Ladění aplikací Apache Spark v clusteru HDInsight pomocí sady Azure Toolkit for IntelliJ prostřednictvím SSH
Tento článek obsahuje podrobné pokyny k použití nástrojů HDInsight v sadě Azure Toolkit for IntelliJ k vzdálenému ladění aplikací v clusteru HDInsight.
Požadavky
Cluster Apache Spark ve službě HDInsight. Viz Vytvoření clusteru Apache Spark.
Uživatelé Windows: Při spouštění místní aplikace Spark Scala na počítači s Windows se může zobrazit výjimka, jak je vysvětleno ve SPARK-2356. K výjimce dochází, protože v systému Windows chybí WinUtils.exe.
Pokud chcete tuto chybu vyřešit, stáhněte Winutils.exe do umístění, jako je C:\WinUtils\bin. Potom přidejte proměnnou prostředí HADOOP_HOME a nastavte hodnotu proměnné na C:\WinUtils.
IntelliJ IDEA (Edice Community je zdarma).)
Klient SSH. Další informace najdete v tématu Připojení ke službě HDInsight (Apache Hadoop) pomocí SSH.
Vytvoření aplikace Spark Scala
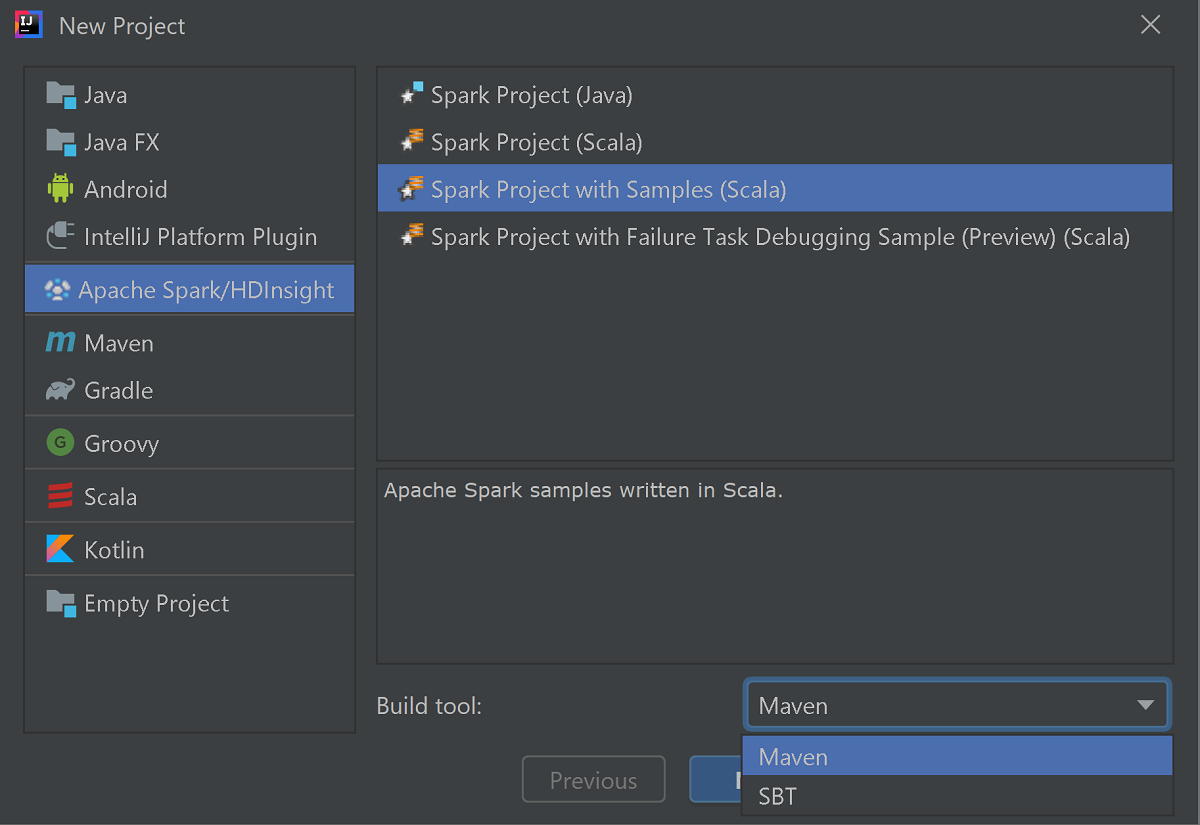
Spusťte IntelliJ IDEA a výběrem možnosti Vytvořit nový projekt otevřete okno Nový projekt.
V levém podokně vyberte Apache Spark/HDInsight .
V hlavním okně vyberte Projekt Sparku s ukázkami (Scala ).
V rozevíracím seznamu Nástroje sestavení vyberte jednu z následujících možností:
- Podpora Průvodce vytvořením projektu Maven pro Scala
- SBT pro správu závislostí a sestavování pro projekt Scala.
Vyberte Další.
V dalším okně Nový projekt zadejte následující informace:
Vlastnost Popis Název projektu Zadejte název. Tento návod k použití myApp.Umístění projektu Zadejte požadované umístění pro uložení projektu. Project SDK Pokud je prázdná, vyberte Nový... a přejděte na sadu JDK. Verze Sparku Průvodce vytvořením integruje správnou verzi sady Spark SDK a Scala SDK. Pokud je verze clusteru Spark nižší než 2.0, vyberte Spark 1.x. V opačném případě vyberte Spark 2.x.. V tomto příkladu se používá Spark 2.3.0 (Scala 2.11.8). 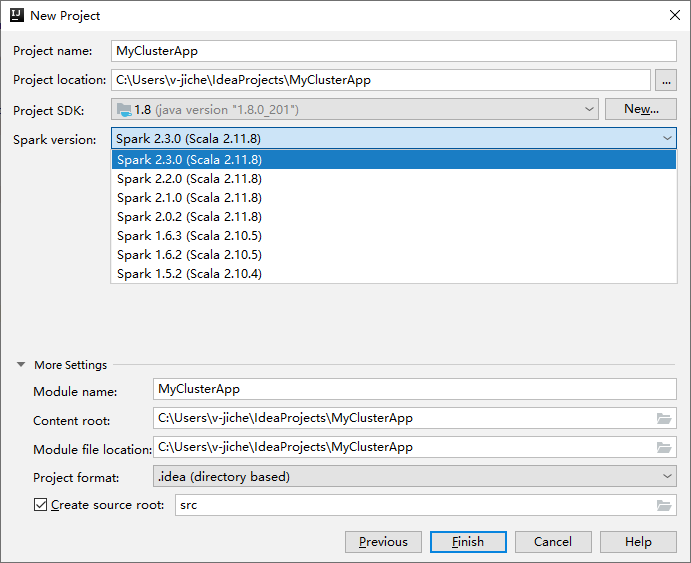
Vyberte Dokončit. Než bude projekt dostupný, může to trvat několik minut. Sledujte průběh v pravém dolním rohu.
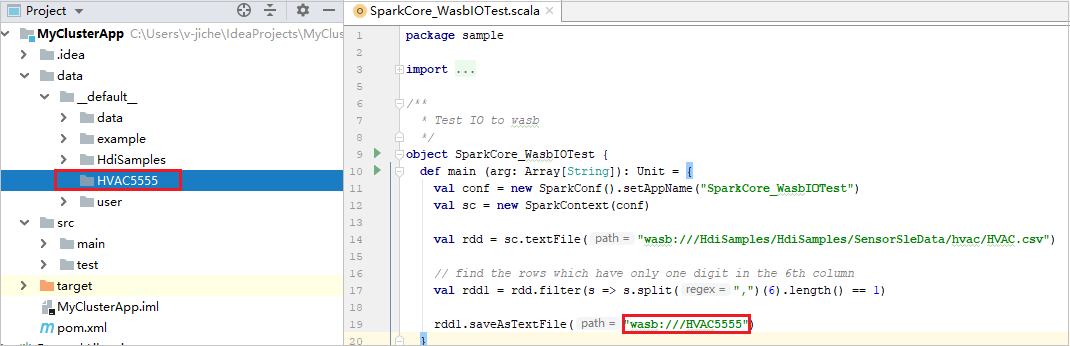
Rozbalte projekt a přejděte k hlavní>ukázce scala>src.> Poklikejte na SparkCore_WasbIOTest.
Provedení místního spuštění
Ve skriptu SparkCore_WasbIOTest klikněte pravým tlačítkem myši na editor skriptů a vyberte možnost Spustit SparkCore_WasbIOTest pro místní spuštění.
Po dokončení místního spuštění uvidíte výstupní soubor, který se uloží do aktuálního výchozího data>Průzkumníka projektů.
Naše nástroje nastavily výchozí konfiguraci místního spuštění automaticky při provádění místního spuštění a místního ladění. Otevřete konfiguraci [Spark ve službě HDInsight] XXX v pravém horním rohu, uvidíte [Spark ve službě HDInsight]XXX již vytvořený v Apache Sparku ve službě HDInsight. Přepněte na kartu Místně spustit .
