Jaká je architektura jezera v medailiónu?
Architektura medailonu popisuje řadu datových vrstev, které označují kvalitu dat uložených v jezeře. Azure Databricks doporučuje použít vícevrstvý přístup k vytvoření jediného zdroje pravdivých informací pro podnikové datové produkty.
Tato architektura zaručuje atomicitu, konzistenci, izolaci a odolnost při průchodu dat několika vrstvami ověření a transformací před uložením v rozložení optimalizovaném pro efektivní analýzu. Termíny bronzová (nezpracovaná), stříbro (ověřeno) a zlato (obohacené) popisují kvalitu dat v každé z těchto vrstev.
Architektura Medallion jako vzor návrhu dat
Architektura medailonu je vzor návrhu dat používaný k logickému uspořádání dat. Jejím cílem je přírůstkově a postupně zlepšovat strukturu a kvalitu dat při průchodu každou vrstvou architektury (od vrstev Bronz ⇒ Stříbro ⇒ Zlato). Architektury medallionu se někdy označují také jako architektury s více segmenty směrování.
Díky postupu dat v těchto vrstvách můžou organizace přírůstkově zlepšit kvalitu a spolehlivost dat, což je vhodnější pro aplikace business intelligence a strojového učení.
Po architektuře medailonu se doporučuje osvědčený postup, ale není to požadavek.
| Otázka | Bronzový | Silver | Gold |
|---|---|---|---|
| Co se stane v této vrstvě? | Příjem nezpracovaných dat | Čištění a ověřování dat | Dimenzionální modelování a agregace |
| Kdo je zamýšlený uživatel? | - Datoví inženýři - Operace s daty – Týmy pro dodržování předpisů a audit |
- Datoví inženýři - Datoví analytici (používají silverovou vrstvu pro upřesňující datovou sadu, která stále uchovává podrobné informace nezbytné pro hloubkovou analýzu). – Datoví vědci (vytváření modelů a provádění pokročilých analýz) |
- Obchodní analytici a vývojáři BI – Datoví vědci a technici strojového učení (ML) - Vedoucí pracovníci a pracovníci s rozhodovací pravomocí - Provozní týmy |
Příklad architektury medailiónu
Tento příklad architektury medailonu ukazuje bronzovou, stříbrnou a zlatou vrstvu pro použití obchodním provozním týmem. Každá vrstva je uložena v jiném schématu katalogu operací.
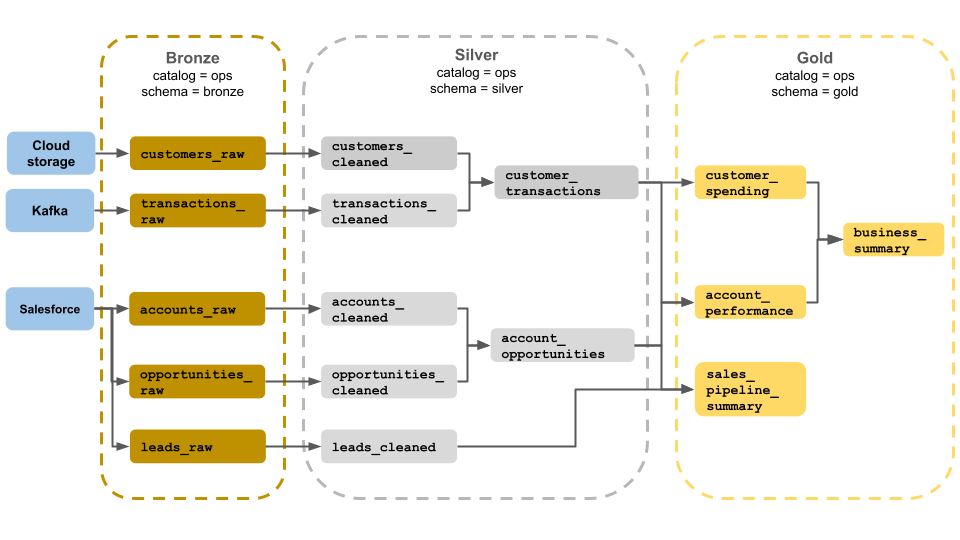
-
Bronzová vrstva (
ops.bronze): Ingestuje nezpracovaná data z cloudového úložiště, Kafka a Salesforce. Tady se neprovádí žádné vyčištění nebo ověření dat. -
Stříbrná vrstva (
ops.silver): Vyčištění a ověření dat se provádí v této vrstvě.- Data o zákaznících a transakcích se vyčistí vyřazením hodnot null a kvazováním neplatných záznamů. Tyto datové sady jsou spojené s novou datovou sadou s názvem
customer_transactions. Datoví vědci můžou tuto datovou sadu použít k prediktivní analýze. - Podobně se účty a datové sady příležitostí ze Salesforce připojují k vytvoření
account_opportunities, což je rozšířené o informace o účtu. - Data
leads_rawse vyčistí v datové sadě s názvemleads_cleaned.
- Data o zákaznících a transakcích se vyčistí vyřazením hodnot null a kvazováním neplatných záznamů. Tyto datové sady jsou spojené s novou datovou sadou s názvem
-
Zlatá vrstva (
ops.gold): Tato vrstva je určená pro firemní uživatele. Obsahuje méně datových sad než stříbro a zlato.-
customer_spending: Průměrné a celkové útraty pro každého zákazníka. -
account_performance: Denní výkon pro každý účet. -
sales_pipeline_summary: Informace o kompletním prodejním kanálu. -
business_summary: Vysoce agregované informace pro vedoucí pracovníky.
-
Příjem nezpracovaných dat do bronzové vrstvy
Bronzová vrstva obsahuje nezpracovaná a neaktuální data. Data přijatá v bronzové vrstvě mají obvykle následující vlastnosti:
- Obsahuje a udržuje nezpracovaný stav zdroje dat v původních formátech.
- Připojuje se přírůstkově a postupně roste.
- Je určena pro úlohy, které obohacují data pro stříbrné tabulky, nikoli pro přístup datových analytiků a vědců.
- Slouží jako jediný zdroj pravdy a zachovává věrnost dat.
- Umožňuje opětovné zpracování a auditování tím, že uchovává všechna historická data.
- Může to být libovolná kombinace streamovaných a dávkových transakcí ze zdrojů, včetně cloudového úložiště objektů (například S3, GCS, ADLS), sběrnic zpráv (například Kafka, Kinesis atd.) a federovaných systémů (například Lakehouse Federation).
Omezení vyčištění nebo ověření dat
V bronzové vrstvě se provádí minimální ověření dat. Aby se zajistilo proti ztrátě dat, Azure Databricks doporučuje ukládat většinu polí jako řetězec, VARIANT nebo binární, aby se chránilo před neočekávanými změnami schématu. Sloupce metadat mohou být přidány, například provenience nebo zdroj dat (například _metadata.file_name ).
Ověření a odstranění duplicitních dat ve stříbrné vrstvě
Čištění a ověřování dat se provádí ve vrstvě silver.
Vytvořte stříbrné stoly z bronzové vrstvy
Pokud chcete vytvořit stříbrnou vrstvu, načtěte data z jedné nebo více bronzových nebo stříbrných tabulek a zapište data do stříbrných tabulek.
Azure Databricks nedoporučuje ukládat data do stříbrných tabulek přímo z ingestování. Pokud píšete přímo z příjmu dat, dojde k selháním kvůli změnám schématu nebo poškozeným záznamům ve zdrojích dat. Za předpokladu, že všechny zdroje jsou jen pro připojení, nakonfigurujte většinu čtení z bronzu jako streamované čtení. Dávkové čtení by mělo být vyhrazeno pro malé datové sady (například malé dimenzionální tabulky).
Stříbrná vrstva představuje ověřené, vyčištěné a rozšířené verze dat. Stříbrná vrstva:
- Měl by vždy obsahovat alespoň jednu ověřenou, neagregovanou reprezentaci každého záznamu. Pokud agregační reprezentace řídí mnoho podřízených úloh, můžou být tyto reprezentace ve stříbrné vrstvě, ale obvykle jsou ve zlaté vrstvě.
- Je místo, kde provádíte čištění dat, odstranění duplicitních dat a normalizaci.
- Vylepšuje kvalitu dat tím, že opraví chyby a nekonzistence.
- Strukturuje data do spotřebního formátu pro zpracování po směru zpracování.
Vynucení kvality dat
Ve stříbrných tabulkách se provádějí následující operace:
- Vynucení schématu
- Zpracování hodnot null a chybějících hodnot
- Odstranění duplicitních dat
- Řešení problémů se zastaralými a pozdními příchozími daty
- Kontroly a vynucování kvality dat
- Vývoj schématu
- Přetypování typů
- Spojení
Zahájení modelování dat
Je běžné začít provádět modelování dat ve stříbrné vrstvě, včetně výběru způsobu, jak znázorňovat silně vnořená nebo částečně strukturovaná data:
- Použijte
VARIANTdatový typ. - Použijte
JSONřetězce. - Vytváření struktur, map a polí
- Zploštit schéma nebo normalizovat data do více tabulek.
