Začínáme: Import a vizualizace dat CSV z poznámkového bloku
Tento článek vás provede použitím poznámkového bloku Azure Databricks k importu dat ze souboru CSV obsahujícího data názvu dítěte z health.data.ny.gov do svazku katalogu Unity pomocí Pythonu, Scaly a R. Naučíte se také upravovat název sloupce, vizualizovat data a ukládat je do tabulky.
Požadavky
K dokončení úkolů v tomto článku musíte splňovat následující požadavky:
- Váš pracovní prostor musí mít povolené "Unity Catalog". Informace o tom, jak začít s katalogem Unity, najdete v tématu Nastavení a správa katalogu Unity.
- Pro svazek musíte mít oprávnění
WRITE VOLUME, pro nadřazené schéma oprávněníUSE SCHEMAa pro nadřazený katalog oprávněníUSE CATALOG. - Musíte mít oprávnění k používání existujícího výpočetního prostředku nebo k vytvoření nového výpočetního prostředku. Viz Začínáme s Azure Databricks nebo se obraťte na správce Databricks.
Tip
Dokončený poznámkový blok pro tento článek najdete v tématu Import a vizualizace datových poznámkových bloků.
Krok 1: Vytvoření nového poznámkového bloku
Chcete-li vytvořit poznámkový blok v pracovním prostoru, klepněte na tlačítko ![]() Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Nový na bočním panelu a potom klepněte na příkaz Poznámkový blok. V pracovním prostoru se otevře prázdný poznámkový blok.
Další informace o vytváření a správě poznámkových bloků najdete v tématu Správa poznámkových bloků.
Krok 2: Definování proměnných
V tomto kroku definujete proměnné pro použití v ukázkovém poznámkovém bloku, který vytvoříte v tomto článku.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku. Nahraďte
<catalog-name>,<schema-name>a<volume-name>názvy katalogu, schématu a svazku pro svazek Unity Catalog. Volitelně můžete hodnotutable_namenahradit názvem tabulky podle vašeho výběru. Data jména dítěte uložíte do této tabulky dále v tomto článku.Stisknutím spustíte
Shift+Enterbuňku a vytvoříte novou prázdnou buňku.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
Krok 3: Import souboru CSV
V tomto kroku naimportujete soubor CSV obsahující data názvu dítěte z health.data.ny.gov do svazku katalogu Unity.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku. Tento kód zkopíruje soubor
rows.csvze health.data.ny.gov do svazku katalogu Unity pomocí příkazu Databricks dbutuils.Stisknutím klávesy
Shift+Enterspusťte buňku a přejděte na další buňku.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
Krok 4: Načtení dat CSV do datového rámce
V tomto kroku vytvoříte datový rámec s názvem df ze souboru CSV, který jste dříve načetli do svazku katalogu Unity pomocí metody spark.read.csv.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku. Tento kód načte data názvu dítěte do datového rámce
dfze souboru CSV.Stisknutím klávesy
