Ladění úloh Sparku se selháním s využitím sady Azure Toolkit for IntelliJ (Preview)
Tento článek obsahuje podrobné pokyny k používání nástrojů HDInsight v sadě Azure Toolkit for IntelliJ ke spouštění aplikací Spark Failure Debug .
Požadavky
Oracle Java Development Kit. V tomto kurzu se používá Java verze 8.0.202.
IntelliJ IDEA Tento článek používá IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Viz Instalace sady Azure Toolkit for IntelliJ.
Připojte se ke clusteru HDInsight. Viz Připojení ke clusteru HDInsight.
Průzkumníka služby Microsoft Azure Storage. Viz stažení Průzkumník služby Microsoft Azure Storage.
Vytvoření projektu pomocí šablony ladění
Vytvořte projekt spark2.3.2, který bude pokračovat v ladění selhání. V tomto dokumentu proveďte ukázkový soubor ladění úloh selhání.
Otevřete IntelliJ IDEA. Otevřete okno Nový projekt.
a. V levém podokně vyberte Azure Spark/HDInsight .
b. V hlavním okně vyberte Projekt Sparku s ukázkou ladění úloh selhání (Preview)(Scala).
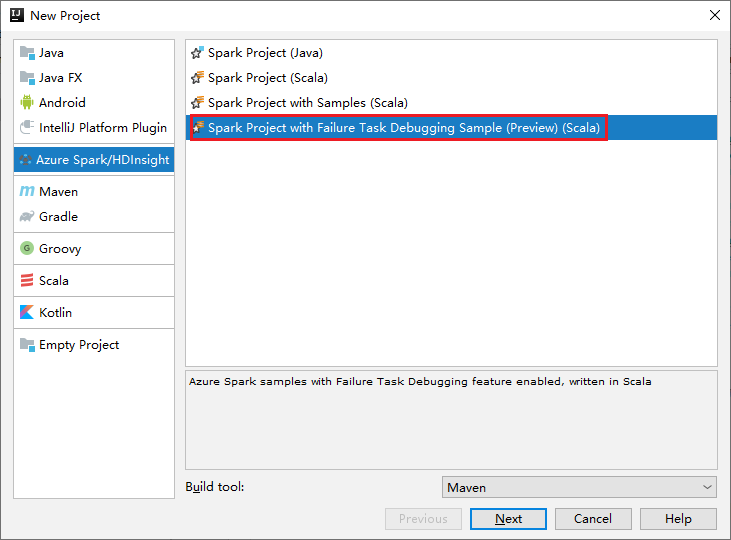
c. Vyberte Další.
V okně Nový projekt proveďte následující kroky:
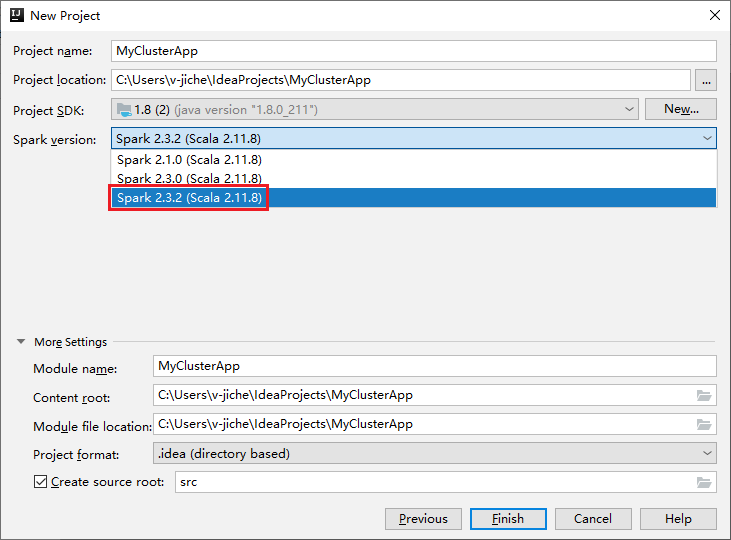
a. Zadejte název projektu a umístění projektu.
b. V rozevíracím seznamu Sady Project SDK vyberte Java 1.8 pro cluster Spark 2.3.2 .
c. V rozevíracím seznamu Verze Sparku vyberte Spark 2.3.2(Scala 2.11.8).
d. Vyberte Dokončit.
Výběrem hlavní>scaly src>otevřete kód v projektu. Tento příklad používá skript AgeMean_Div().
Spuštění aplikace Spark Scala/Java v clusteru HDInsight
Vytvořte aplikaci Spark Scala/Java a pak ji spusťte v clusteru Spark pomocí následujících kroků:
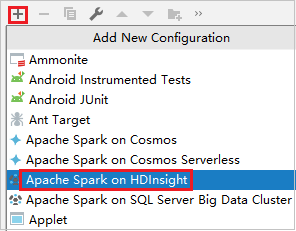
Kliknutím na Přidat konfiguraci otevřete okno Konfigurace spuštění nebo ladění .

