Použití Tidyverse
Tidyverse je kolekce balíčků R, které datoví vědci běžně používají při každodenních analýzách dat. Zahrnuje balíčky pro import dat (), vizualizaci dat (ggplot2readr), manipulaci s daty (dplyr, tidyr), funkční programování (purrr) a vytváření modelů (tidymodels) atd. Balíčky jsou tidyverse navržené tak, aby hladce spolupracovaly a dodržovaly konzistentní sadu principů návrhu.
Microsoft Fabric distribuuje nejnovější stabilní verzi tidyverse s každou verzí modulu runtime. Importujte a začněte používat známé balíčky R.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí na levé straně domovské stránky přepněte na prostředí Synapse Datová Věda.

Otevřete nebo vytvořte poznámkový blok. Postup najdete v tématu Použití poznámkových bloků Microsoft Fabric.
Nastavte možnost jazyka na SparkR (R) a změňte primární jazyk.
Připojte poznámkový blok k jezeru. Na levé straně vyberte Přidat, pokud chcete přidat existující jezerní dům nebo vytvořit jezero.
Náklad tidyverse
# load tidyverse
library(tidyverse)
Import dat
readr je balíček R, který poskytuje nástroje pro čtení obdélníkových datových souborů, jako jsou CSV, TSV a soubory s pevnou šířkou. readr poskytuje rychlý a přátelský způsob čtení obdélníkových datových souborů, jako je poskytování funkcí read_csv() a read_tsv() čtení souborů CSV a TSV v uvedeném pořadí.
Nejprve vytvoříme R data.frame, zapíšeme ho do lakehouse pomocí readr::write_csv() a znovu ho načteme readr::read_csv().
Poznámka:
Pokud chcete získat přístup k souborům Lakehouse pomocí readr, musíte použít cestu k rozhraní File API. V Průzkumníku Lakehouse klikněte pravým tlačítkem na soubor nebo složku, ke které chcete získat přístup, a zkopírujte jeho cestu k rozhraní File API z místní nabídky.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Pak zapíšeme data do lakehouse pomocí cesty k rozhraní File API.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Čtení dat z lakehouse
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Uklidnění dat
tidyr je balíček R, který poskytuje nástroje pro práci s neuspořádanými daty. Hlavní funkce tidyr jsou navržené tak, aby vám pomohly přetváření dat do přehledného formátu. Data Tidy mají specifickou strukturu, kde každá proměnná je sloupec a každé pozorování je řádek, který usnadňuje práci s daty v R a dalších nástrojích.
Například funkci in tidyr lze použít k převodu gather() širokých dat na dlouhá data. Tady je příklad:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Funkční programování