Shift+Enterspusťte buňku a přejděte na další buňku.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Můžete načíst data z mnoha podporovaných formátů souborů.
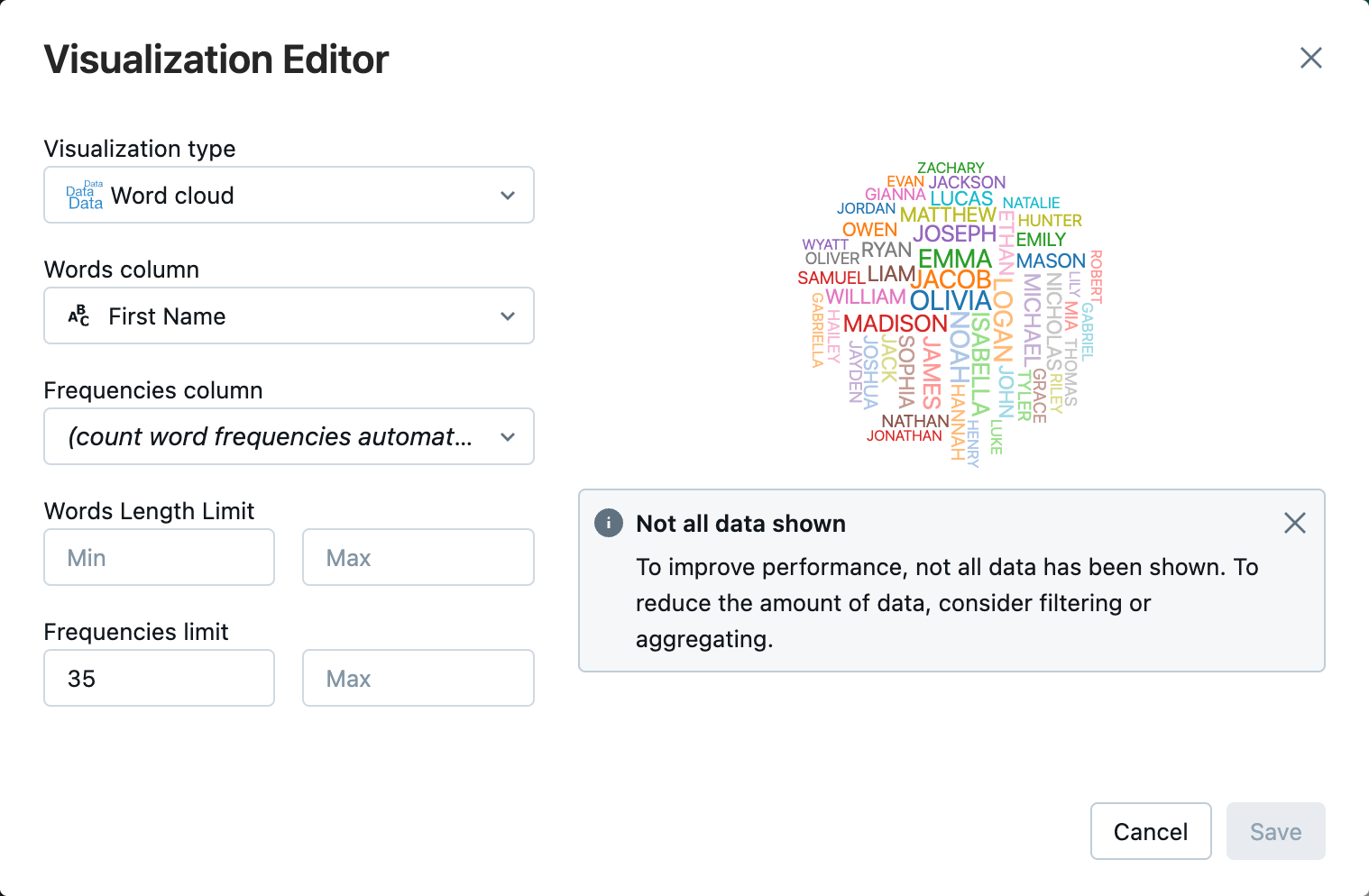
Krok 5: Vizualizace dat z poznámkového bloku
V tomto kroku použijete metodu display() k zobrazení obsahu datového rámce v tabulce v poznámkovém bloku a následné vizualizaci dat ve wordovém cloudovém grafu v poznámkovém bloku.
Zkopírujte a vložte následující kód do nové prázdné buňky poznámkového bloku a potom kliknutím na Spustit buňku zobrazte data v tabulce.
Python
display(df)Scala
display(df)R
display(df)Zkontrolujte výsledky v tabulce.
Vedle záložky Tabulka klikněte na + a poté na Vizualizace.
V editoru vizualizací klikněte na Typ vizualizace a ověřte, že je vybraný wordový cloud .
Ve sloupci Slovaověřte, že je vybráno
First Name.V omezení frekvencíklepněte na tlačítko
35.
Klikněte na Uložit.
Krok 6: Uložení datového rámce do tabulky
Důležité
Pokud chcete datový rámec uložit v katalogu Unity, musíte mít oprávnění tabulky CREATE pro katalog a schéma. Informace o oprávněních v katalogu Unity naleznete v tématu Oprávnění a zabezpečitelné objekty v katalogu Unity a Spravovat oprávnění v katalogu Unity.
Zkopírujte a vložte následující kód do prázdné buňky poznámkového bloku. Tento kód nahradí mezeru v názvu sloupce. speciální znaky, například mezery nejsou povoleny v názvech sloupců. Tento kód používá metodu Apache Spark
withColumnRenamed().Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Zkopírujte a vložte následující kód do prázdné buňky poznámkového bloku. Tento kód uloží obsah datového rámce do tabulky v katalogu Unity pomocí proměnné názvu tabulky, kterou jste definovali na začátku tohoto článku.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Chcete-li ověřit, zda byla tabulka uložena, kliknutím na Katalog na levém bočním panelu otevřete uživatelské rozhraní Průzkumníka katalogu. Otevřete katalog a pak schéma, abyste ověřili, že se zobrazí tabulka.
Klikněte na svou tabulku pro zobrazení schématu tabulky na kartě Přehled.
Kliknutím na Ukázková data zobrazíte 100 řádků dat z tabulky.
Import a vizualizace datových poznámkových bloků
K provedení kroků v tomto článku použijte jeden z následujících poznámkových bloků. Nahraďte <catalog-name>, <schema-name>a <volume-name> názvy katalogu, schématu a svazku pro svazek Unity Catalog. Volitelně můžete hodnotu table_name nahradit názvem tabulky podle vašeho výběru.
Python
Import dat ze souboru CSV pomocí Pythonu
Získání poznámkového bloku
Scala
Import dat ze souboru CSV pomocí scaly
Získání poznámkového bloku
R
Import dat ze souboru CSV pomocí R
Získání poznámkového bloku
Další kroky
- Další informace o přidání dalších dat do existující tabulky ze souboru CSV najdete v tématu Začínáme: Ingestování a vložení dalších dat.
- Další informace o čištění a vylepšení dat najdete v tématu Začínáme: Vylepšení a čištění dat.