .jar filer. Referencefilerne er de filer, der refereres til/importeres af den primære definitionsfil.
Angiv kommandolinjeargumenter for jobbet, hvis det er nødvendigt.
Føj lakehouse-referencen til jobbet. Du skal have mindst én lakehouse-reference føjet til jobbet. Dette lakehouse er standardkonteksten for lakehouse for jobbet.
Opret en Spark-jobdefinition til R
Sådan opretter du en Spark-jobdefinition for SparkR(R):
Opret en ny Spark-jobdefinition.
Vælg SparkR(R) på rullelisten Sprog .
Overfør hoveddefinitionsfilen som en . R-fil . Den primære definitionsfil er den fil, der indeholder programlogikken for dette job, og som er obligatorisk for at køre et Spark-job. For hver Spark-jobdefinition kan du kun uploade én hoveddefinitionsfil.
Overfør referencefiler som . R-filer . Referencefilerne er de filer, der refereres til/importeres af den primære definitionsfil.
Angiv kommandolinjeargumenter for jobbet, hvis det er nødvendigt.
Føj lakehouse-referencen til jobbet. Du skal have mindst én lakehouse-reference føjet til jobbet. Dette lakehouse er standardkonteksten for lakehouse for jobbet.
Bemærk
Definitionen af Spark-jobbet oprettes i dit aktuelle arbejdsområde.
Indstillinger for tilpasning af Spark-jobdefinitioner
Der er et par muligheder for yderligere at tilpasse udførelsen af Spark-jobdefinitioner.
- Spark Compute: Under fanen Spark Compute kan du se runtime-versionen , som er den version af Spark, der skal bruges til at køre jobbet. Du kan også se de Spark-konfigurationsindstillinger, der bruges til at køre jobbet. Du kan tilpasse indstillingerne for Spark-konfigurationen ved at klikke på knappen Tilføj .
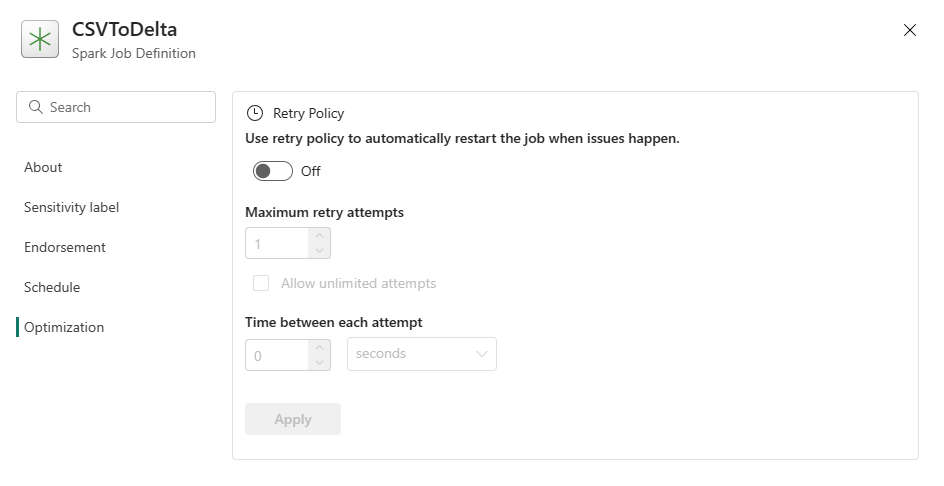
Optimering: Under fanen Optimering kan du aktivere og konfigurere forsøgspolitikken for jobbet. Når indstillingen er aktiveret, bliver jobbet forsøgt igen, hvis det mislykkes. Du kan også angive det maksimale antal forsøg og intervallet mellem nye forsøg. Jobbet genstartes for hvert forsøg. Sørg for, at jobbet er idempotent.