Spojení transformace v mapování toku dat
PLATÍ PRO:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Toky dat jsou k dispozici ve službě Azure Data Factory i v kanálech Azure Synapse. Tento článek se týká mapování toků dat. Pokud s transformacemi začínáte, přečtěte si úvodní článek Transformace dat pomocí mapování toku dat.
Pomocí transformace spojení můžete zkombinovat data ze dvou zdrojů nebo datových proudů v toku dat mapování. Výstupní datový proud bude obsahovat všechny sloupce z obou zdrojů, které se shodují na základě podmínky spojení.
Typy spojení
Mapování toků dat aktuálně podporuje pět různých typů spojení.
Vnitřní spojení
Vnitřní spojení vypíše pouze řádky, které mají odpovídající hodnoty v obou tabulkách.
Levý vnější
Levé vnější spojení vrátí všechny řádky z levého datového proudu a odpovídající záznamy z pravého datového proudu. Pokud řádek z levého datového proudu neodpovídá, výstupní sloupce z pravého datového proudu jsou nastaveny na hodnotu NULL. Výstupem budou řádky vrácené vnitřním spojením a chybějícími řádky z levého datového proudu.
Poznámka:
Modul Spark používaný toky dat občas selže kvůli možným kartézským produktům v podmínkách spojení. Pokud k tomu dojde, můžete přepnout na vlastní křížové spojení a ručně zadat podmínku spojení. To může mít za následek pomalejší výkon toků dat, protože prováděcí modul může potřebovat vypočítat všechny řádky z obou stran relace a potom filtrovat řádky.
Pravý vnější
Pravé vnější spojení vrátí všechny řádky z pravého datového proudu a odpovídající záznamy z levého datového proudu. Pokud řádek z pravého datového proudu neodpovídá, výstupní sloupce z levého datového proudu jsou nastaveny na hodnotu NULL. Výstupem budou řádky vrácené vnitřním spojením a chybějícími řádky z pravého datového proudu.
Úplná vnější
Full outer join výstups all columns and rows from both sides with NULL values for columns that that't matched.
Vlastní křížové spojení
Křížové spojení výstupy křížového spojení obou datových proudů na základě podmínky. Pokud používáte podmínku, která není rovnost, zadejte jako podmínku křížového spojení vlastní výraz. Výstupní datový proud bude všechny řádky, které splňují podmínku spojení.
Tento typ spojení můžete použít pro neekviňové spojení a OR podmínky.
Pokud chcete explicitně vytvořit úplný kartézský součin, použijte transformaci odvozeného sloupce v každém ze dvou nezávislých datových proudů před spojením a vytvořte syntetický klíč, který se má shodovat. Například vytvořte nový sloupec v Odvozený sloupec v každém datovém proudu volal SyntheticKey a nastavte ho na hodnotu rovna 1. Pak použijte a.SyntheticKey == b.SyntheticKey jako vlastní výraz spojení.
Poznámka:
Nezapomeňte do vlastního křížového spojení zahrnout aspoň jeden sloupec z každé strany levé a pravé relace. Provádění křížových spojení se statickými hodnotami místo sloupců na každé straně vede k úplnému prohledávání celé datové sady, což vede k špatnému výkonu toku dat.
Přibližné spojení
Můžete zvolit spojení na základě logiky přibližného spojení místo přesné shody hodnot sloupců zapnutím možnosti Použít přibližné shody.
- Kombinování textových částí: Tuto možnost použijte k vyhledání shody odebráním mezery mezi slovy. Pokud je tato možnost povolená, služba Data Factory se například shoduje s DataFactory.
- Sloupec skóre podobnosti: Volitelně můžete zvolit, jestli chcete uložit odpovídající skóre pro každý řádek ve sloupci zadáním nového názvu sloupce, do kterého chcete tuto hodnotu uložit.
- Prahová hodnota podobnosti: Zvolte hodnotu mezi 60 a 100 jako procentuální shodu mezi hodnotami ve vybraných sloupcích.
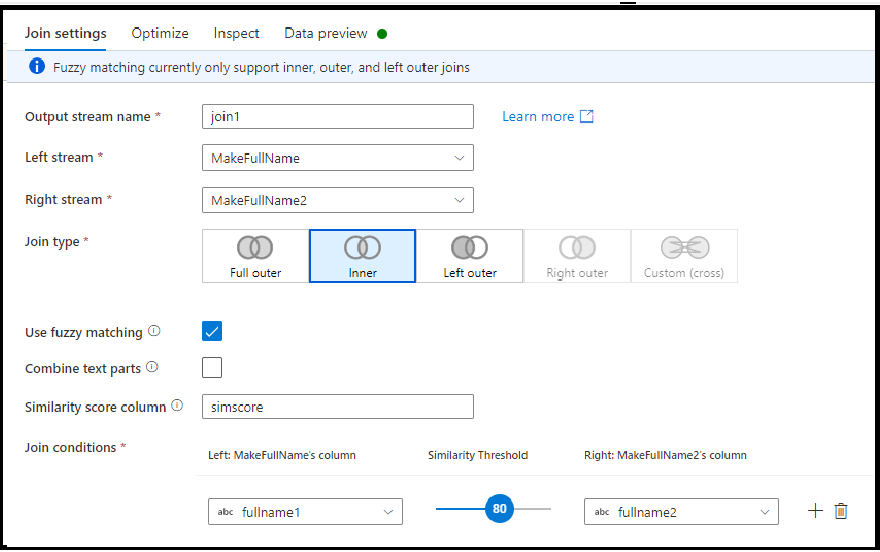
Poznámka:
Přibližné porovnávání v současné době funguje pouze s typy sloupců řetězců a s vnitřními, levými vnějšími a úplnými typy vnějšího spojení. Optimalizaci všesměrového vysílání musíte vypnout při použití přibližných shodných spojení.
Konfigurace
- V rozevíracím seznamu Pravého datového proudu vyberte, ke kterému datovému proudu se připojujete.
- Vyberte typ spojení.
- Vyberte, které klíčové sloupce chcete pro podmínku spojení spárovat. Ve výchozím nastavení tok dat hledá rovnost mezi jedním sloupcem v každém datovém proudu. Pokud chcete porovnat vypočítanou hodnotu, najeďte myší na rozevírací seznam sloupce a vyberte Vypočítaný sloupec.
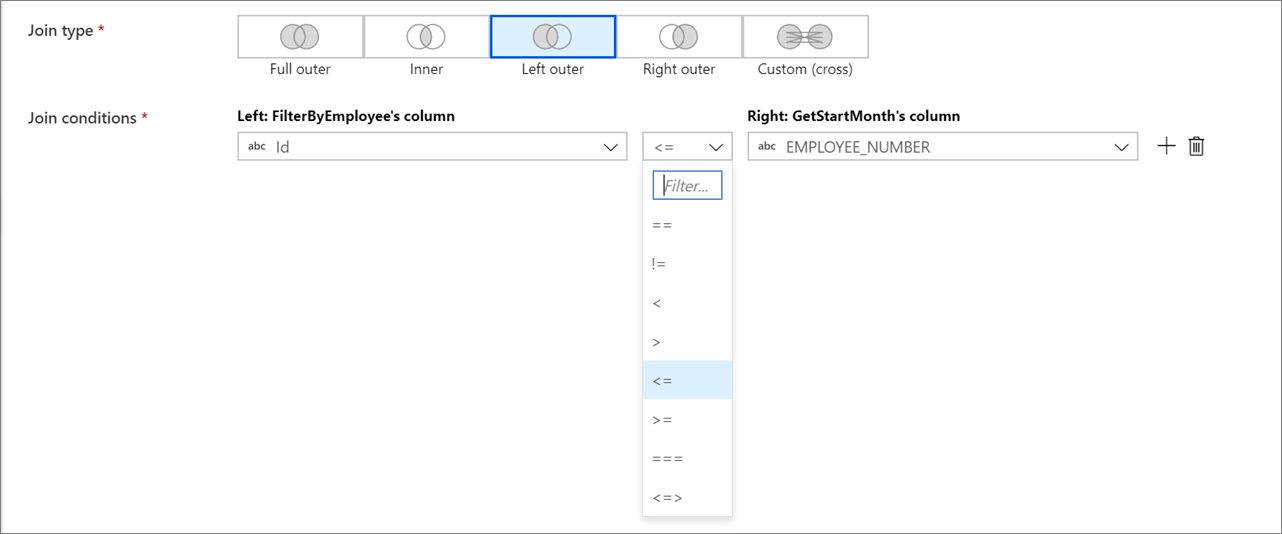
Spojení bez koňovitých
Pokud chcete v podmínkách spojení použít podmíněný operátor, například nerovná se (!=) nebo větší než (>), změňte rozevírací seznam operátoru mezi těmito dvěma sloupci. Spojení bez koňovitých vyžadují, aby se alespoň jeden ze dvou datových proudů vysílal pomocí pevného vysílání na kartě Optimalizace.
