Instalace Aplikace Jupyter Notebook do počítače a připojení k Apache Sparku ve službě HDInsight
V tomto článku se dozvíte, jak nainstalovat Jupyter Notebook s vlastními jádry PySpark (pro Python) a Apache Spark (pro Scala) pomocí magic Sparku. Poznámkový blok pak připojíte ke clusteru HDInsight.
Při instalaci Jupyteru a při připojování k Apache Sparku ve službě HDInsight se používají čtyři klíčové kroky.
- Konfigurace clusteru Spark
- Nainstalujte Jupyter Notebook.
- Nainstalujte jádra PySpark a Spark pomocí magic Sparku.
- Nakonfigurujte magic Spark pro přístup ke clusteru Spark ve službě HDInsight.
Další informace o vlastních jádrech a magii Sparku najdete v tématu Jádra dostupná pro poznámkové bloky Jupyter s clustery Apache Spark Linux ve službě HDInsight.
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight. Místní poznámkový blok se připojí ke clusteru HDInsight.
Znalost používání poznámkových bloků Jupyter se Sparkem ve službě HDInsight.
Instalace Aplikace Jupyter Notebook do počítače
Před instalací poznámkových bloků Jupyter Nainstalujte Python. Distribuce Anaconda nainstaluje jak Python, tak Jupyter Notebook.
Stáhněte si instalační program Anaconda pro vaši platformu a spusťte instalaci. Při spuštění průvodce instalací nezapomeňte vybrat možnost přidání Anaconda do proměnné PATH. Viz také instalace Jupyteru pomocí Anaconda.
Instalace magic Sparku
Zadáním příkazu
pip install sparkmagic==0.13.1nainstalujte magic Spark pro clustery HDInsight verze 3.6 a 4.0. Viz také dokumentace sparkmagic.Spuštěním následujícího příkazu se ujistěte
ipywidgets, že je správně nainstalovaný:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Instalace jader PySpark a Spark
Určete, kde
sparkmagicse instaluje, zadáním následujícího příkazu:pip show sparkmagicPotom změňte pracovní adresář na umístění identifikované výše uvedeným příkazem.
V novém pracovním adresáři zadejte jeden nebo několik následujících příkazů pro instalaci požadovaných jader:
jádro Příkaz Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelNepovinné. Zadáním následujícího příkazu povolte rozšíření serveru:
jupyter serverextension enable --py sparkmagic
Konfigurace magic Sparku pro připojení ke clusteru HDInsight Spark
V této části nakonfigurujete kouzlo Sparku, které jste nainstalovali dříve, pro připojení ke clusteru Apache Spark.
Spusťte prostředí Pythonu pomocí následujícího příkazu:
pythonInformace o konfiguraci Jupyteru jsou obvykle uložené v domovském adresáři uživatelů. Zadáním následujícího příkazu identifikujte domovský adresář a vytvořte složku s názvem .sparkmagic. Vypíše se úplná cesta.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Ve složce
.sparkmagicvytvořte soubor s názvem config.json a přidejte do ní následující fragment kódu JSON.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Proveďte následující úpravy souboru:
Hodnota šablony Nová hodnota {USERNAME} Přihlášení ke clusteru, výchozí hodnota je admin.{CLUSTERDNSNAME} Název clusteru {BASE64ENCODEDPASSWORD} Zakódované heslo base64 pro vaše skutečné heslo. Heslo base64 můžete vygenerovat na adrese https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Pokud používáte sparkmagic 0.12.7clustery v3.5 a v3.6, pokračujte. Pokud používátesparkmagic 0.2.3(clustery v3.4), nahraďte ho ."should_heartbeat": trueÚplný ukázkový soubor najdete v ukázkové config.json.