purrr je balíček R, který vylepšuje sadu nástrojů pro funkční programování jazyka R tím, že poskytuje kompletní a konzistentní sadu nástrojů pro práci s funkcemi a vektory. Nejlepším místem purrr , kde začít, je řada map() funkcí, které umožňují nahradit mnoho smyček kódem, který je stručnější a čitelnější. Tady je příklad použití map() funkce pro každý prvek seznamu:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulace s daty
dplyr je balíček R, který poskytuje konzistentní sadu příkazů, které vám pomůžou vyřešit nejběžnější problémy s manipulací s daty, jako je výběr proměnných na základě názvů, výběr případů na základě hodnot, snížení počtu hodnot na jeden souhrn a změna pořadí řádků atd. Tady je několik příkladů:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Vizualizace dat
ggplot2 je balíček jazyka R pro deklarativní vytváření grafiky na základě gramatiky grafiky. Zadáte data, řeknete ggplot2 , jak mapovat proměnné na estetickou architekturu, jaká grafická primitiva se mají použít, a postará se o podrobnosti. Několik příkladů:
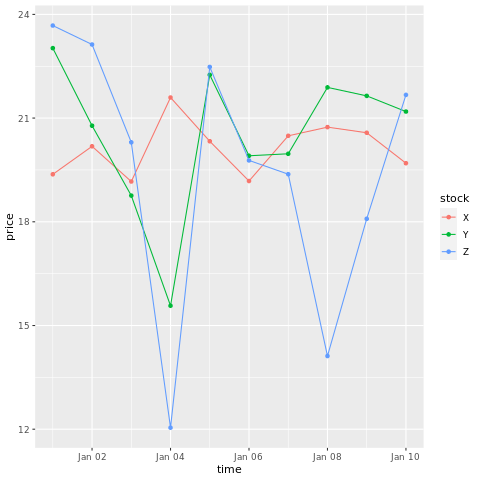
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
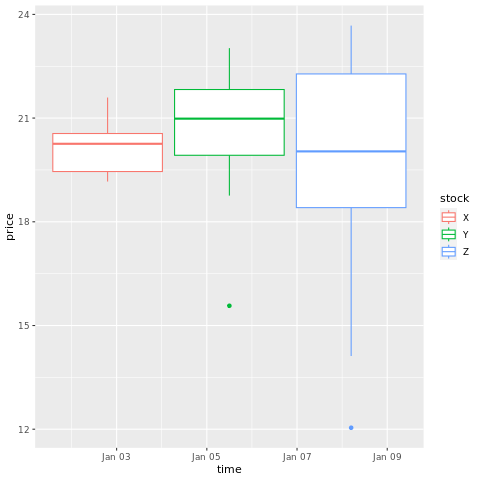
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Vytváření modelů
Architektura tidymodels je kolekce balíčků pro modelování a strojové učení pomocí tidyverse principů. Tento článek obsahuje seznam základních balíčků pro širokou škálu úloh vytváření modelů, jako rsample je rozdělení ukázky trénovací/testovací datové sady, parsnip specifikace modelu, recipes pro předběžné zpracování dat, workflows pro modelování pracovních postupů, tune pro ladění hyperparametrů, yardstick pro vyhodnocení modelu, broom pro vázané výstupy modelu a dials pro správu parametrů ladění. Další informace o balíčcích najdete na webu tidymodels. Tady je příklad vytvoření modelu lineární regrese pro předpověď mil na gallon (mpg) auta na základě jeho hmotnosti (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
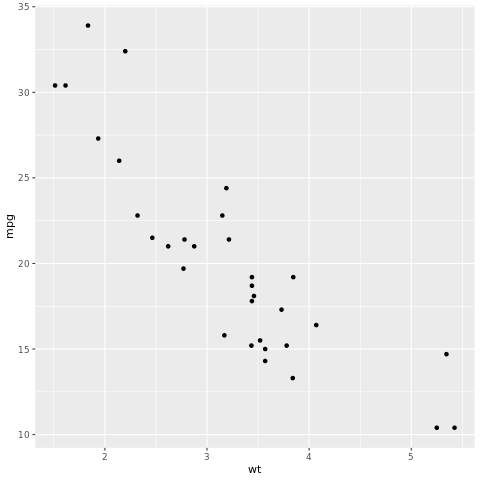
Z bodového grafu vypadá relace přibližně lineární a rozptyl vypadá konstantně. Zkusme to modelovat pomocí lineární regrese.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Použití modelu lineární regrese k predikci testovací datové sady
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
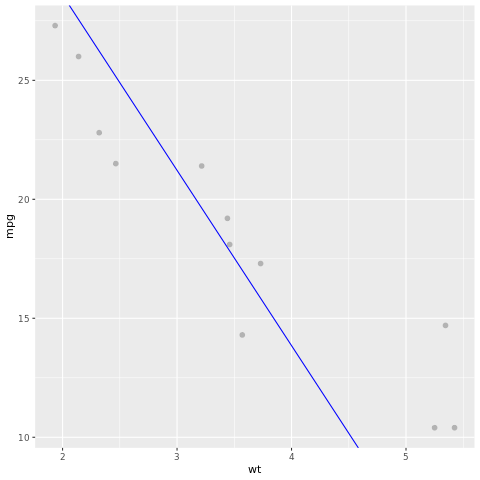
Pojďme se podívat na výsledek modelu. Model můžeme nakreslit jako spojnicový graf a testovací data základní pravdy jako body ve stejném grafu. Model vypadá dobře.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")