Začínáme: Vylepšení a vyčištění dat
Tento úvodní článek vás provede použitím poznámkového bloku Azure Databricks k vyčištění a vylepšení dat názvu dítěte v New Yorku, která byla dříve načtena do tabulky v katalogu Unity pomocí Pythonu, Scaly a R. V tomto článku změníte názvy sloupců, změníte velká písmena a vypište pohlaví každého jména dítěte z nezpracované tabulky dat a pak datový rámec uložíte do stříbrné tabulky. Potom vyfiltrujete data tak, aby zahrnovala pouze data pro 2021, seskupte data na úrovni stavu a pak data seřadíte podle počtu. Nakonec tento datový rámec uložíte do zlaté tabulky a vizualizujete data v pruhovém grafu. Další informace o stříbrných a zlatých tabulkách najdete v architektuře medailonu.
Důležité
Tento článek začínáme vychází z článku Začínáme: Ingestování a vkládání dalších dat. Abyste mohli tento článek dokončit, musíte dokončit kroky v tomto článku. Úplný poznámkový blok pro tento úvodní článek najdete v tématu Ingestování dalších datových poznámkových bloků.
Požadavky
K dokončení úkolů v tomto článku musíte splňovat následující požadavky:
- Váš pracovní prostor musí mít povolený katalog Unity. Informace o tom, jak začít s katalogem Unity, najdete v tématu Nastavení a správa katalogu Unity.
- Musíte mít
WRITE VOLUMEoprávnění ke svazku,USE SCHEMAoprávnění nadřazeného schématu aUSE CATALOGoprávnění nadřazeného katalogu. - Musíte mít oprávnění k používání existujícího výpočetního prostředku nebo k vytvoření nového výpočetního prostředku. Viz Začínáme s Azure Databricks nebo se obraťte na správce Databricks.
Tip
Dokončený poznámkový blok pro tento článek najdete v tématu Vyčištění a vylepšení datových poznámkových bloků.
Krok 1: Vytvoření nového poznámkového bloku
Chcete-li vytvořit poznámkový blok v pracovním prostoru, klepněte na tlačítko ![]() Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Další informace o vytváření a správě poznámkových bloků najdete v tématu Správa poznámkových bloků.
Krok 2: Definování proměnných
V tomto kroku definujete proměnné pro použití v ukázkovém poznámkovém bloku, který vytvoříte v tomto článku.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku. Nahraďte
<catalog-name>katalog,<schema-name><volume-name>schéma a názvy svazků pro svazek katalogu Unity. Volitelně nahraďtetable_namehodnotu názvem tabulky podle vašeho výběru. Data jména dítěte uložíte do této tabulky dále v tomto článku.Stisknutím spustíte
Shift+Enterbuňku a vytvoříte novou prázdnou buňku.Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
Krok 3: Načtení nezpracovaných dat do nového datového rámce
Tento krok načte nezpracovaná data dříve uložená do tabulky Delta do nového datového rámce při přípravě na čištění a vylepšení těchto dat pro další analýzu.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku.
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)Stisknutím klávesy
Shift+Enterspusťte buňku a přejděte na další buňku.
Krok 4: Vyčištění a vylepšení nezpracovaných dat a uložení
V tomto kroku změníte název Year sloupce, změníte data ve First_Name sloupci na počáteční velká písmena a aktualizujete hodnoty Sex sloupce tak, aby zobrazoval sex, a potom datový rámec uložte do nové tabulky.
Zkopírujte a vložte následující kód do prázdné buňky poznámkového bloku.
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")Stisknutím klávesy
Shift+Enterspusťte buňku a přejděte na další buňku.
Krok 5: Seskupení a vizualizace dat
V tomto kroku vyfiltrujete data jenom na rok 2021, seskupíte data podle pohlaví a jména, agregujete podle počtu a pořadí podle počtu. Datový rámec pak uložíte do tabulky a pak vizualizujete data v pruhovém grafu.
Zkopírujte a vložte následující kód do prázdné buňky poznámkového bloku.
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")Stisknutím
Ctrl+Enterspustíte buňku.-
- Vedle karty Tabulka klikněte a + potom klikněte na Vizualizace.
V editoru vizualizací klikněte na Typ vizualizace a ověřte, že je vybraný pruh .
Ve sloupci X vyberte
First_Name.Klikněte na Přidat sloupec pod sloupci Y a pak vyberte Total_Count.
Ve skupině podle vyberte Sex.
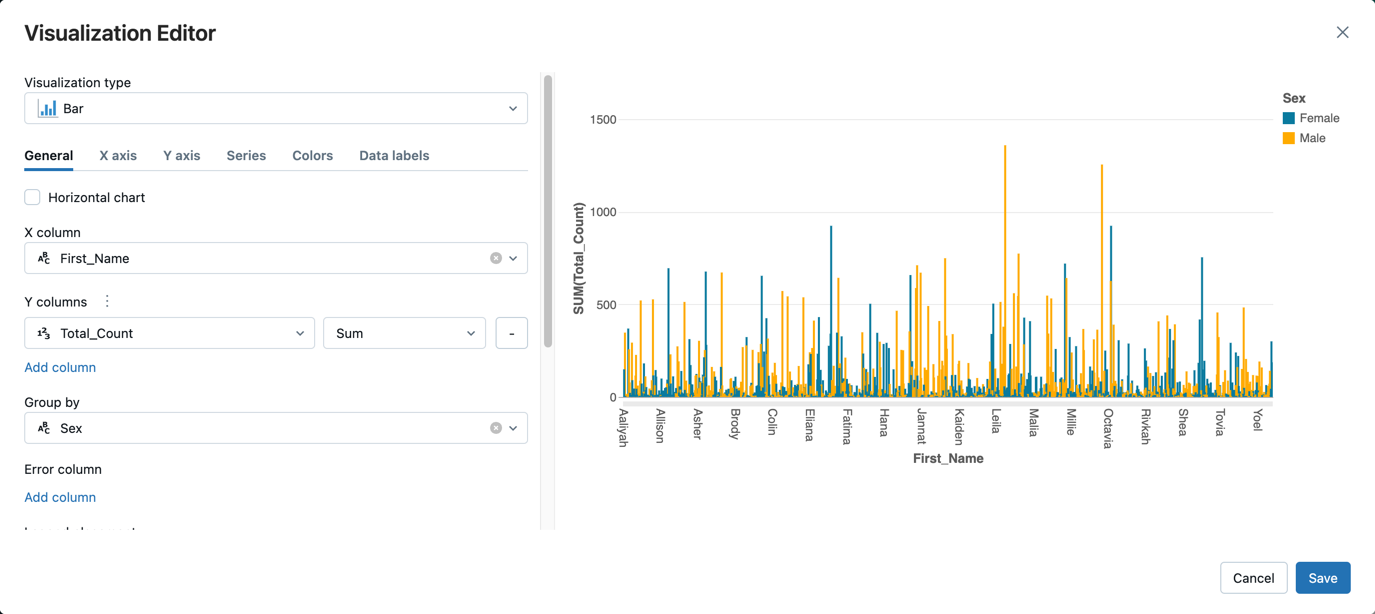
Klikněte na Uložit.
Čištění a vylepšení datových poznámkových bloků
K provedení kroků v tomto článku použijte jeden z následujících poznámkových bloků. Nahraďte <catalog-name>katalog, <schema-name><volume-name>schéma a názvy svazků pro svazek katalogu Unity. Volitelně nahraďte table_name hodnotu názvem tabulky podle vašeho výběru.