Tip
Prezenční signály se odesílají, aby nedošlo k úniku relací. Když počítač přejde do režimu spánku nebo je vypnutý, prezenčních signálů se neodesílají a relace se vyčistí. Pokud chcete toto chování zakázat, můžete u clusterů verze 3.4 nastavit konfiguraci
livy.server.interactive.heartbeat.timeoutLivy z0uživatelského rozhraní Ambari. Pokud u clusterů verze 3.5 nenastavíte výše uvedenou konfiguraci 3.5, relace se neodstraní.Spusťte Jupyter. Z příkazového řádku použijte následující příkaz.
jupyter notebookOvěřte, že můžete použít magic Spark dostupný s jádry. Proveďte následující kroky.
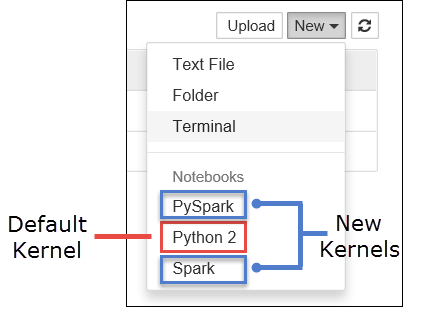
a. Vytvořte nový poznámkový blok. V pravém rohu vyberte Nový. Měli byste vidět výchozí jádro Python 2 nebo Python 3 a jádra, která jste nainstalovali. Skutečné hodnoty se můžou lišit v závislosti na vašich možnostech instalace. Vyberte PySpark.
Důležité
Po výběru možnosti Nový zkontrolujte případné chyby v prostředí. Pokud se zobrazí chyba
TypeError: __init__() got an unexpected keyword argument 'io_loop', může docházet ke známému problému s určitými verzemi tornado. Pokud ano, zastavte jádro a pak downgrade instalace Tornado pomocí následujícího příkazu:pip install tornado==4.5.3.b. Spusťte následující fragment kódu.
%%sql SELECT * FROM hivesampletable LIMIT 5Pokud můžete úspěšně načíst výstup, otestuje se vaše připojení ke clusteru HDInsight.
Pokud chcete aktualizovat konfiguraci poznámkového bloku pro připojení k jinému clusteru, aktualizujte config.json novou sadou hodnot, jak je znázorněno v kroku 3 výše.
Proč mám do počítače nainstalovat Jupyter?
Důvody instalace Jupyteru do počítače a jeho následné připojení ke clusteru Apache Spark ve službě HDInsight:
- Poskytuje možnost vytvořit poznámkové bloky místně, otestovat aplikaci na spuštěném clusteru a pak nahrát poznámkové bloky do clusteru. Pokud chcete nahrát poznámkové bloky do clusteru, můžete je nahrát buď pomocí poznámkového bloku Jupyter, který je spuštěný, nebo clusteru, nebo je uložit do
/HdiNotebookssložky v účtu úložiště přidruženém ke clusteru. Další informace o tom, jak jsou poznámkové bloky uložené v clusteru, najdete v tématu Kde jsou uložené poznámkové bloky Jupyter? - S poznámkovými bloky dostupnými místně se můžete připojit k různým clusterům Spark na základě požadavku vaší aplikace.
- GitHub můžete použít k implementaci systému správy zdrojového kódu a správu verzí pro poznámkové bloky. Můžete také mít prostředí pro spolupráci, ve kterém může pracovat více uživatelů se stejným poznámkovým blokem.
- S poznámkovými bloky můžete pracovat místně, aniž byste museli mít cluster. K otestování poznámkových bloků potřebujete jenom cluster, nikoli ruční správu poznámkových bloků nebo vývojového prostředí.
- Konfigurace vlastního místního vývojového prostředí může být jednodušší než konfigurace instalace Jupyteru v clusteru. Můžete využít výhod veškerého softwaru, který jste nainstalovali místně, aniž byste museli konfigurovat jeden nebo více vzdálených clusterů.
Upozorňující
S nainstalovaným Jupyterem na místním počítači může několik uživatelů spustit stejný poznámkový blok ve stejném clusteru Spark najednou. V takové situaci se vytvoří více relací Livy. Pokud narazíte na problém a chcete ho ladit, bude to složitý úkol sledovat, která relace Livy patří danému uživateli.