Optimalizace výkonu spojení
Na rozdíl od sloučení spojení v nástrojích, jako je SSIS, transformace spojení není povinná operace sloučení spojení. Klíče spojení nevyžadují řazení. Operace spojení se provádí na základě optimální operace spojení ve Sparku, buď vysílání, nebo spojení na straně mapy.
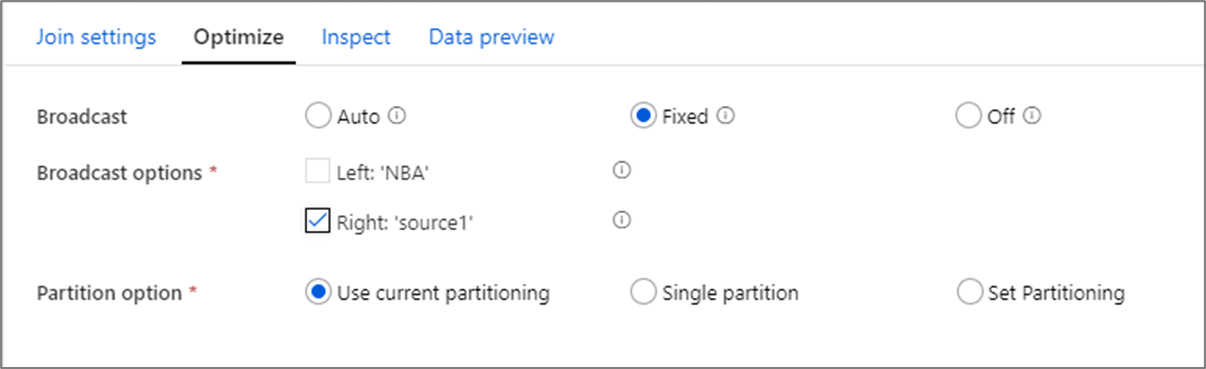
Ve spojeních vyhledávání a existuje transformace, pokud se jeden nebo oba datové proudy vejdou do paměti pracovních uzlů, můžete optimalizovat výkon povolením broadcastingu. Ve výchozím nastavení se modul Spark automaticky rozhodne, jestli se má vysílat jedna strana. Pokud chcete ručně zvolit, která strana se má vysílat, vyberte Opraveno.
Nedoporučuje se zakázat vysílání prostřednictvím možnosti Vypnuto , pokud u spojení neběží chyby časového limitu.
Připojení k vlastnímu připojení
Pokud se chcete připojit k datovému proudu samostatně, alias existujícího datového proudu s výběrovou transformací. Novou větev vytvoříte kliknutím na ikonu plus vedle transformace a výběrem možnosti Nová větev. Přidejte výběrovou transformaci pro alias původního datového proudu. Přidejte transformaci spojení a zvolte původní datový proud jako levý datový proud a výběr transformace jako pravý datový proud.
