Migrace metadat metastoru Hive z Azure Synapse Analytics do prostředků infrastruktury
Počáteční krok migrace metastoru Hive (HMS) zahrnuje určení databází, tabulek a oddílů, které chcete přenést. Není nutné migrovat všechno; můžete vybrat konkrétní databáze. Při identifikaci databází pro migraci nezapomeňte ověřit, jestli existují spravované nebo externí tabulky Sparku.
Důležité informace o HMS najdete v rozdílech mezi Azure Synapse Sparkem a prostředky infrastruktury.
Poznámka:
Pokud ADLS Gen2 obsahuje tabulky Delta, můžete také vytvořit zástupce OneLake tabulky Delta v ADLS Gen2.
Požadavky
- Pokud ho ještě nemáte, vytvořte ve svém tenantovi pracovní prostor Fabric.
- Pokud ho ještě nemáte, vytvořte ve svém pracovním prostoru lakehouse Fabric.
Možnost 1: Export a import HMS do metastoru lakehouse
Při migraci postupujte podle těchto klíčových kroků:
- Krok 1: Export metadat ze zdrojového HMS
- Krok 2: Import metadat do fabric lakehouse
- Kroky po migraci: Ověření obsahu
Poznámka:
Skripty kopírují pouze objekty katalogu Spark do Fabric Lakehouse. Předpokladem je, že data se už kopírují (například z umístění skladu do ADLS Gen2) nebo jsou k dispozici pro spravované a externí tabulky (například prostřednictvím zástupců – upřednostňovaných) do jezera Fabric.
Krok 1: Export metadat ze zdrojového HMS
Cílem kroku 1 je exportovat metadata ze zdrojového HMS do části Soubory vašeho fabric lakehouse. Tento proces je následující:
1.1) Importujte poznámkový blok metadat HMS do pracovního prostoru Azure Synapse. Tento poznámkový blok se dotazuje a exportuje metadata HMS databází, tabulek a oddílů do zprostředkujícího adresáře ve OneLake (funkce ještě nejsou zahrnuté). Rozhraní API interního katalogu Sparku se v tomto skriptu používá ke čtení objektů katalogu.
1.2) Nakonfigurujte parametry v prvním příkazu pro export informací o metadatech do přechodného úložiště (OneLake). Následující fragment kódu slouží ke konfiguraci zdrojových a cílových parametrů. Nezapomeňte je nahradit vlastními hodnotami.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Spuštěním všech příkazů poznámkového bloku exportujte objekty katalogu do OneLake. Po dokončení buněk se vytvoří tato struktura složek v zprostředkujícím výstupním adresáři.
Krok 2: Import metadat do fabric lakehouse
Krok 2 spočívá v importu skutečných metadat z přechodného úložiště do objektu Fabric Lakehouse. Výstupem tohoto kroku je migrace všech metadat HMS (databází, tabulek a oddílů). Tento proces je následující:
2.1) Vytvořte zástupce v části Soubory v jezeře. Tento zástupce musí odkazovat na zdrojový adresář skladu Sparku a později se použije k nahrazení spravovaných tabulek Sparku. Projděte si klávesové zkratky odkazující na adresář skladu Sparku:
- Cesta zástupce k adresáři skladu Azure Synapse Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Cesta zástupce k adresáři skladu Azure Databricks:
dbfs:/mnt/<warehouse_dir> - Cesta zástupce k adresáři skladu HDInsight Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Cesta zástupce k adresáři skladu Azure Synapse Spark:
2.2) Import poznámkového bloku metadat HMS do pracovního prostoru Fabric Importujte tento poznámkový blok pro import objektů databáze, tabulky a oddílů z zprostředkujícího úložiště. Rozhraní API interního katalogu Sparku se v tomto skriptu používá k vytváření objektů katalogu v prostředcích infrastruktury.
2.3) Nakonfigurujte parametry v prvním příkazu. Když v Apache Sparku vytvoříte spravovanou tabulku, data pro tuto tabulku se ukládají do umístění spravovaného samotným Sparkem, obvykle v adresáři skladu Sparku. Přesné umístění určuje Spark. To kontrastuje s externími tabulkami, kde určíte umístění a spravujete podkladová data. Při migraci metadat spravované tabulky (bez přesunutí skutečných dat) metadata stále obsahují informace o původním umístění odkazující na starý adresář skladu Sparku. Proto se u spravovaných tabulek
WarehouseMappingspoužívá k nahrazení pomocí zástupce vytvořeného v kroku 2.1. Všechny zdrojové spravované tabulky se pomocí tohoto skriptu převedou jako externí tabulky.LakehouseIdodkazuje na jezero vytvořené v kroku 2.1 obsahující klávesové zkratky.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Spuštěním všech příkazů poznámkového bloku importujte objekty katalogu z přechodné cesty.
