Sémantické řazení ve službě Azure AI Search
Ve službě Azure AI Search je sémantický ranker funkcí, která měřitelně zlepšuje relevanci vyhledávání pomocí modelů Microsoftu pro rozpoznávání jazyka k přeřazování výsledků hledání. Tento článek je základní úvod, který vám pomůže pochopit chování a výhody sémantického rankeru.
Sémantický ranker je prémiová funkce, která se účtuje podle využití. Tento článek doporučujeme pro pozadí, ale pokud chcete raději začít, postupujte podle těchto kroků.
Poznámka:
Sémantický ranker nepoužívá generující AI ani vektory. Pokud hledáte vektory a vyhledávání podobnosti, podrobnosti najdete v tématu Vektorové vyhledávání ve službě Azure AI Search .
Co je sémantické hodnocení?
Sémantický ranker je kolekce funkcí na straně dotazu, které zlepšují kvalitu počátečního výsledku hledání seřazeného podle BM25 nebo RRF pro textové dotazy, vektorové dotazy a hybridní dotazy. Když ji povolíte ve vyhledávací službě, sémantické řazení rozšíří kanál spouštění dotazů dvěma způsoby:
Nejprve přidá sekundární hodnocení nad počáteční sadou výsledků, která byla hodnocena pomocí BM25 nebo Reciproční Rank Fusion (RRF). Toto sekundární hodnocení využívá vícejazyčné modely hlubokého učení přizpůsobené Microsoft Bingu, aby podporovalo nejvíce sémanticky relevantních výsledků.
Za druhé, extrahuje a vrátí titulky a odpovědi v odpovědi, které můžete vykreslit na vyhledávací stránce, aby se zlepšilo vyhledávání uživatele.
Tady jsou možnosti sémantického rerankeru.
| Schopnost | Popis |
|---|---|
| Pořadí L2 | Použije kontext nebo sémantický význam dotazu k výpočtu nového skóre relevance nad předem seřazenými výsledky. |
| Sémantické titulky a zvýraznění | Extrahuje doslovné věty a fráze z polí, která nejlépe shrnují obsah, a zvýrazní klíčové pasáže pro snadné skenování. Titulky, které shrnují výsledek, jsou užitečné, když jsou jednotlivá pole obsahu pro stránku výsledků hledání příliš hustá. Zvýrazněný text zvyšuje úroveň nejrelevavantnějších termínů a frází, aby uživatelé mohli rychle zjistit, proč byla shoda považována za relevantní. |
| Sémantické odpovědi | Nepovinná a extra dílčí struktura vrácená z sémantického dotazu. Poskytuje přímou odpověď na dotaz, který vypadá jako otázka. Vyžaduje, aby dokument obsahuje text s vlastnostmi odpovědi. |
Jak funguje sémantický ranker
Sémantic ranker feeds a query and results to language understanding models hosted by Microsoft and scans for better matches.
Následující obrázek vysvětluje koncept. Představte si termín "kapitál". Má různé významy v závislosti na tom, jestli je kontext finance, zákon, zeměpis nebo gramatika. Díky porozumění jazyku dokáže sémantický ranker rozpoznat kontext a zvýšit úroveň výsledků, které odpovídají záměru dotazu.
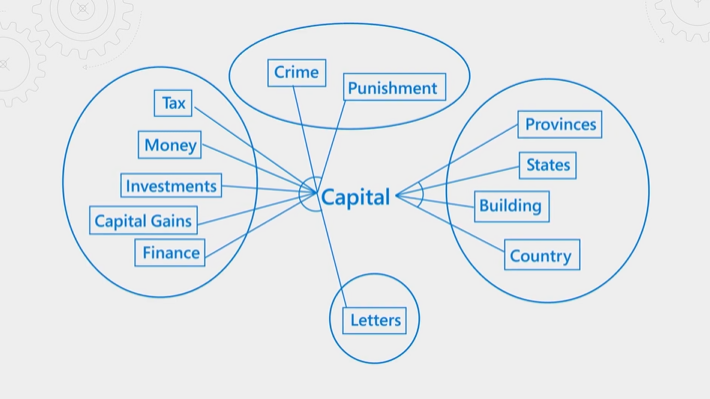
Sémantické hodnocení je náročné jak na prostředky, tak i na čas. Aby bylo možné dokončit zpracování v rámci očekávané latence operace dotazu, jsou vstupy do sémantického rankeru sloučeny a sníženy tak, aby bylo možné co nejrychleji dokončit krok řazení.