V dialogovém okně Spustit nebo ladit konfigurace vyberte znaménko plus (+). Pak vyberte možnost Apache Spark ve službě HDInsight .
Přepněte na kartu Vzdálené spuštění v clusteru . Zadejte informace pro název, cluster Spark a název hlavní třídy. Naše nástroje podporují ladění pomocí exekutorů. numExecutors, výchozí hodnota je 5 a lépe byste nenastavili vyšší než 3. Pokud chcete zkrátit dobu běhu, můžete do konfigurace úloh přidat spark.yarn.maxAppAttempts a nastavit hodnotu na 1. Kliknutím na tlačítko OK uložte konfiguraci.
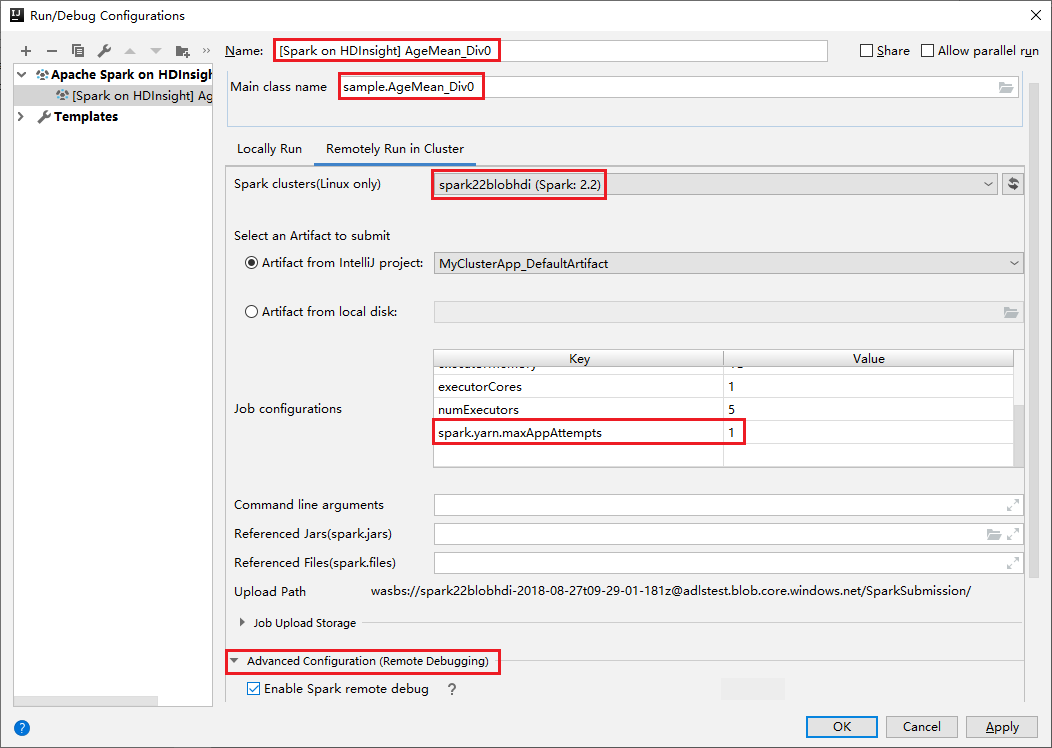
Konfigurace se teď uloží s zadaným názvem. Pokud chcete zobrazit podrobnosti o konfiguraci, vyberte název konfigurace. Pokud chcete provést změny, vyberte Upravit konfigurace.
Po dokončení nastavení konfigurací můžete projekt spustit na vzdáleném clusteru.

ID aplikace můžete zkontrolovat z okna výstupu.

Stažení profilu neúspěšné úlohy
Pokud odeslání úlohy selže, můžete profil neúspěšné úlohy stáhnout do místního počítače pro další ladění.
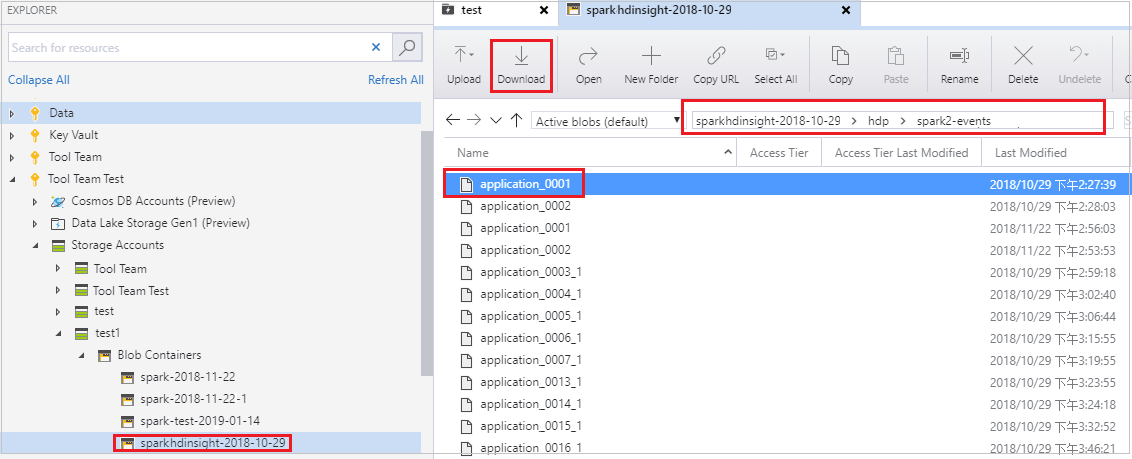
Otevřete Průzkumník služby Microsoft Azure Storage, vyhledejte účet HDInsight clusteru pro neúspěšnou úlohu, stáhněte prostředky neúspěšné úlohy z odpovídajícího umístění: \hdp\spark2-events\.spark-failures\<ID> aplikace do místní složky. V okně aktivit se zobrazí průběh stahování.
Konfigurace místního prostředí ladění a ladění při selhání
Otevřete původní projekt nebo vytvořte nový projekt a přidružte ho k původnímu zdrojovému kódu. Ladění selhání v současné době podporuje pouze verze Spark2.3.2.
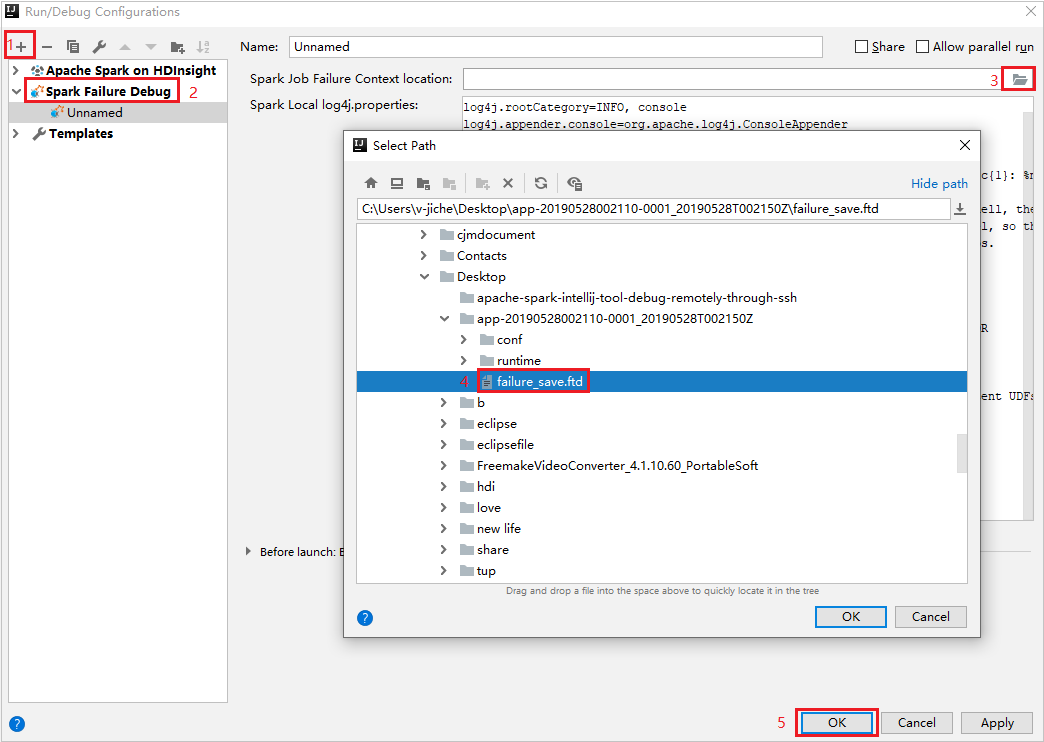
V IntelliJ IDEA vytvořte konfigurační soubor ladění selhání Sparku, vyberte soubor FTD z dříve stažených prostředků neúspěšné úlohy pro pole umístění kontextu selhání úlohy Sparku.
Klikněte na tlačítko místního spuštění na panelu nástrojů. Chyba se zobrazí v okně Spustit.
Nastavte zarážku tak, jak to značí protokol, a potom klikněte na tlačítko místního ladění a proveďte místní ladění stejně jako běžné projekty Scala / Java v IntelliJ.
Po úspěšném dokončení ladění můžete po úspěšném dokončení projektu znovu odeslat neúspěšnou úlohu sparku v clusteru HDInsight.
Další kroky
Scénáře
- Apache Spark s BI: Interaktivní analýza dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Vytvoření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- Použití sady Azure Toolkit for IntelliJ k vytvoření aplikací Apache Spark pro cluster HDInsight
- Použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark prostřednictvím sítě VPN
- Vytváření aplikací Apache Spark pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Jádra dostupná pro Poznámkový blok Jupyter v clusteru Apache Spark pro HDInsight
- Použití externích balíčků s poznámkovými bloky Jupyter
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark