Kurz: Použití jazyka R k predikci zpoždění letu
Tento kurz představuje ucelený příklad pracovního postupu Synapse Datová Věda v Microsoft Fabric. Pomocí dat nycflights13 a R předpovídá, jestli letadlo přijíždí déle než 30 minut. Potom použije výsledky předpovědi k vytvoření interaktivního řídicího panelu Power BI.
V tomto kurzu se naučíte:
- Použití balíčků tidymodels (recepty, parsnip, rsample, pracovní postupy) ke zpracování dat a trénování modelu strojového učení
- Zápis výstupních dat do lakehouse jako tabulky delta
- Vytvoření vizuální sestavy Power BI pro přímý přístup k datům v daném jezeře
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Pomocí přepínače prostředí na levé straně domovské stránky přepněte na prostředí Synapse Datová Věda.

Otevřete nebo vytvořte poznámkový blok. Postup najdete v tématu Použití poznámkových bloků Microsoft Fabric.
Nastavte možnost jazyka na SparkR (R) a změňte primární jazyk.
Připojte poznámkový blok k jezeru. Na levé straně vyberte Přidat, pokud chcete přidat existující jezerní dům nebo vytvořit jezero.
Instalace balíčků
Nainstalujte balíček nycflights13 pro použití kódu v tomto kurzu.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Prozkoumání dat
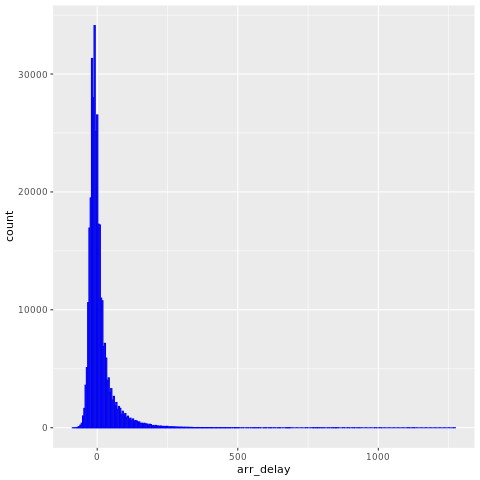
Data nycflights13 mají informace o 325 819 letů, které dorazily poblíž New Yorku v roce 2013. Nejprve si prohlédněte rozdělení zpoždění letů. Tento graf ukazuje, že rozdělení zpoždění příletů je správně nerovnoměrné. Má dlouhý ocas ve vysokých hodnotách.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Načtěte data a proveďte několik změn proměnných:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Než model sestavíme, zvažte několik konkrétních proměnných, které jsou důležité pro předběžné zpracování i modelování.
Proměnná je faktorová proměnná arr_delay . Pro trénování logistického regresního modelu je důležité, aby proměnná výsledku byla faktorovou proměnnou.
glimpse(flight_data)
Přibližně 16 % letů v této datové sadě dorazilo déle než 30 minut pozdě.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Tato dest funkce má 104 letových destinací.
unique(flight_data$dest)
Existují 16 různých operátorů.
unique(flight_data$carrier)
Rozdělení dat
Rozdělte jednu datovou sadu na dvě sady: trénovací sadu a testovací sadu. Většinu řádků v původní datové sadě (jako náhodně vybranou podmnožinu) ponechejte v trénovací datové sadě. Pomocí trénovací datové sady můžete model přizpůsobit a použít testovací datovou sadu k měření výkonu modelu.
rsample Balíček slouží k vytvoření objektu, který obsahuje informace o rozdělení dat. Pak pomocí dvou dalších rsample funkcí vytvořte datové rámce pro trénovací a testovací sady:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Vytvoření receptu a rolí
Vytvořte recept na jednoduchý logistický regresní model. Před trénováním modelu vytvořte nové prediktory pomocí receptu a proveďte předběžné zpracování, které model vyžaduje.
update_role() Použijte funkci, aby recepty věděly, že flight a time_hour jsou proměnné, s vlastní rolí volanou ID. Role může mít libovolnou hodnotu znaku. Vzorec obsahuje všechny proměnné v trénovací sadě, jiné než arr_delay, jako prediktory. Recept udržuje tyto dvě proměnné ID, ale nepoužívá je jako výsledky ani jako prediktory.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Pokud chcete zobrazit aktuální sadu proměnných a rolí, použijte summary() funkci:
summary(flights_rec)
Vytvoření funkcí
Vylepšete model pomocí určitého inženýrství funkcí. Datum letu může mít přiměřený vliv na pravděpodobnost pozdního příletu.