Existují tři kroky k sémantickému řazení:
- Shromažďování a shrnutí vstupů
- Skóre výsledků pomocí sémantického rankeru
- Výstup výsledků rescored, titulků a odpovědí
Jak se shromažďují a shrnují vstupy
V sémantickém řazení předává subsystém dotazů výsledky hledání jako vstup pro sumarizaci a modely řazení. Vzhledem k tomu, že modely řazení mají omezení velikosti vstupu a zpracovávají náročné zpracování, musí mít výsledky hledání velikost a strukturovanou (souhrnnou) pro efektivní zpracování.
Sémantický ranker začíná výsledkem seřazeným podle BM25 z textového dotazu nebo výsledku seřazeného RRF z vektoru nebo hybridního dotazu. V rerankingu se používají pouze textová pole a k sémantickému řazení se používají pouze 50 výsledků, a to i v případě, že výsledky obsahují více než 50. Pole použitá v sémantickém řazení jsou obvykle informativní a popisná.
Pro každý dokument ve výsledku hledání přijímá model sumarizace až 2 000 tokenů, kde je token přibližně 10 znaků. Vstupy se sestavují z polí "title", "keyword" a "content" uvedených v sémantické konfiguraci.
Příliš dlouhé řetězce jsou oříznuté, aby se zajistilo, že celková délka splňuje vstupní požadavky kroku shrnutí. Toto cvičení oříznutí je důvod, proč je důležité přidat pole do sémantické konfigurace v pořadí priority. Pokud máte velmi velké dokumenty s poli náročnými na text, bude po maximálním limitu ignorováno cokoli.
Sémantické pole Limit tokenů "title" 128 tokenů Klíčová slova 128 tokenů "obsah" zbývající tokeny Výstup souhrnu je souhrnný řetězec pro každý dokument, který se skládá z nejrelevavantnějších informací z každého pole. Souhrnné řetězce se posílají do rankeru pro bodování a strojově čtené modely porozumění titulkům a odpovědím.
Od listopadu 2024 je maximální délka každého generovaného souhrnného řetězce předaného sémantickému rankeru 2 048 tokenů. Dříve to bylo 256 tokenů.
Jak se hodnocení vyhodnotí
Bodování se provádí přes titulek a veškerý další obsah ze souhrnného řetězce, který vyplní délku 2 048 tokenů.
Titulky se vyhodnocují pro koncepční a sémantickou relevanci vzhledem k zadanému dotazu.
Každému dokumentu se přiřadí @search.rerankerScore na základě sémantické relevance dokumentu pro daný dotaz. Skóre se pohybuje od 4 do 0 (vysoké až nízké), kde vyšší skóre označuje vyšší význam.
Skóre Význam 4.0 Dokument je vysoce relevantní a zcela odpovídá na otázku, i když část může obsahovat další text nesouvisející s otázkou. 3,0 Dokument je relevantní, ale chybí podrobnosti, které by ho dokončily. 2.0 Dokument je poněkud relevantní; odpovídá na otázku buď částečně, nebo pouze na některé aspekty otázky. 1.0 Dokument souvisí s otázkou a odpovídá na malou část. 0,0 Dokument není relevantní. Shody jsou uvedené v sestupném pořadí podle skóre a jsou zahrnuty do datové části odpovědi dotazu. Datová část obsahuje odpovědi, prostý text a zvýrazněné titulky a všechna pole, která jste označili jako načtená nebo zadaná v klauzuli select.