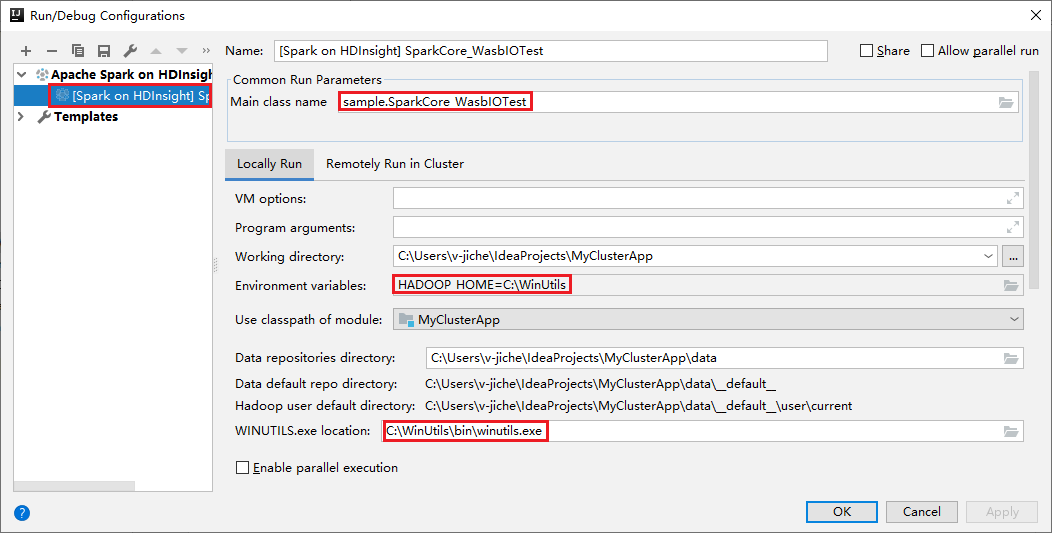
- Proměnné prostředí: Pokud jste již nastavili systémovou proměnnou prostředí HADOOP_HOME na C:\WinUtils, může automaticky zjistit, že není nutné ručně přidávat.
- WinUtils.exe Umístění: Pokud jste nenastavili systémovou proměnnou prostředí, můžete umístění najít kliknutím na tlačítko.
- Stačí zvolit jednu ze dvou možností a nejsou potřeba v systémech macOS a Linux.
Konfiguraci můžete také nastavit ručně před místním spuštěním a místním laděním. Na předchozím snímku obrazovky vyberte znaménko plus (+). Pak vyberte možnost Apache Spark ve službě HDInsight . Zadejte informace pro název, název hlavní třídy, který chcete uložit, a potom klikněte na tlačítko místního spuštění.
Provádění místního ladění
Otevřete skript SparkCore_wasbloTest a nastavte zarážky.
Klikněte pravým tlačítkem myši na editor skriptů a vyberte možnost Ladit '[Spark ve službě HDInsight]XXX, aby se provedlo místní ladění.
Provedení vzdáleného spuštění
Přejděte do části Spustit>konfiguraci úprav.... V této nabídce můžete vytvořit nebo upravit konfigurace pro vzdálené ladění.
V dialogovém okně Spustit nebo ladit konfigurace vyberte znaménko plus (+). Pak vyberte možnost Apache Spark ve službě HDInsight .
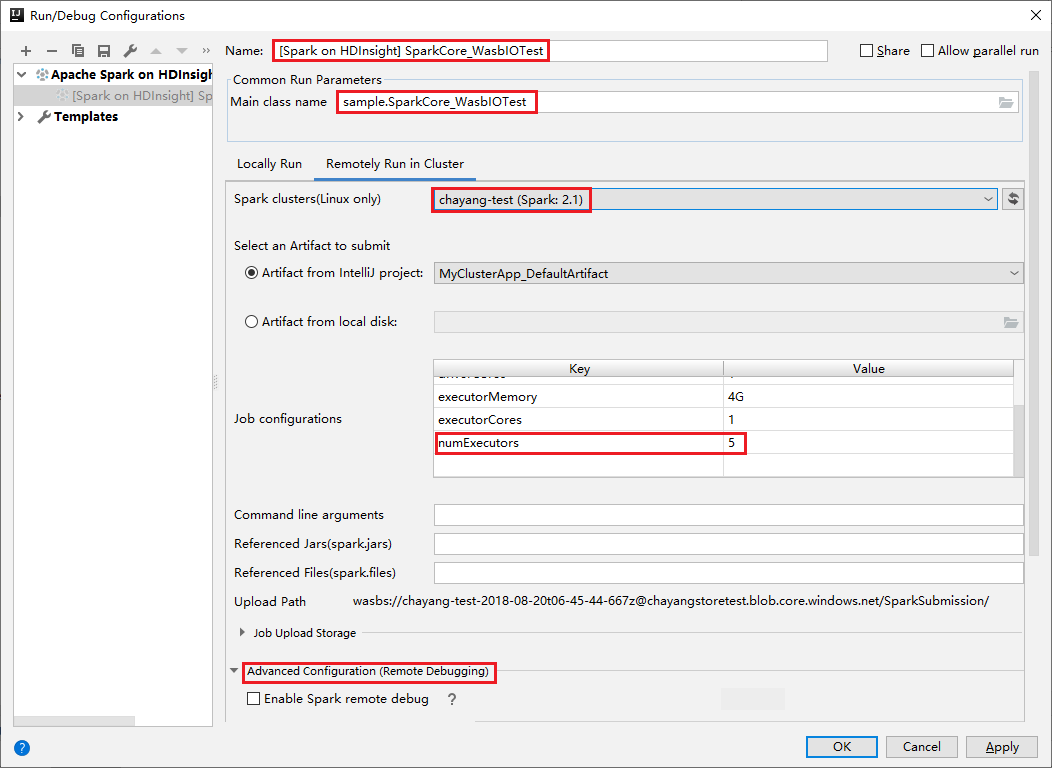
Přepněte na kartu Vzdálené spuštění v clusteru . Zadejte informace pro název, cluster Spark a název hlavní třídy. Potom klikněte na pokročilou konfiguraci (vzdálené ladění). Naše nástroje podporují ladění pomocí exekutorů. numExecutors, výchozí hodnota je 5. Raději byste nenastavili vyšší než 3.
