Podmíněná transformace rozdělení v mapování toku dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Podmíněná transformace rozdělení směruje datové řádky do různých datových proudů na základě odpovídajících podmínek. Podmíněná transformace rozdělení se podobá rozhodovací struktuře CASE v programovacím jazyce. Transformace vyhodnocuje výrazy a na základě výsledků směruje řádek dat na zadaný datový proud.
Konfigurace
Nastavení Rozdělení určuje , jestli řádek toků dat do prvního odpovídajícího datového proudu nebo každého datového proudu, se kterým odpovídá.
Pomocí tvůrce výrazů toku dat zadejte výraz pro podmínku rozdělení. Pokud chcete přidat novou podmínku, klikněte na ikonu plus v existujícím řádku. Výchozí datový proud je možné přidat i pro řádky, které neodpovídají žádné podmínce.
Skript toku dat
Syntaxe
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Příklad
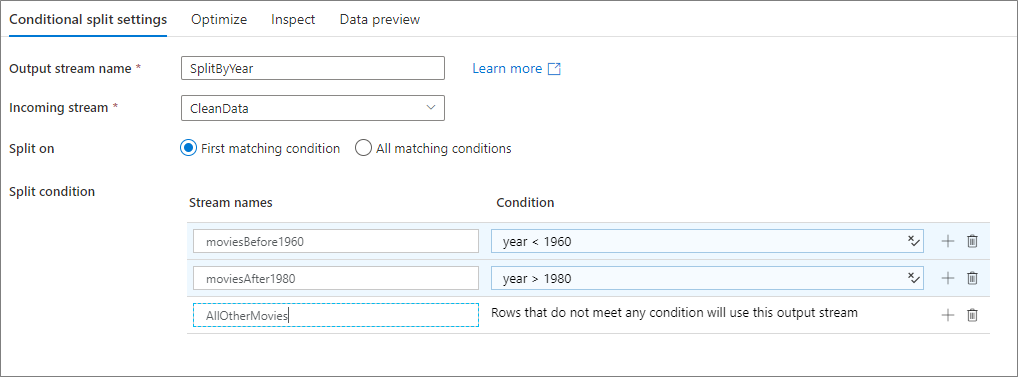
Následující příklad je podmíněná rozdělená transformace s názvem SplitByYear , která přebírá příchozí datový proud CleanData. Tato transformace má dvě rozdělené podmínky year < 1960 a year > 1980. disjoint je false, protože data přejdou na první odpovídající podmínku, nikoli na všechny odpovídající podmínky. Každý řádek odpovídající první podmínce přejde do výstupního datového proudu moviesBefore1960. Všechny zbývající řádky odpovídající druhé podmínce se přejdou do výstupního datového proudu moviesAFter1980. Všechny ostatní řádky procházejí výchozím datovým proudem AllOtherMovies.
V uživatelském rozhraní služby vypadá tato transformace jako na následujícím obrázku:
Skript toku dat pro tuto transformaci je v následujícím fragmentu kódu:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Související obsah
Běžné transformace toku dat používané s podmíněným rozdělením jsou transformace spojení, vyhledávací transformace a výběrová transformace.