Modul runtime Databricks pro Machine Learning
Tento článek popisuje Databricks Runtime pro Machine Learning a poskytuje pokyny k vytvoření clusteru, který ho používá.
Co je Databricks Runtime pro Machine Learning?
Databricks Runtime pro Machine Learning (Databricks Runtime ML) automatizuje vytváření clusteru s předem vytvořenou infrastrukturou strojového učení a hlubokého učení, včetně nejběžnějších knihoven ML a DL.
Knihovny zahrnuté v databricks Runtime ML
Databricks Runtime ML zahrnuje celou řadu oblíbených knihoven ML. Knihovny se aktualizují s každou verzí, aby zahrnovaly nové funkce a opravy.
Databricks určila podmnožinu podporovaných knihoven jako knihovny nejvyšší úrovně. Pro tyto knihovny poskytuje Databricks rychlejší tempo aktualizace a aktualizaci na nejnovější verze balíčků s každou verzí modulu runtime (blokování konfliktů závislostí). Databricks také poskytuje pokročilou podporu, testování a vložené optimalizace pro knihovny nejvyšší úrovně. Knihovny nejvyšší úrovně se přidávají nebo odebírají jenom s hlavními vydáními.
- Úplný seznam nejvyšších a dalších poskytovaných knihoven najdete v poznámkách k verzi pro Databricks Runtime ML.
- Informace o tom, jak často se knihovny aktualizují a kdy jsou knihovny zastaralé, najdete v tématu zásady údržby ML modulu databricks Runtime.
Můžete nainstalovat další knihovny pro vytvoření vlastního prostředí pro váš poznámkový blok nebo cluster.
- Pokud chcete zpřístupnit knihovnu pro všechny poznámkové bloky spuštěné v clusteru, vytvořte knihovnu clusteru. Inicializační skript můžete také použít k instalaci knihoven do clusterů při vytváření.
- Pokud chcete nainstalovat knihovnu, která je dostupná jenom pro konkrétní relaci poznámkového bloku, použijte knihovny Pythonu s oborem poznámkového bloku.
Nastavení výpočetních prostředků pro Databricks Runtime ML
Proces vytváření výpočetních prostředků založených na Databricks Runtime ML závisí na tom, zda je váš pracovní prostor povolen pro Public Preview cluster určené skupiny Dedicated nebo ne. Pracovní prostory, které jsou pro verzi Preview povolené, mají nové zjednodušené výpočetní uživatelské rozhraní.
Vytvoření clusteru pomocí Databricks Runtime ML
Při vytváření clusteru vyberte verzi Databricks Runtime ML z rozevírací nabídky verze Databricks Runtime . K dispozici jsou moduly runtime ML s podporou procesoru i GPU.
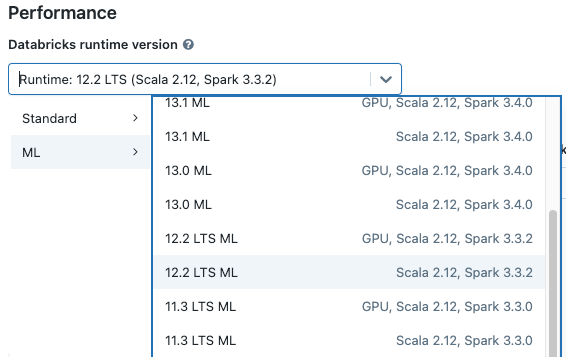
Pokud vyberete cluster z rozevírací nabídky poznámkového bloku, verze Databricks Runtime se zobrazí napravo od názvu clusteru.
Pokud vyberete modul runtime ML s podporou GPU, zobrazí se výzva k výběru kompatibilního typu ovladače a typu pracovního procesu. Nekompatibilní typy instancí se v rozevírací nabídce zobrazují šedě. Typy instancí s podporou GPU jsou uvedeny pod popiskem akcelerovaných GPU. Informace o vytváření clusterů GPU Azure Databricks najdete v tématu Výpočetní prostředky s podporou GPU. Modul Databricks Runtime ML zahrnuje ovladače hardwaru GPU a knihovny NVIDIA, jako je CUDA.