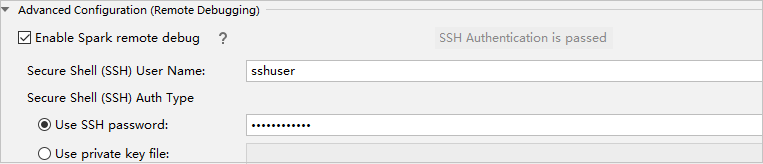
V části Pokročilá konfigurace (vzdálené ladění) vyberte Povolit vzdálené ladění Sparku. Zadejte uživatelské jméno SSH a zadejte heslo nebo použijte soubor privátního klíče. Pokud chcete provést vzdálené ladění, musíte ho nastavit. Pokud chcete jenom použít vzdálené spuštění, nemusíte ho nastavovat.
Konfigurace se teď uloží s zadaným názvem. Pokud chcete zobrazit podrobnosti o konfiguraci, vyberte název konfigurace. Pokud chcete provést změny, vyberte Upravit konfigurace.
Po dokončení nastavení konfigurace můžete projekt spustit na vzdáleném clusteru nebo provést vzdálené ladění.

Klikněte na tlačítko Odpojit , které se v levém panelu nezobrazují protokoly odeslání. Stále ale běží na back-endu.
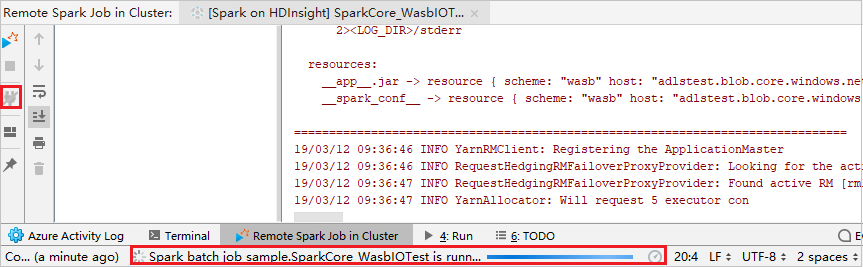
Provádění vzdáleného ladění
Nastavte zásadní body a klikněte na ikonu vzdáleného ladění . Rozdíl mezi vzdáleným odesláním spočívá v tom, že je potřeba nakonfigurovat uživatelské jméno a heslo SSH.

Když provádění programu dosáhne bodu přerušení, zobrazí se karta Ovladač a dvě karty Exekutor v podokně ladicího programu . Výběrem ikony Pokračovat v programu pokračujte ve spuštění kódu, který pak dosáhne další zarážky. Pokud chcete najít cílový exekutor pro ladění, musíte přepnout na správnou kartu Exekutoru . Protokoly spuštění můžete zobrazit na odpovídající kartě Konzola .