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Může pomoct přidat modelové termíny odvozené od data, které mohou mít pro model význam. Odvozujte z proměnné s jedním datem následující smysluplné funkce:
- Den v týdnu
- Month
- Zda datum odpovídá svátku nebo ne
Přidejte do receptu tři kroky:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Přizpůsobení modelu s receptem
K modelování letových dat použijte logistickou regresi. Nejprve sestavte specifikaci modelu s balíčkem parsnip :
lr_mod <-
logistic_reg() %>%
set_engine("glm")
workflows Balíček použijte k balení parsnip modelu (lr_mod) s vaším receptem (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Trénování modelu
Tato funkce může připravit recept a vytrénovat model z výsledných prediktorů:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Použijte pomocné funkce xtract_fit_parsnip() a extract_recipe() extrahujte objekty modelu nebo receptu z pracovního postupu. V tomto příkladu stáhněte fitovaný objekt modelu a pak pomocí broom::tidy() funkce získejte uklidnění koeficientů modelu:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Predikce výsledků
Jedno volání predict() používá trénovaný pracovní postup (flights_fit) k vytváření předpovědí s nezoznanými testovacími daty. Metoda predict() použije recept na nová data a pak předá výsledky fitovanýmu modelu.
predict(flights_fit, test_data)
Získejte výstup z predict() vrácení predikované třídy: late versus on_time. Pro pravděpodobnosti predikované třídy pro každou testovací verzi je však můžete použít augment() s modelem v kombinaci s testovacími daty, abyste je uložili společně:
flights_aug <-
augment(flights_fit, test_data)
Zkontrolujte data:
glimpse(flights_aug)
Vyhodnocení modelu
Nyní máme k dispozici tibble s predikovanými pravděpodobnostmi třídy. V prvních několika řádcích model správně predikoval pět časového letu (hodnoty .pred_on_time jsou p > 0.50). Máme ale celkem 81 455 řádků, abychom mohli předpovědět.
Potřebujeme metriku, která udává, jak dobře model předpověděl pozdní přílety ve srovnání se skutečným stavem proměnné arr_delayvýsledku .
Jako metriku použijte oblast pod provozní charakteristikou přijímače křivky (AUC-ROC). Vypočítá ho yardstick pomocí roc_curve() balíčku a roc_auc()z balíčku:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Vytvoření sestavy Power BI
Výsledek modelu vypadá dobře. Pomocí výsledků predikce zpoždění letu můžete vytvořit interaktivní řídicí panel Power BI. Na řídicím panelu se zobrazuje počet letů podle dopravce a počet letů podle cíle. Řídicí panel může filtrovat podle výsledků předpovědi zpoždění.
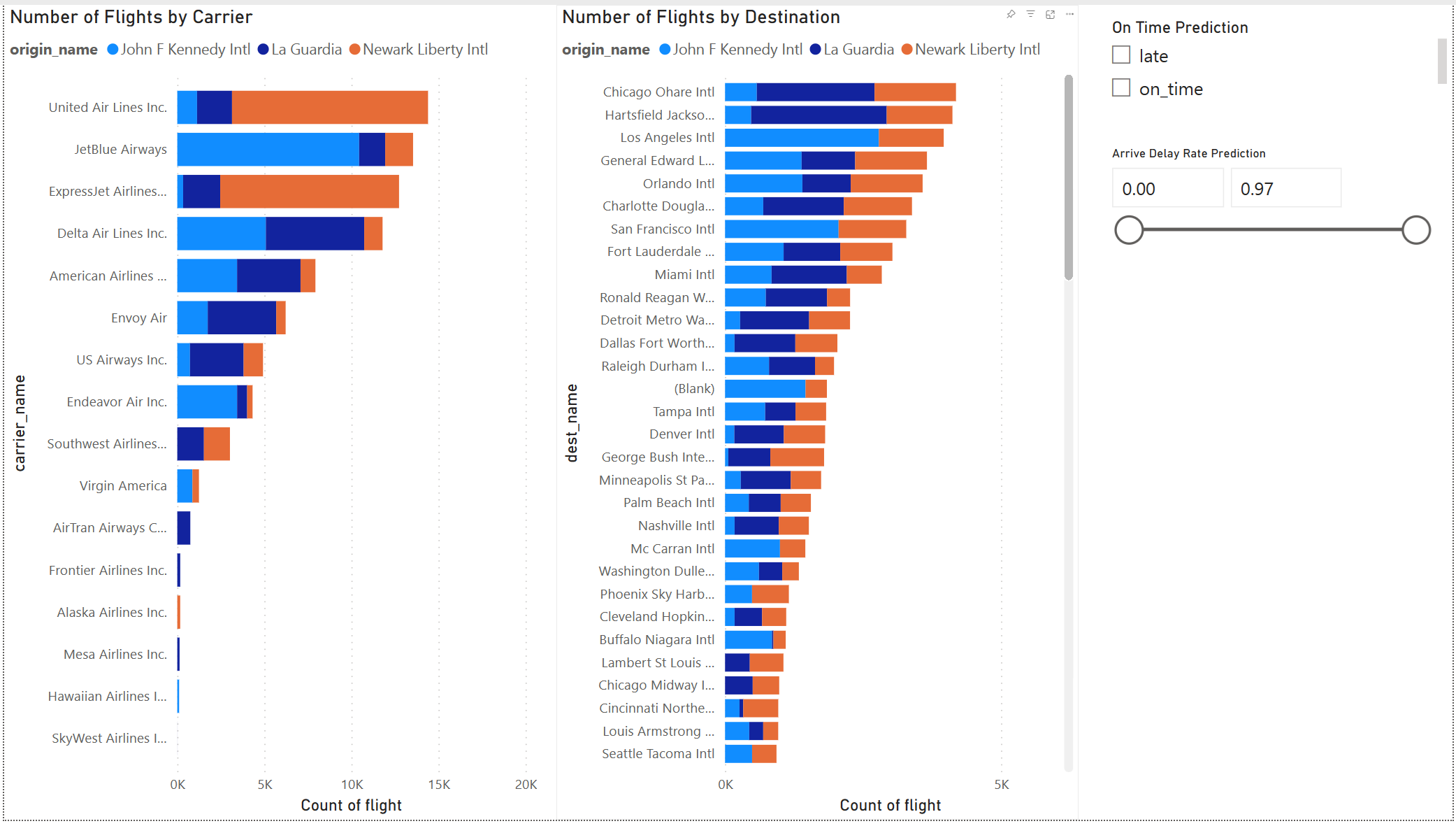
Do datové sady výsledků předpovědi zadejte název dopravce a název letiště:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Zkontrolujte data:
glimpse(flights_clean)
Převeďte data na datový rámec Sparku:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Zapište data do tabulky Delta v jezeře:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
K vytvoření sémantického modelu použijte tabulku Delta.
Vlevo vyberte datové centrum OneLake.
Vyberte jezero, které jste připojili k poznámkovému bloku.
Výběr možnosti Otevřít
Výběr nového sémantického modelu
Vyberte nycflight13 pro nový sémantický model a pak vyberte Potvrdit.
Vytvoří se sémantický model. Vybrat novou sestavu
Vyberte nebo přetáhněte pole z podokna Data a Vizualizace na plátno sestavy a sestavte sestavu.
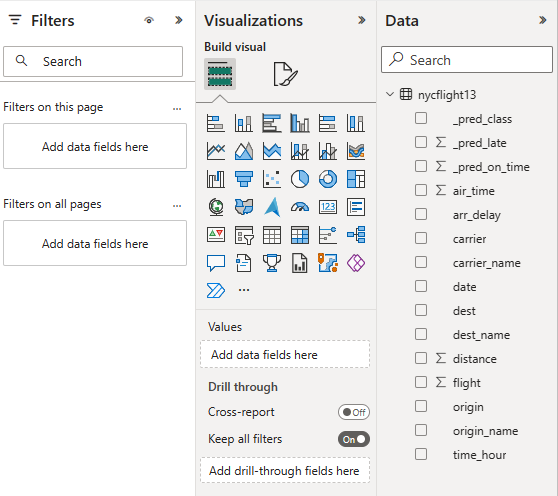
Pokud chcete vytvořit sestavu zobrazenou na začátku této části, použijte tyto vizualizace a data:
 Skládaný pruhový graf s:
Skládaný pruhový graf s: - Osa Y: carrier_name
- Osa X: let. Výběr možnosti Počet pro agregaci
- Legenda: origin_name
- Skládaný pruhový graf s:
- Osa Y: dest_name
- Osa X: let. Výběr možnosti Počet pro agregaci
- Legenda: origin_name
 Průřez s:
Průřez s: - Pole: _pred_class
- Průřez s:
- Pole: _pred_late