Vytvoření nového clusteru pomocí nového zjednodušeného výpočetního uživatelského rozhraní
Kroky uvedené v této části použijte pouze v případě, že váš pracovní prostor je povolen pro verzi Preview clusteru specializované skupiny.
Pokud chcete použít verzi strojového učení databricks Runtime, zaškrtněte políčko machine learning.
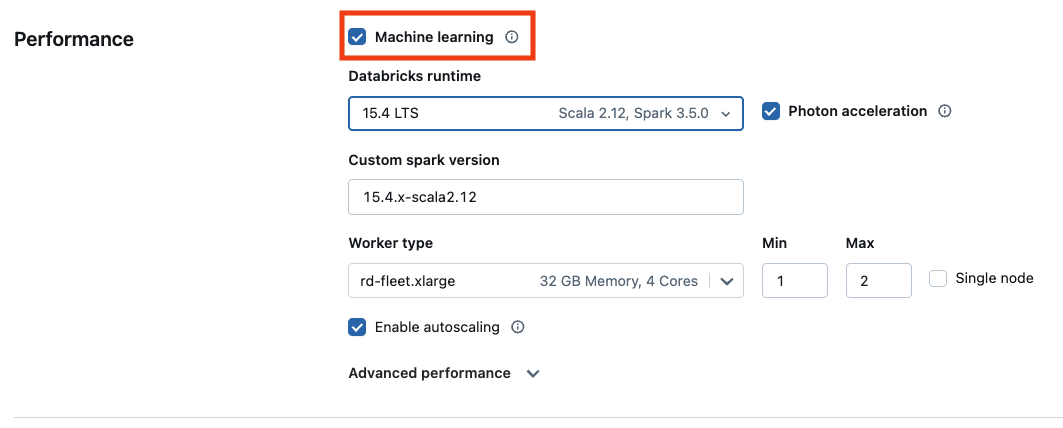
U výpočetních prostředků založených na GPU vyberte typ instance s podporou GPU. Úplný seznam podporovaných typů GPU najdete v tématu Podporované typy instancí.
Photon a Databricks Runtime ML
Když vytvoříte cluster procesoru s modulem Databricks Runtime 15.2 ML nebo novějším, můžete povolit Photon. Photon zlepšuje výkon pro aplikace využívající Spark SQL, Spark DataFrames, vytváření funkcí, GraphFrames a xgboost4j. Neočekává se, že by se zlepšil výkon aplikací využívajících sady RDD Sparku, uživatelem definované soubory Pandas a jiné jazyky než JVM, jako je Python. Balíčky Pythonu, jako jsou XGBoost, PyTorch a TensorFlow, proto neuvidí vylepšení s Photon.
Rozhraní API Spark RDD a Spark MLlib mají omezenou kompatibilitu s Photon. Při zpracování velkých datových sad pomocí sady Spark RDD nebo Spark MLlib může docházet k problémům s pamětí Sparku. Viz problémy s pamětí Sparku.
Režim přístupu pro clustery Databricks Runtime ML
Pokud chcete získat přístup k datům v katalogu Unity v clusteru s modulem Databricks Runtime ML, musíte udělat jednu z těchto věcí:
- Nastavte cluster pomocí režimu přístupu jednoho uživatele.
- Nastavte cluster pomocí režimu vyhrazeného přístupu. Režim vyhrazeného přístupu je aktuálně ve verzi Public Preview. Režim vyhrazeného přístupu poskytuje funkce režimu sdíleného přístupu v databricks Runtime ML.
Pokud má výpočetní prostředek vyhrazený přístup, může být prostředek přiřazen jednomu uživateli nebo skupině. Při přiřazení ke skupině (skupinovému clusteru) se oprávnění uživatele automaticky omezí na oprávnění skupiny, což uživateli umožní bezpečně sdílet prostředek s ostatními členy skupiny.
Při použití režimu přístupu pro jednoho uživatele jsou následující funkce k dispozici pouze ve službě Databricks Runtime 15.4 LTS ML a vyšší: