Ladění úloh Apache Spark spuštěných ve službě Azure HDInsight
V tomto článku se dozvíte, jak sledovat a ladit úlohy Apache Spark spuštěné v clusterech HDInsight. Ladění pomocí uživatelského rozhraní Apache Hadoop YARN, uživatelského rozhraní Sparku a serveru historie Sparku. Úlohu Spark spustíte pomocí poznámkového bloku dostupného v clusteru Spark, strojové učení: Prediktivní analýza dat kontroly potravin pomocí knihovny MLLib. Pomocí následujících kroků můžete sledovat aplikaci, kterou jste odeslali, pomocí jakéhokoli jiného přístupu, například spark-submit.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
Měli byste začít spouštět poznámkový blok, Strojové učení: Prediktivní analýza dat kontroly potravin pomocí knihovny MLLib. Pokyny ke spuštění tohoto poznámkového bloku najdete na odkazu.
Sledování aplikace v uživatelském rozhraní YARN
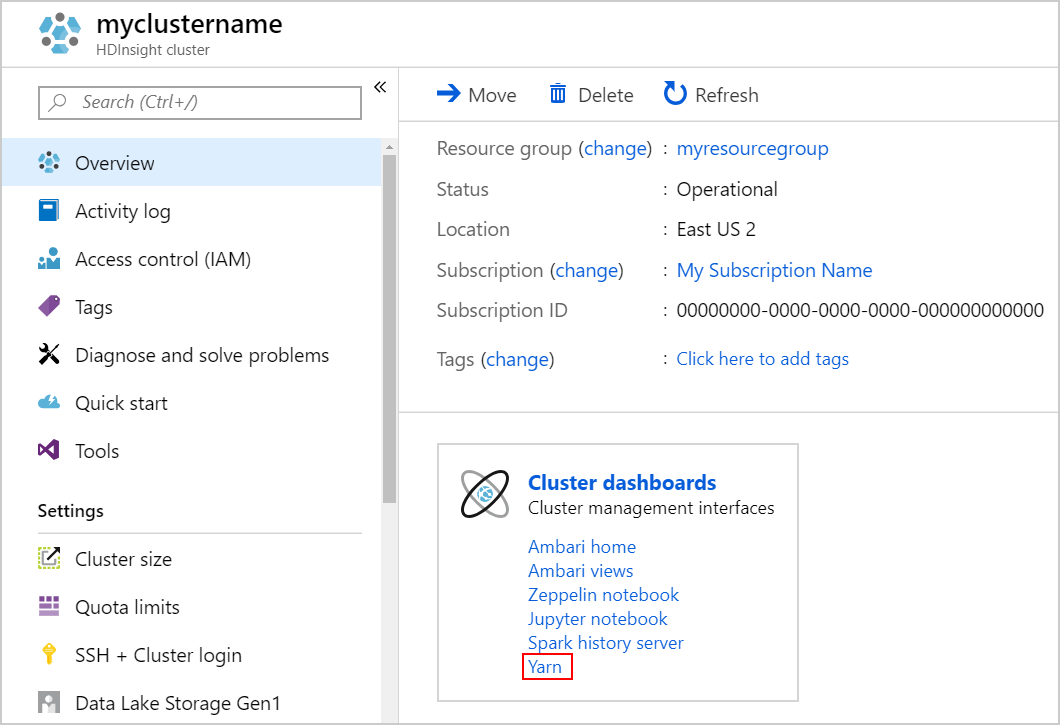
Spusťte uživatelské rozhraní YARN. V části Řídicí panely clusteru vyberte Yarn.
Tip
Případně můžete také spustit uživatelské rozhraní YARN z uživatelského rozhraní Ambari. Pokud chcete spustit uživatelské rozhraní Ambari, vyberte domovskou stránku Ambari v části Řídicí panely clusteru. V uživatelském rozhraní Ambari přejděte na rychlé odkazy> YARN>aktivní uživatelské rozhraní Resource Manageru.>
Vzhledem k tomu, že jste úlohu Spark spustili pomocí poznámkových bloků Jupyter, má aplikace název remotesparkmagics (název pro všechny aplikace spuštěné z poznámkových bloků). Pokud chcete získat další informace o úloze, vyberte ID aplikace proti názvu aplikace. Tato akce spustí zobrazení aplikace.