Power analytics with the gold layer
Zlatá vrstva představuje vysoce upřesňující zobrazení dat, která řídí podřízené analýzy, řídicí panely, ML a aplikace. Data ve zlaté vrstvě jsou často vysoce agregovaná a filtrovaná pro konkrétní časová období nebo geografické oblasti. Obsahuje séanticky smysluplné datové sady, které se mapují na obchodní funkce a potřeby.
Zlatá vrstva:
- Skládá se z agregovaných dat přizpůsobených pro analýzy a vytváření sestav.
- Odpovídá obchodní logice a požadavkům.
- Je optimalizovaná pro výkon dotazů a řídicích panelů.
Sladění s obchodní logikou a požadavky
Ve zlaté vrstvě budete modelovat data pro vytváření sestav a analýzy pomocí dimenzionálního modelu navazováním relací a definováním měr. Analytici s přístupem k datům ve zlatě by měli být schopni najít data specifická pro doménu a odpovídat na otázky.
Vzhledem k tomu, že zlaté vrstvy modeluje obchodní doménu, někteří zákazníci vytvářejí několik vrstev gold, aby splňovali různé obchodní potřeby, jako jsou personální, finanční a IT.
Vytváření agregací přizpůsobených pro analýzy a vytváření sestav
Organizace často potřebují vytvářet agregační funkce pro míry, jako jsou průměry, počty, maximum a minimum. Pokud například vaše firma potřebuje odpovědět na otázky týkající se celkového týdenního prodeje, můžete vytvořit materializované zobrazení s názvem weekly_sales, které tato data předem odděluje, aby analytici a ostatní nemuseli znovu vytvářet často použitá materializovaná zobrazení.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimalizace výkonu v dotazech a řídicích panelech
Optimalizace tabulek zlaté vrstvy pro zajištění výkonu je osvědčeným postupem, protože tyto datové sady se často dotazují. Velké objemy historických dat jsou obvykle přístupné ve vrstvě sliver a nejsou materializovány ve zlaté vrstvě.
Řízení nákladů úpravou frekvence příjmu dat
Řízení nákladů určením četnosti příjmu dat
| Frekvence příjmu dat | Náklady | Latence | Deklarativní příklady | Procedurální příklady |
|---|---|---|---|---|
| Průběžný přírůstkový příjem dat | Vyšší | Lower | – Streamovací tabulka využívající spark.readStream k příjmu dat z cloudového úložiště či sběrnice zpráv.– Kanál Delta Live Tables, který aktualizuje tuto streamovací tabulku, běží nepřetržitě. – Kód pro strukturované streamování pomocí spark.readStream v poznámkovém bloku k příjmu dat z cloudového úložiště nebo sběrnice zpráv do tabulky Delta.– Poznámkový blok se orchestruje pomocí úlohy Azure Databricks s triggerem průběžné úlohy. |
|
| Aktivovaný přírůstkový příjem dat | Lower | Vyšší | - Příjem streamovaných tabulek z cloudového úložiště nebo sběrnice zpráv pomocí spark.readStream.– Potrubí, které aktualizuje tuto streamovací tabulku, je spuštěno naplánovanou aktivační událostí úlohy nebo spuštěním při příchodu souboru. – Kód strukturovaného streamování v poznámkovém bloku s triggerem Trigger.Available– Tento poznámkový blok se aktivuje naplánovaným triggerem úlohy nebo triggerem přijetí souboru. |
|
| Dávkové příjem dat s ručním přírůstkovým příjmem dat | Lower | Nejvyšší kvůli občasným spuštěním. | - Načítání streamovací tabulky z cloudového úložiště pomocí spark.read.– Nepoužívá strukturované streamování. Místo toho použijte primitivy, jako je přepsání oddílu, k aktualizaci celého oddílu najednou. – Vyžaduje rozsáhlou upstreamovou architekturu k nastavení přírůstkového zpracování, což umožňuje náklady podobné čtení a zápisům strukturovaného streamování. – Vyžaduje také dělení zdrojových dat podle pole datetime a následné zpracování všech záznamů z daného oddílu do cíle. |