Poznámka:
U každého dotazu mohou distribuce @search.rerankerScore vykazovat mírné odchylky z důvodu podmínek na úrovni infrastruktury. O aktualizacích modelu řazení se také vědělo, že mají vliv na distribuci. Z těchto důvodů, pokud píšete vlastní kód pro minimální prahové hodnoty nebo nastavíte vlastnost prahové hodnoty pro vektorové a hybridní dotazy, nevytvářejte limity příliš podrobné.
Výstupy sémantického rankeru
V každém souhrnném řetězci najdou modely porozumění strojovému čtení pasáže, které jsou nejvýraznější.
Výstupy jsou:
Sémantický titulek dokumentu. Každý titulek je k dispozici ve verzi prostého textu a ve verzi zvýraznění a často je méně než 200 slov na dokument.
Volitelná sémantická odpověď za předpokladu
answers, že jste zadali parametr, dotaz byl položen jako otázka a v dlouhém řetězci se nachází pasáž, která poskytuje pravděpodobnou odpověď na otázku.
Titulky a odpovědi jsou vždy doslovný text z indexu. V tomto pracovním postupu neexistuje žádný model generující umělé inteligence, který vytváří nebo vytváří nový obsah.
Sémantické funkce a omezení
Sémantický ranker je novější technologie, takže je důležité nastavit očekávání o tom, co může a nemůže dělat. Co může dělat:
Zvýšit úroveň shod, které jsou sémanticky blíže záměru původního dotazu.
Najděte řetězce, které se mají použít jako titulky a odpovědi. Titulky a odpovědi se vrátí v odpovědi a dají se vykreslit na stránce výsledků hledání.
To, co sémantický ranker nemůže udělat, je znovu spustit dotaz na celý korpus a najít sémanticky relevantní výsledky. Sémantické řazení přeřadí existující sadu výsledků, která se skládá z 50 nejlepších výsledků podle výchozího algoritmu řazení. Sémantický ranker navíc nemůže vytvářet nové informace ani řetězce. Titulky a odpovědi se extrahují doslovně z obsahu, takže pokud výsledky neobsahují text podobný odpovědím, jazykové modely ho nevygenerují.
I když sémantické hodnocení není v každém scénáři přínosné, může určitý obsah výrazně těžit z jeho schopností. Jazykové modely v sémantických rankerech fungují nejlépe na prohledávatelném obsahu, který je bohatý na informace a strukturovaný jako prose. Znalostní báze, online dokumentace nebo dokumenty, které obsahují popisný obsah, vidí největší zisky z sémantických možností rankeru.
Základní technologie pochází z Bingu a Microsoft Research a je integrovaná do infrastruktury Azure AI Search jako doplňková funkce. Další informace o výzkumu a investicích do AI v sémantických rankerech najdete v tématu Jak AI z Bingu podporuje Azure AI Search (Blog Microsoft Research Blog).
Následující video obsahuje přehled možností.
Dostupnost a ceny
Sémantický ranker je k dispozici ve vyhledávacích službách na úrovních Basic a vyšší, a to v závislosti na regionální dostupnosti.
Když povolíte sémantický ranker, zvolte cenový plán pro tuto funkci:
- Při nižších objemech dotazů (méně než 1 000 měsíčně) je sémantické hodnocení zdarma.
- U vyšších objemů dotazů zvolte standardní cenový plán.
Na stránce s cenami služby Azure AI Search se zobrazuje fakturační sazba pro různé měny a intervaly.
Poplatky za sémantické rankery se účtují, když požadavky na dotazy zahrnují queryType=semantic a hledaný řetězec není prázdný (například search=pet friendly hotels in New York). Pokud je hledaný řetězec prázdný (search=*), nebude se vám nic účtovat, i když je typ dotazu nastavený na sémantickou.
Jak začít s sémantickým rankerem
Zkontrolujte dostupnost v jednotlivých oblastech.
Přihlaste se k webu Azure Portal a ověřte, že je vaše vyhledávací služba Basic nebo vyšší.
Nakonfigurujte sémantický ranker v indexu vyhledávání.
Nastavte dotazy tak, aby vracely sémantické titulky a zvýraznění.