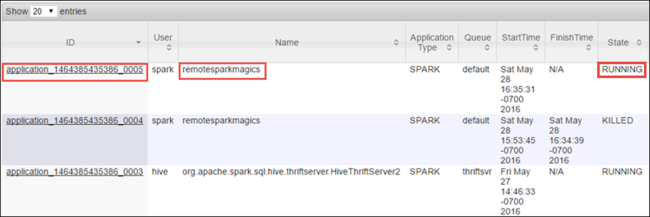
U takových aplikací, které se spouští z poznámkových bloků Jupyter, je stav vždy spuštěný , dokud poznámkový blok neukončíte.
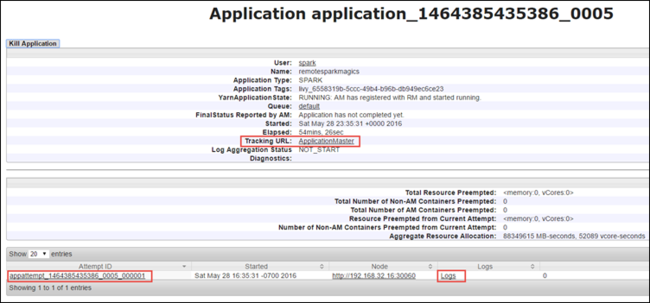
V zobrazení aplikace můžete přejít k podrobnostem a zjistit kontejnery přidružené k aplikaci a protokoly (stdout/stderr). Uživatelské rozhraní Sparku můžete spustit také kliknutím na odkaz odpovídající adrese URL sledování, jak je znázorněno níže.
Sledování aplikace v uživatelském rozhraní Sparku
V uživatelském rozhraní Sparku můžete přejít k podrobnostem úloh Sparku, které vytvořila aplikace, kterou jste spustili dříve.
Pokud chcete spustit uživatelské rozhraní Sparku, v zobrazení aplikace vyberte odkaz na adresu URL sledování, jak je znázorněno na snímku obrazovky výše. Zobrazí se všechny úlohy Sparku spuštěné aplikací spuštěnou v aplikaci Jupyter Notebook.
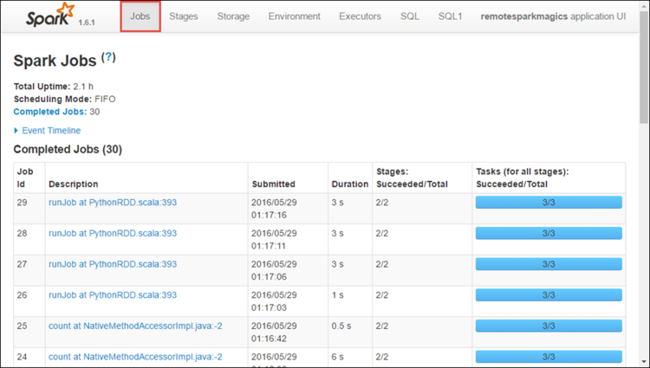
Výběrem karty Exekutory zobrazíte informace o zpracování a úložišti pro každý exekutor. Zásobník volání můžete také načíst výběrem odkazu Výpis stavu vlákna.
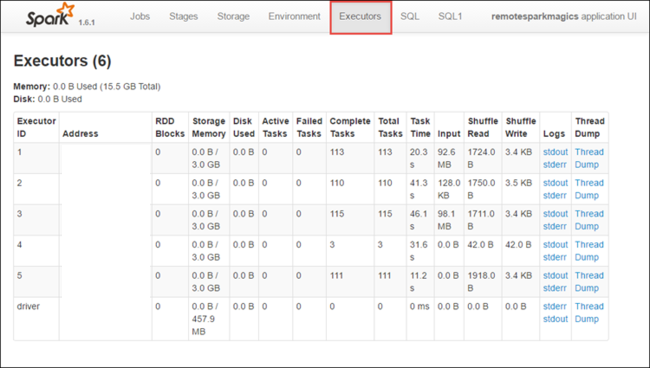
Výběrem karty Fáze zobrazíte fáze přidružené k aplikaci.

Každá fáze může mít více úkolů, pro které můžete zobrazit statistiky provádění, jak je znázorněno níže.
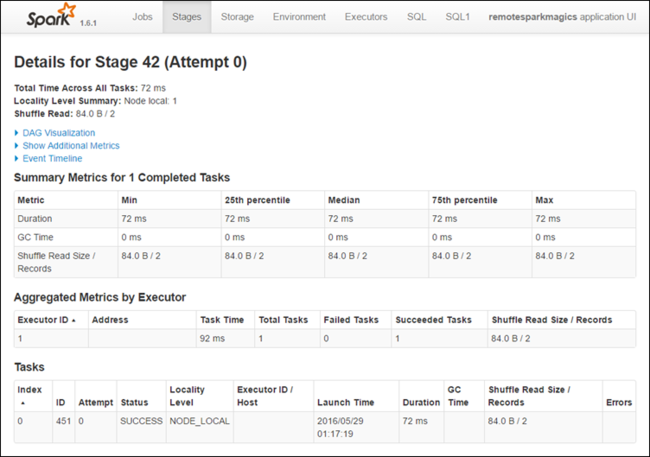
Na stránce podrobností fáze můžete spustit vizualizaci DAG. Rozbalte odkaz Vizualizace DAG v horní části stránky, jak je znázorněno níže.
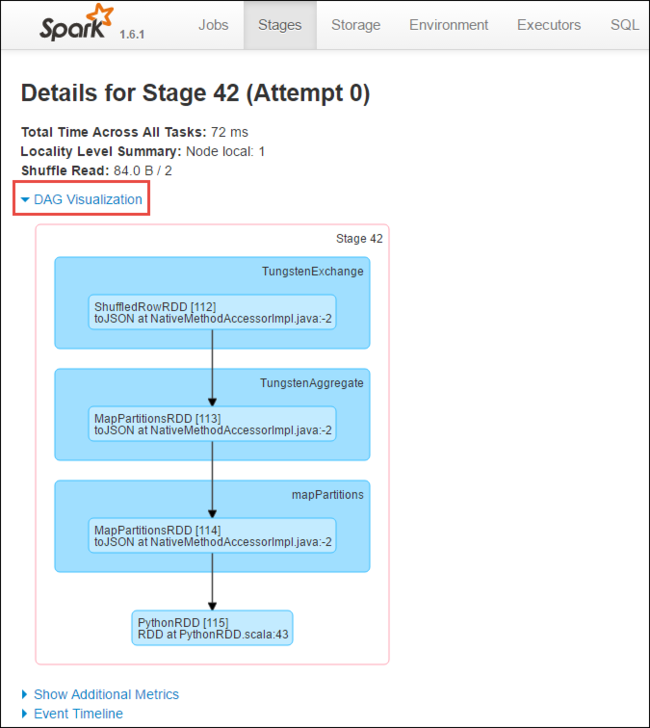
DAG nebo Direct Aclyic Graph představuje různé fáze aplikace. Každé modré pole v grafu představuje operaci Sparku vyvolanou z aplikace.
Na stránce podrobností fáze můžete také spustit zobrazení časové osy aplikace. Rozbalte odkaz časová osa události v horní části stránky, jak je znázorněno níže.
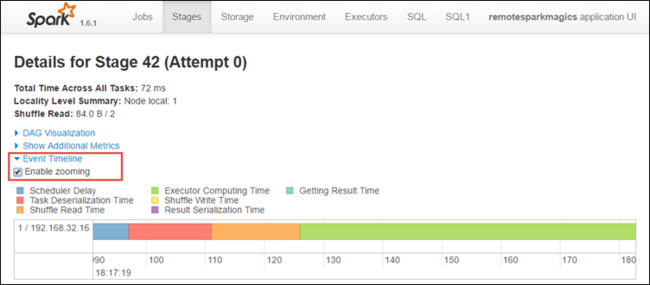
Tento obrázek zobrazuje události Sparku ve formě časové osy. Zobrazení časové osy je k dispozici na třech úrovních, napříč úlohami, v rámci úlohy a ve fázi. Výše uvedený obrázek zachycuje zobrazení časové osy pro danou fázi.
Tip
Pokud zaškrtnete políčko Povolit přiblížení , můžete se posunout doleva a doprava v zobrazení časové osy.