Poznámka:
Při importu více databází můžete (i) vytvořit jeden lakehouse na databázi (použitý přístup) nebo (ii) přesunout všechny tabulky z různých databází do jednoho jezera. U druhé by mohly být <lakehouse>.<db_name>_<table_name>všechny migrované tabulky a budete muset odpovídajícím způsobem upravit poznámkový blok importu.
Krok 3: Ověření obsahu
Krok 3 je místo, kde ověříte, že metadata byla úspěšně migrována. Podívejte se na různé příklady.
Databáze importované spuštěním zobrazíte:
%%sql
SHOW DATABASES
Všechny tabulky v jezeře (databázi) můžete zkontrolovat spuštěním příkazu:
%%sql
SHOW TABLES IN <lakehouse_name>
Podrobnosti o konkrétní tabulce můžete zobrazit spuštěním následujícího příkazu:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
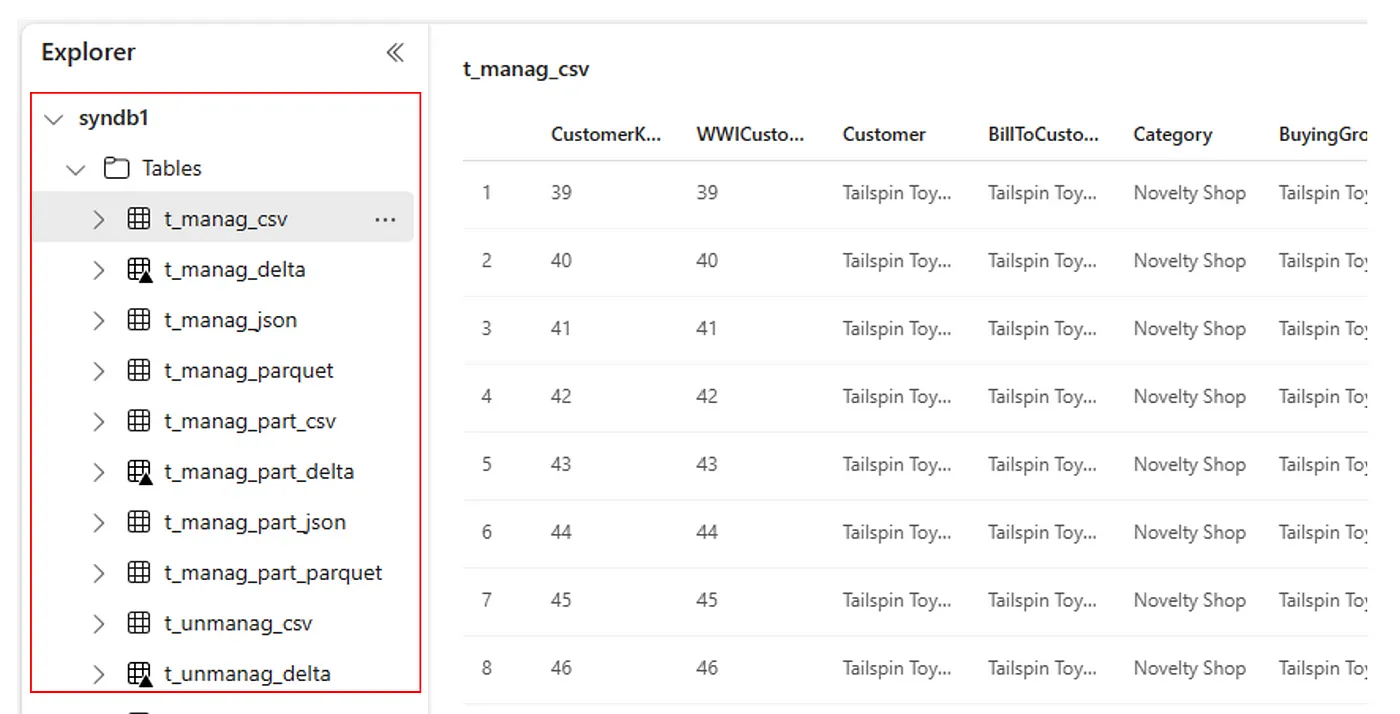
Případně jsou všechny importované tabulky viditelné v části Tabulky uživatelského rozhraní Průzkumníka Lakehouse pro každý lakehouse.
Ostatní úvahy
- Škálovatelnost: Řešení, které k importu nebo exportu používá interní rozhraní API katalogu Spark, ale nepřipojí se přímo k HMS, aby získalo objekty katalogu, takže řešení nemohlo správně škálovat, pokud je katalog velký. Logiku exportu byste museli změnit pomocí databáze HMS.
- Přesnost dat: Neexistuje žádná záruka izolace, což znamená, že pokud výpočetní modul Spark provádí souběžné úpravy metastoru v době, kdy je poznámkový blok migrace spuštěný, mohou být v Fabric Lakehouse zavedena nekonzistentní data.
Související obsah
- Prostředky infrastruktury vs. Azure Synapse Spark
- Další informace o možnostech migrace pro fondy, konfigurace, knihovny, poznámkové bloky a definici úloh Sparku