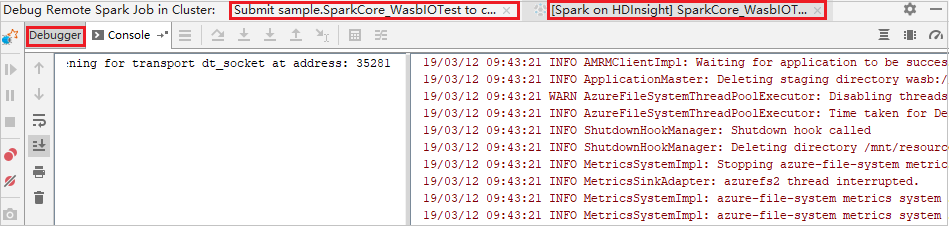
Provádění vzdáleného ladění a opravy chyb
Nastavte dva zásadní body a pak výběrem ikony Ladění spusťte proces vzdáleného ladění.
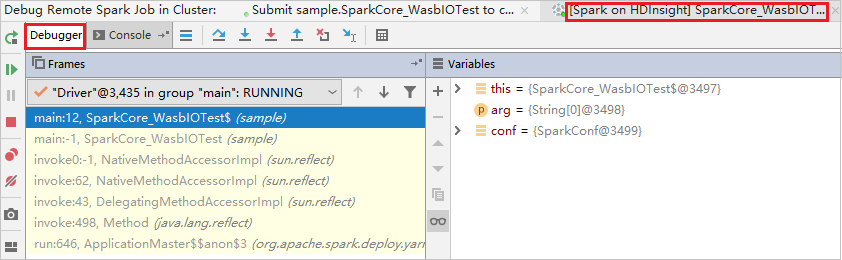
Kód se zastaví v prvním bodu způsobujícího přerušení a informace o parametru a proměnné se zobrazí v podokně Proměnné .
Pokračujte výběrem ikony Pokračovat v programu. Kód se zastaví ve druhém bodě. Výjimka se zachytí podle očekávání.
Znovu vyberte ikonu Pokračovat v programu. V okně odeslání Sparku služby HDInsight se zobrazí chyba "Spuštění úlohy se nezdařilo".

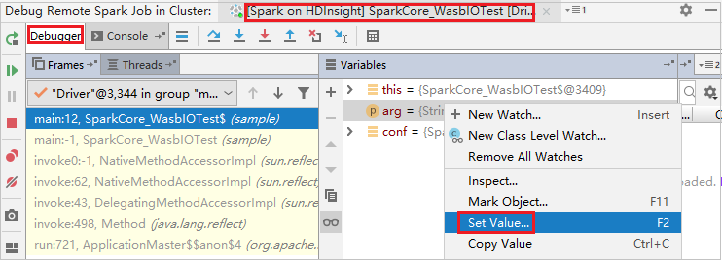
Pokud chcete dynamicky aktualizovat hodnotu proměnné pomocí funkce ladění IntelliJ, znovu vyberte Ladit . Znovu se zobrazí podokno Proměnné .
Pravým tlačítkem myši klikněte na cíl na kartě Ladění a pak vyberte Nastavit hodnotu. Dále zadejte novou hodnotu proměnné. Potom tuto hodnotu uložte výběrem klávesy Enter .
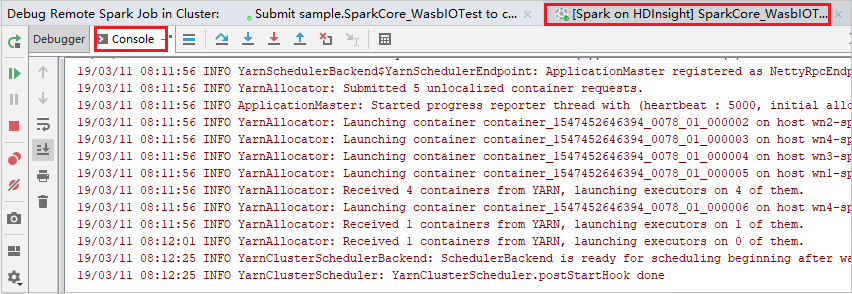
Pokud chcete pokračovat ve spuštění programu, vyberte ikonu Pokračovat v programu. Tentokrát se nezachytí žádná výjimka. Vidíte, že se projekt úspěšně spustí bez jakýchkoli výjimek.
Další kroky
Scénáře
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se službou Machine Learning: Použití Sparku ve službě HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Vytvoření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- Použití sady Azure Toolkit for IntelliJ k vytvoření aplikací Apache Spark pro cluster HDInsight
- Použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark prostřednictvím sítě VPN
- Vytváření aplikací Apache Spark pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Jádra dostupná pro Poznámkový blok Jupyter v clusteru Apache Spark pro HDInsight
- Použití externích balíčků s poznámkovými bloky Jupyter
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark