Existuje transformace v mapování toku dat.
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Existuje transformace je transformace filtrování řádků, která kontroluje, jestli data existují v jiném zdroji nebo datovém proudu. Výstupní datový proud obsahuje všechny řádky v levém datovém proudu, které existují nebo neexistují ve správném datovém proudu. Existuje transformace je podobná SQL WHERE EXISTS SQL WHERE NOT EXISTSa .
Konfigurace
- V rozevíracím seznamu Pravý datový proud vyberte, který datový proud kontrolujete.
- Určete, jestli hledáte data, která mají existovat, nebo neexistují v nastavení Typ existence.
- Vyberte, jestli chcete vlastní výraz nebo ne.
- Vyberte, které klíčové sloupce chcete porovnat, protože existují podmínky. Ve výchozím nastavení tok dat hledá rovnost mezi jedním sloupcem v každém datovém proudu. Pokud chcete porovnat vypočítanou hodnotu, najeďte myší na rozevírací seznam sloupce a vyberte Vypočítaný sloupec.
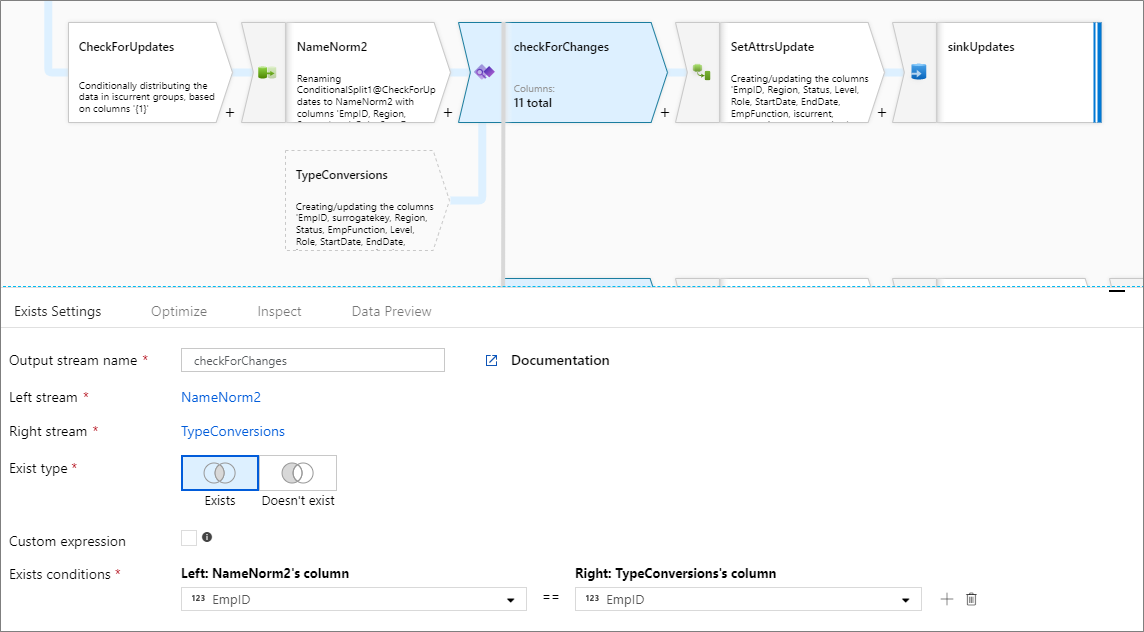
Více podmínek existuje.
Pokud chcete porovnat více sloupců z každého datového proudu, přidejte novou podmínku tak, že kliknete na ikonu plus vedle existujícího řádku. Každá další podmínka je spojená příkazem "and". Porovnání dvou sloupců je stejné jako následující výraz:
source1@column1 == source2@column1 && source1@column2 == source2@column2
Vlastní výraz
Pokud chcete vytvořit výraz volného formuláře, který obsahuje jiné operátory než "and" a "rovná se", vyberte pole Vlastní výraz . Kliknutím na modré pole zadejte vlastní výraz prostřednictvím tvůrce výrazů toku dat.
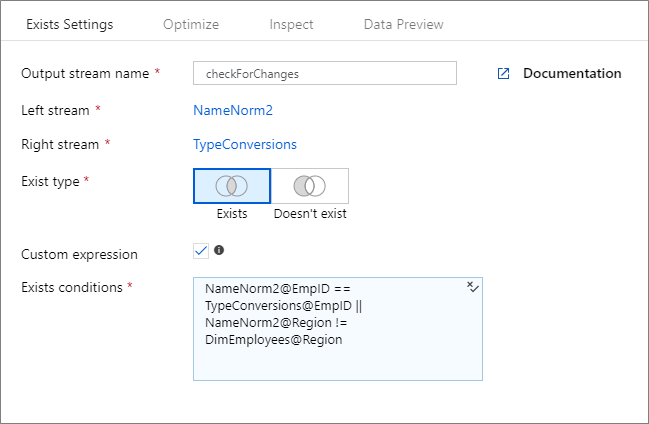
Pokud vytváříte dynamické vzory v tocích dat pomocí "pozdní vazby" sloupců prostřednictvím posunu schématu, můžete pomocí byName() funkce výrazu použít existující transformaci bez pevného kódování (tj. počáteční vazby) názvů sloupců. Příklad: toString(byName('ProductNumber','source1')) == toString(byName('ProductNumber','source2'))
Optimalizace vysílání
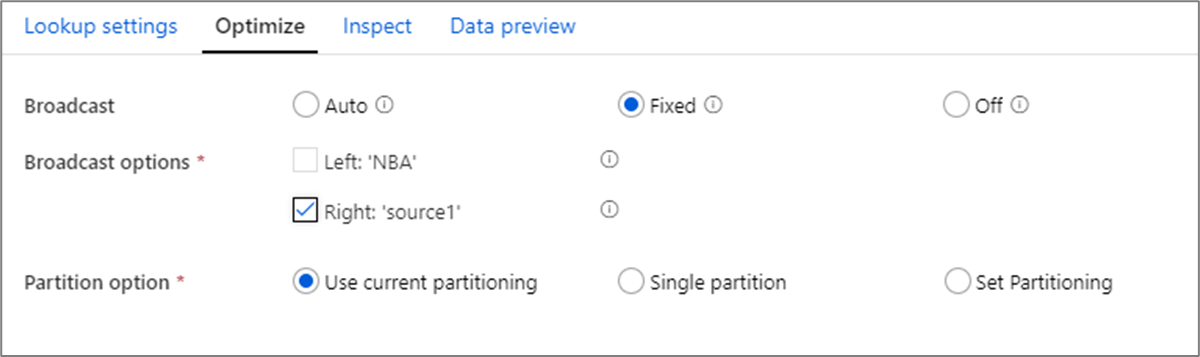
Ve spojeních vyhledávání a existuje transformace, pokud se jeden nebo oba datové proudy vejdou do paměti pracovních uzlů, můžete optimalizovat výkon povolením broadcastingu. Ve výchozím nastavení se modul Spark automaticky rozhodne, jestli se má vysílat jedna strana. Pokud chcete ručně zvolit, která strana se má vysílat, vyberte Opraveno.
Nedoporučuje se zakázat vysílání prostřednictvím možnosti Vypnuto , pokud u spojení neběží chyby časového limitu.
Skript toku dat
Syntaxe
<leftStream>, <rightStream>
exists(
<conditionalExpression>,
negate: { true | false },
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <existsTransformationName>
Příklad
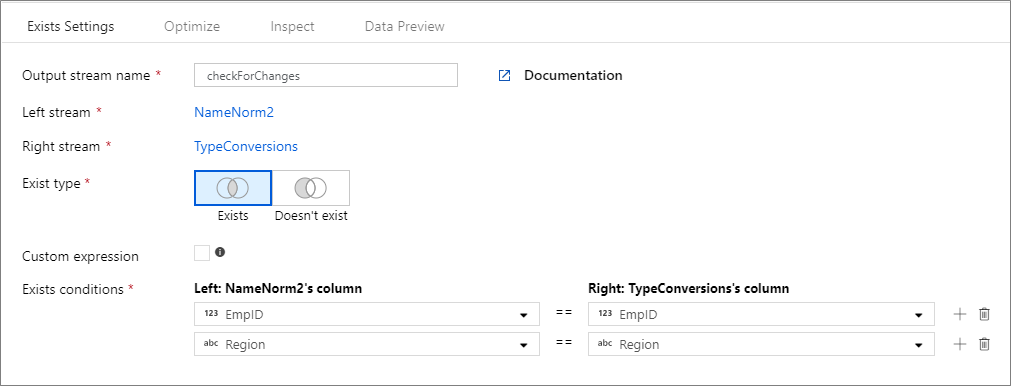
Následující příklad je transformace s názvem checkForChanges , která přebírá levý stream NameNorm2 a pravý datový proud TypeConversions. Podmínka existuje je výraz NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region , který vrátí hodnotu true, pokud EMPID Region se oba sloupce v jednotlivých datových proudech shoduje. Když kontrolujeme existenci, negate je nepravda. Nepovolujeme žádné vysílání na kartě optimalizace, takže broadcast má hodnotu 'none'.
V uživatelském rozhraní vypadá tato transformace jako na následujícím obrázku:
Skript toku dat pro tuto transformaci je v následujícím fragmentu kódu:
NameNorm2, TypeConversions
exists(
NameNorm2@EmpID == TypeConversions@EmpID && NameNorm2@Region == DimEmployees@Region,
negate:false,
broadcast: 'auto'
) ~> checkForChanges