Transformace vyhledávání v mapování toku dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Pomocí transformace vyhledávání můžete odkazovat na data z jiného zdroje v datovém toku dat. Transformace vyhledávání připojí sloupce z odpovídajících dat ke zdrojovým datům.
Transformace vyhledávání je podobná levému vnějšímu spojení. Všechny řádky z primárního datového proudu budou existovat ve výstupním datovém proudu s dalšími sloupci z vyhledávacího datového proudu.
Konfigurace
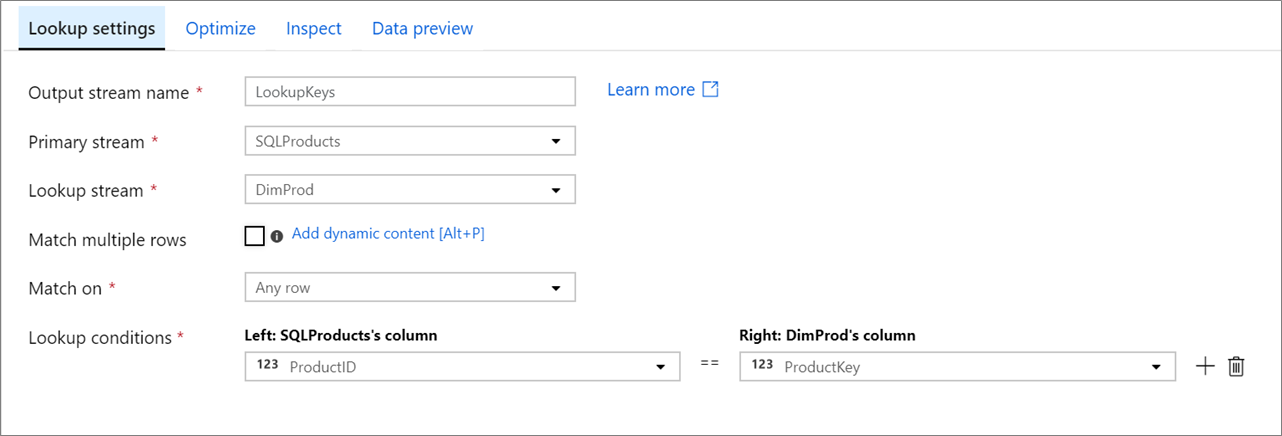
Primární datový proud: Příchozí datový proud dat. Tento datový proud odpovídá levé straně spojení.
Vyhledávací datový proud: Data, která jsou připojena k primárnímu datovému proudu. Která data se přidají, určují podmínky vyhledávání. Tento datový proud odpovídá pravé straně spojení.
Shoda s více řádky: Pokud je tato možnost povolená, vrátí řádek s více shodami v primárním datovém proudu více řádků. V opačném případě se vrátí pouze jeden řádek na základě podmínky Shoda pro.
Shoda zapnutá: Je viditelná pouze v případě, že není vybrána možnost Shoda s více řádky. Zvolte, jestli se má shoda shodovat na libovolném řádku, první shoda nebo poslední shoda. Každý řádek se doporučuje, protože se provádí nejrychleji. Pokud je vybraný první řádek nebo poslední řádek, budete muset zadat podmínky řazení.
Podmínky vyhledávání: Vyberte sloupce, které se mají shodovat. Pokud je splněna podmínka rovnosti, řádky se považují za shodu. Najetím myší a výběrem počítaného sloupce extrahujte hodnotu pomocí jazyka výrazu toku dat.
Do výstupních dat jsou zahrnuty všechny sloupce z obou datových proudů. Pokud chcete odstranit duplicitní nebo nežádoucí sloupce, přidejte po transformaci vyhledávání výběrovou transformaci . Sloupce lze také v transformaci jímky vynechat nebo přejmenovat.
Spojení bez koňovitých
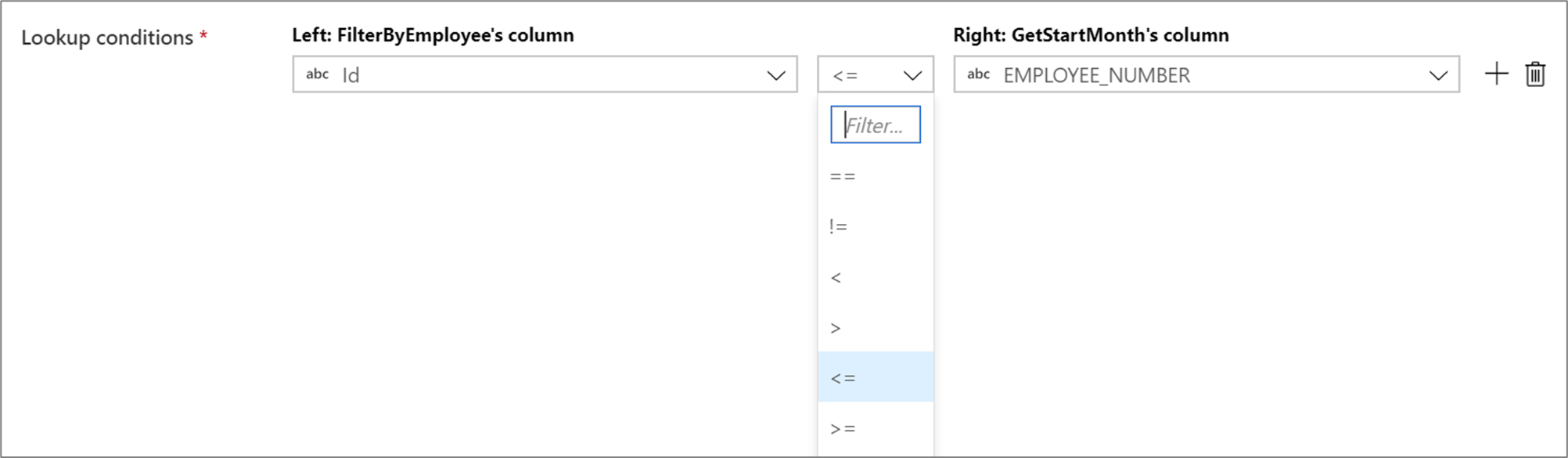
Pokud chcete ve vyhledávacích podmínkách použít podmíněný operátor, například nerovná se (!=) nebo větší než (>), změňte rozevírací seznam operátoru mezi těmito dvěma sloupci. Spojení bez koňovitých vyžadují, aby se alespoň jeden ze dvou datových proudů vysílal pomocí pevného vysílání na kartě Optimalizace.
Analýza odpovídajících řádků
Po transformaci vyhledávání můžete pomocí funkce isMatch() zjistit, jestli se vyhledávání shoduje s jednotlivými řádky.
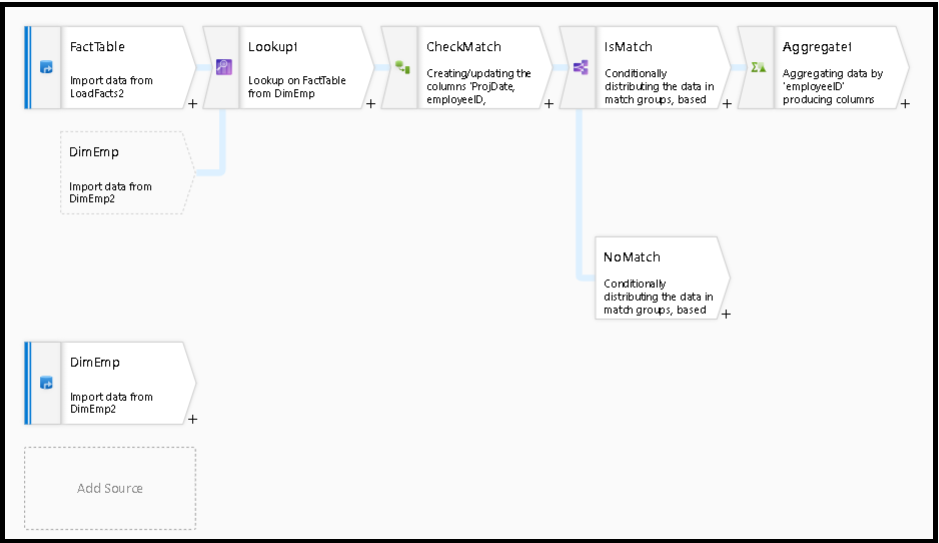
Příkladem tohoto modelu je použití podmíněné transformace rozdělení k rozdělení funkce isMatch() . V předchozím příkladu procházejí odpovídající řádky horním streamem a neodpovídající řádky procházejí proudem.NoMatch
Testování podmínek vyhledávání
Při testování transformace vyhledávání pomocí náhledu dat v režimu ladění použijte malou sadu známých dat. Při vzorkování řádků z velké datové sady nemůžete předpovědět, které řádky a klíče se budou číst pro účely testování. Výsledek není deterministický, což znamená, že podmínky spojení nemusí vracet žádné shody.
Optimalizace vysílání
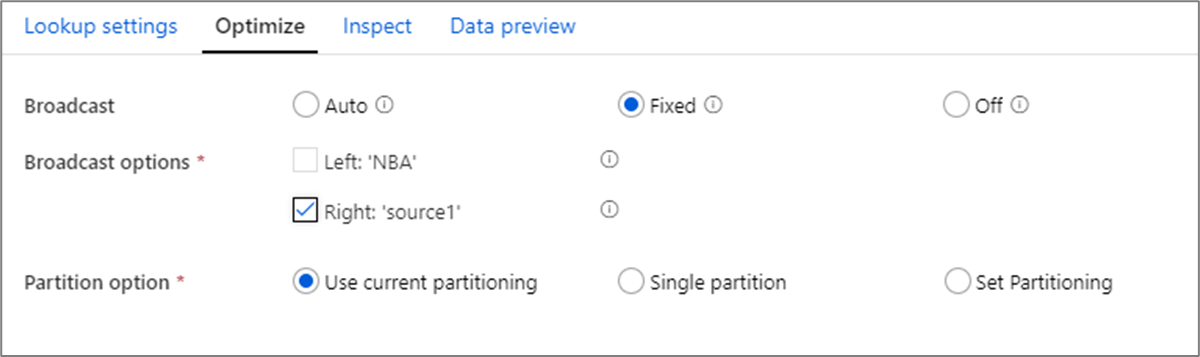
Ve spojeních vyhledávání a existuje transformace, pokud se jeden nebo oba datové proudy vejdou do paměti pracovních uzlů, můžete optimalizovat výkon povolením broadcastingu. Ve výchozím nastavení se modul Spark automaticky rozhodne, jestli se má vysílat jedna strana. Pokud chcete ručně zvolit, která strana se má vysílat, vyberte Opraveno.
Nedoporučuje se zakázat vysílání prostřednictvím možnosti Vypnuto , pokud u spojení neběží chyby časového limitu.
Vyhledávání v mezipaměti
Pokud ve stejném zdroji provádíte více menších vyhledávání, může být vhodnější než transformace vyhledávání v mezipaměti jímky a vyhledávání. Běžné příklady, kdy může být lepší najít maximální hodnotu úložiště dat a odpovídající kódy chyb databáze s chybovou zprávou. Další informace o jímkách mezipaměti a vyhledáváních uložených v mezipaměti.
Skript toku dat
Syntaxe
<leftStream>, <rightStream>
lookup(
<lookupConditionExpression>,
multiple: { true | false },
pickup: { 'first' | 'last' | 'any' }, ## Only required if false is selected for multiple
{ desc | asc }( <sortColumn>, { true | false }), ## Only required if 'first' or 'last' is selected. true/false determines whether to put nulls first
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <lookupTransformationName>
Příklad
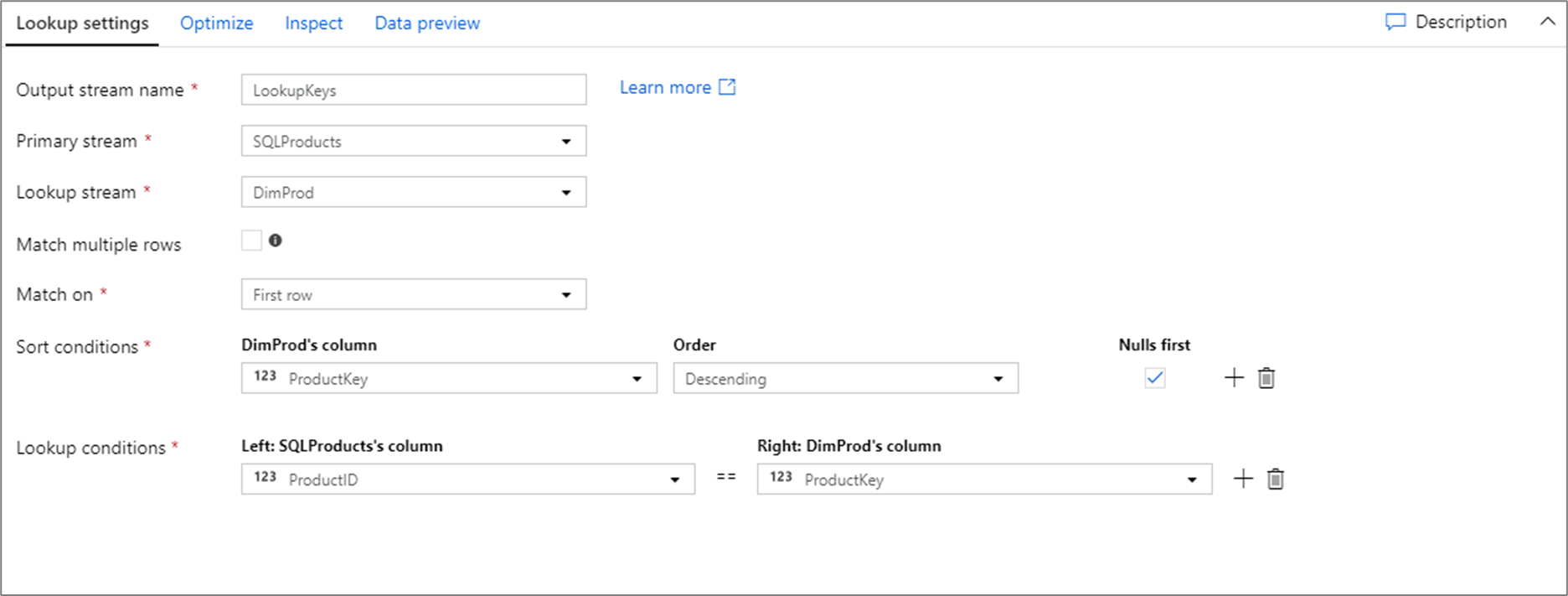
Skript toku dat pro výše uvedenou konfiguraci vyhledávání je v následujícím fragmentu kódu.
SQLProducts, DimProd lookup(ProductID == ProductKey,
multiple: false,
pickup: 'first',
asc(ProductKey, true),
broadcast: 'auto')~> LookupKeys
Související obsah
- Spojení a existuje transformace, které přebírají vstupy více datových proudů
- Použití podmíněné transformace rozdělení s rozdělením
isMatch()řádků na odpovídající a neodpovídající hodnoty