Další karty v uživatelském rozhraní Sparku poskytují užitečné informace o instanci Sparku.
- Karta Úložiště – Pokud vaše aplikace vytvoří SADU RDD, najdete informace na kartě Úložiště.
- Karta Prostředí – Tato karta obsahuje užitečné informace o vaší instanci Sparku, například:
- Verze Scala
- Adresář protokolu událostí přidružený ke clusteru
- Počet jader exekutoru pro aplikaci
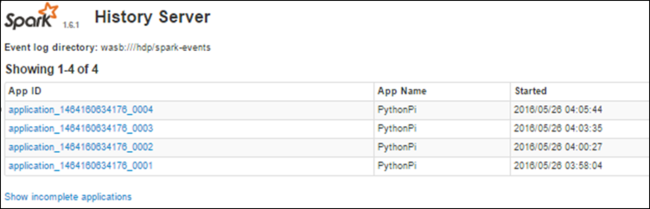
Vyhledání informací o dokončených úlohách pomocí serveru historie Sparku
Po dokončení úlohy se informace o úloze zachovají na serveru historie Sparku.
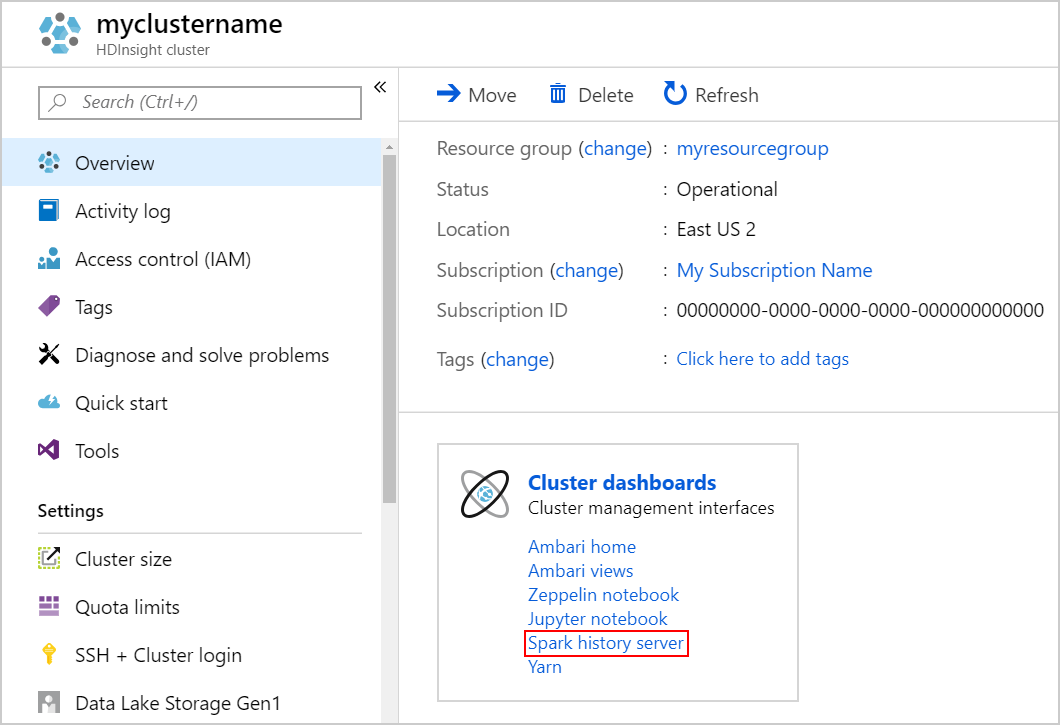
Pokud chcete spustit Server historie Sparku, vyberte na stránce Přehled server historie Sparku v části Řídicí panely clusteru.
Tip
Případně můžete také spustit uživatelské rozhraní Serveru historie Sparku z uživatelského rozhraní Ambari. Pokud chcete spustit uživatelské rozhraní Ambari, v okně Přehled vyberte domovskou stránku Ambari v části Řídicí panely clusteru. V uživatelském rozhraní Ambari přejděte do >uživatelského rozhraní serveru Historie Spark2 spark2 rychlých odkazů.>
Zobrazí se všechny dokončené aplikace uvedené v seznamu. Pokud chcete zobrazit další informace, vyberte ID aplikace.