Migrace definice úlohy Sparku z Azure Synapse do prostředků infrastruktury
Pokud chcete přesunout definice úloh Sparku (SJD) z Azure Synapse do prostředků infrastruktury, máte dvě různé možnosti:
- Možnost 1: Ruční vytvoření definice úlohy Spark v prostředcích infrastruktury
- Možnost 2: Pomocí skriptu můžete exportovat definice úloh Sparku z Azure Synapse a importovat je do prostředků infrastruktury pomocí rozhraní API.
Důležité informace o definici úloh Sparku najdete v rozdílech mezi Azure Synapse Sparkem a prostředky infrastruktury.
Požadavky
Pokud ho ještě nemáte, vytvořte ve svém tenantovi pracovní prostor Fabric.
Možnost 1: Ruční vytvoření definice úlohy Sparku
Export definice úlohy Sparku z Azure Synapse:
- Otevřete Synapse Studio: Přihlaste se do Azure. Přejděte do svého pracovního prostoru Azure Synapse a otevřete Synapse Studio.
- Vyhledejte úlohu Python/Scala/R Spark: Vyhledejte a identifikujte definici úlohy Python/Scala/R Spark, kterou chcete migrovat.
-
Export konfigurace definice úlohy:
- V synapse Studiu otevřete definici úlohy Sparku.
- Exportujte nebo poznamenejte nastavení konfigurace, včetně umístění souboru skriptu, závislostí, parametrů a dalších relevantních podrobností.
Vytvoření nové definice úlohy Sparku (SJD) na základě exportovaných informací O SJD v prostředcích infrastruktury:
- Přístup k pracovnímu prostoru Prostředky infrastruktury: Přihlaste se k prostředkům infrastruktury a získejte přístup k pracovnímu prostoru.
-
Vytvořte novou definici úlohy Sparku v prostředcích infrastruktury:
- V prostředcích infrastruktury přejděte na Datoví technici domovskou stránku.
- Vyberte definici úlohy Sparku.
- Nakonfigurujte úlohu pomocí informací, které jste exportovali ze služby Synapse, včetně umístění skriptu, závislostí, parametrů a nastavení clusteru.
- Přizpůsobení a testování: Proveďte veškeré potřebné přizpůsobení skriptu nebo konfiguraci tak, aby vyhovovalo prostředí Fabric. Otestujte úlohu v prostředcích infrastruktury, abyste měli jistotu, že běží správně.
Po vytvoření definice úlohy Spark ověřte závislosti:
- Ujistěte se, že používáte stejnou verzi Sparku.
- Ověřte existenci hlavního definičního souboru.
- Ověřte existenci odkazovaných souborů, závislostí a prostředků.
- Propojené služby, připojení ke zdroji dat a přípojné body
Přečtěte si další informace o tom, jak vytvořit definici úlohy Apache Sparku v prostředcích infrastruktury.
Možnost 2: Použití rozhraní FABRIC API
Při migraci postupujte podle těchto klíčových kroků:
- Požadavky.
- Krok 1: Export definice úlohy Sparku z Azure Synapse do OneLake (.json).
- Krok 2: Automatické importování definice úlohy Sparku do prostředků infrastruktury pomocí rozhraní FABRIC API
Požadavky
Požadavky zahrnují akce, které je potřeba zvážit před zahájením migrace definice úlohy Sparku do prostředků infrastruktury.
- Pracovní prostor Infrastruktury.
- Pokud ho ještě nemáte, vytvořte ve svém pracovním prostoru lakehouse Fabric.
Krok 1: Export definice úlohy Sparku z pracovního prostoru Azure Synapse
Cílem kroku 1 je exportovat definici úlohy Sparku z pracovního prostoru Azure Synapse do OneLake ve formátu JSON. Tento proces je následující:
- 1.1) Import poznámkového bloku migrace SJD do pracovního prostoru Fabric Tento poznámkový blok exportuje všechny definice úloh Sparku z daného pracovního prostoru Azure Synapse do zprostředkujícího adresáře ve OneLake. K exportu SJD se používá rozhraní Synapse API.
- 1.2) Nakonfigurujte parametry v prvním příkazu pro export definice úlohy Sparku do zprostředkujícího úložiště (OneLake). Tím se exportuje jenom soubor metadat JSON. Následující fragment kódu slouží ke konfiguraci zdrojových a cílových parametrů. Nezapomeňte je nahradit vlastními hodnotami.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
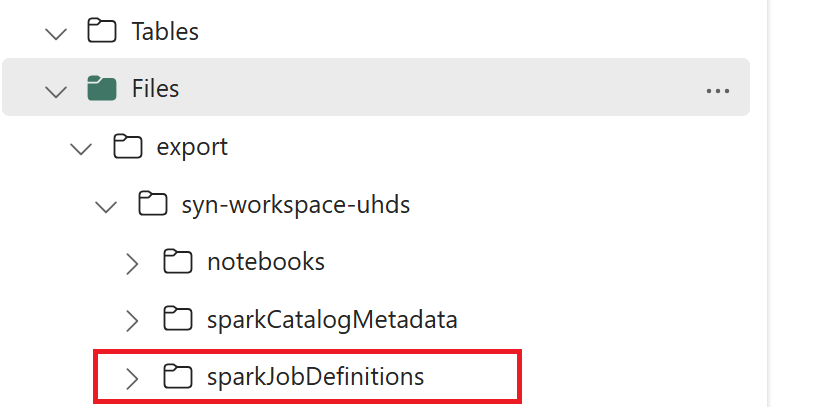
- 1.3) Spuštěním prvních dvou buněk poznámkového bloku pro export a import exportujte metadata definice úlohy Sparku do OneLake. Po dokončení buněk se vytvoří tato struktura složek v zprostředkujícím výstupním adresáři.
Krok 2: Import definice úlohy Sparku do prostředků infrastruktury
Krok 2 spočívá v importu definic úloh Sparku z přechodného úložiště do pracovního prostoru Fabric. Tento proces je následující:
- 2.1) Ověřte konfigurace ve verzi 1.2 a ujistěte se, že je pro import definic úloh Sparku označen správný pracovní prostor a předpona.
- 2.2) Spusťte třetí buňku poznámkového bloku pro export a import a importujte všechny definice úloh Sparku z zprostředkujícího umístění.
Poznámka:
Možnost exportu vypíše soubor metadat JSON. Ujistěte se, že spustitelné soubory definice úlohy Sparku, referenční soubory a argumenty jsou přístupné z prostředků infrastruktury.