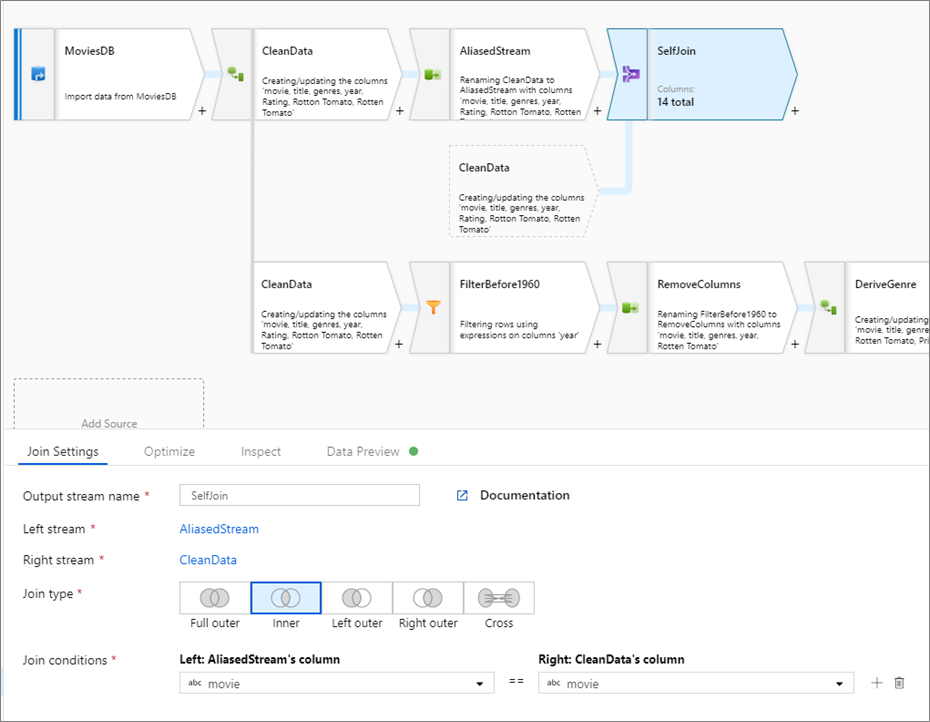
Testování podmínek spojení
Při testování transformací spojení s náhledem dat v režimu ladění použijte malou sadu známých dat. Při vzorkování řádků z velké datové sady nemůžete předpovědět, které řádky a klíče se budou číst pro účely testování. Výsledek není deterministický, což znamená, že podmínky spojení nemusí vracet žádné shody.
Skript toku dat
Syntaxe
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
Příklad vnitřního spojení
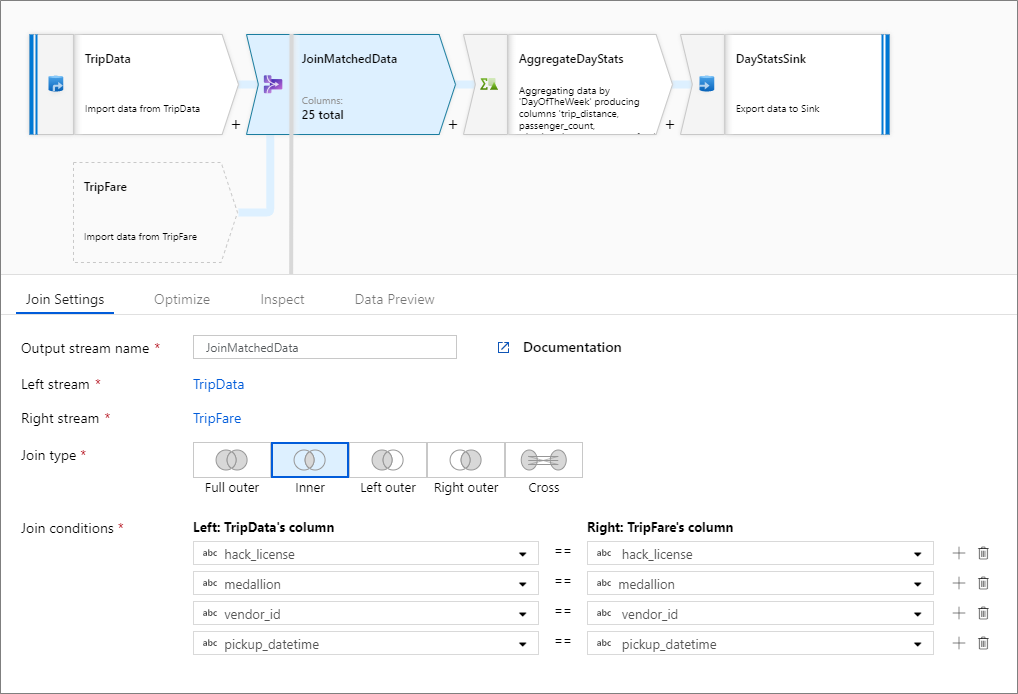
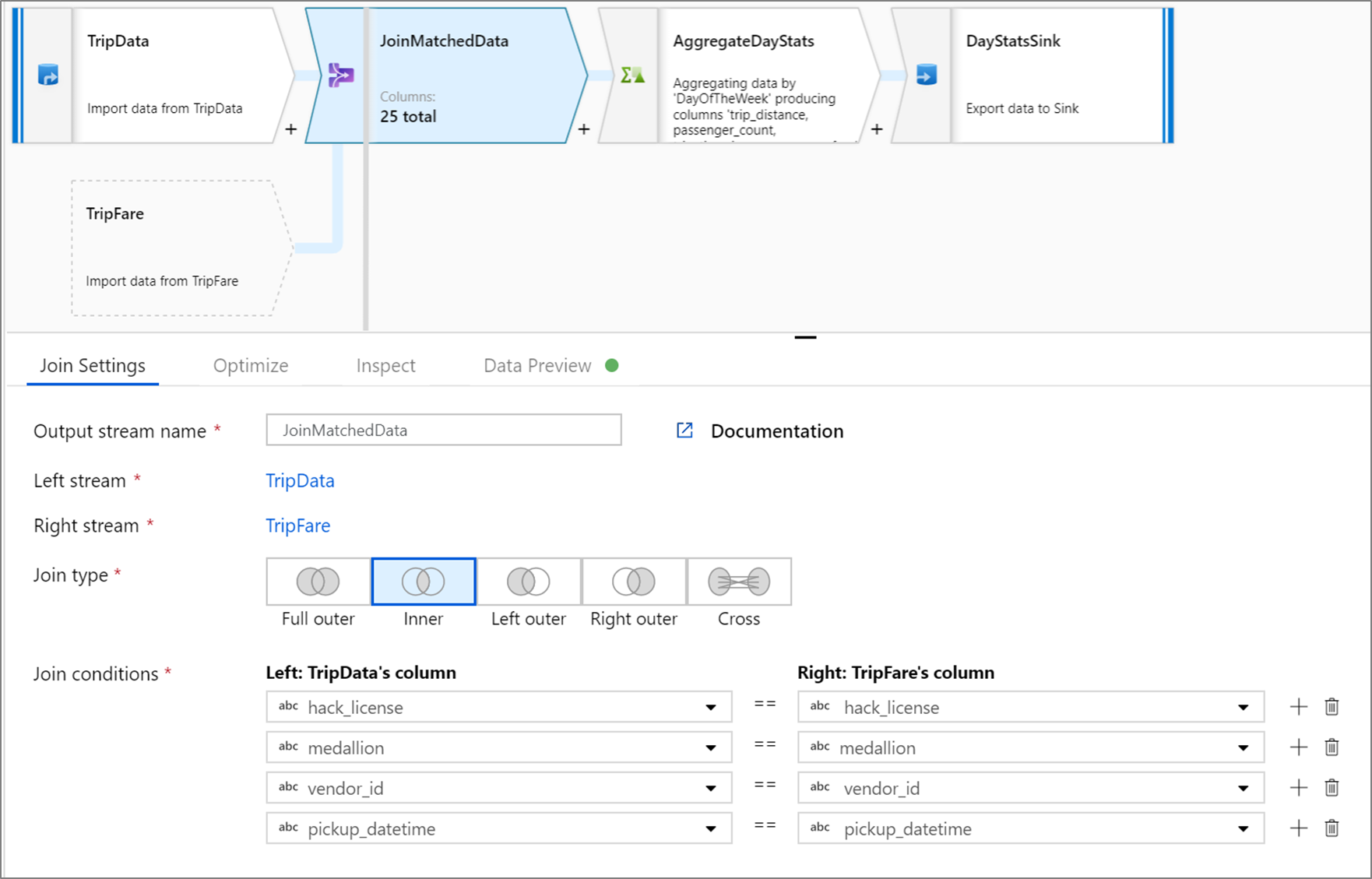
Následující příklad je transformace spojení s názvem JoinMatchedData , která přebírá levý stream TripData a pravý datový proud TripFare. Podmínkou spojení je výrazhack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime}, který vrátí hodnotu true, pokud hack_licensese sloupec , medallionvendor_ida pickup_datetime sloupce v každém datovém proudu shodují. To joinType je 'inner'. Povolujeme vysílání pouze v levém datovém proudu, takže broadcast má hodnotu 'left'.
V uživatelském rozhraní vypadá tato transformace jako na následujícím obrázku:
Skript toku dat pro tuto transformaci je v následujícím fragmentu kódu:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Příklad vlastního křížového spojení
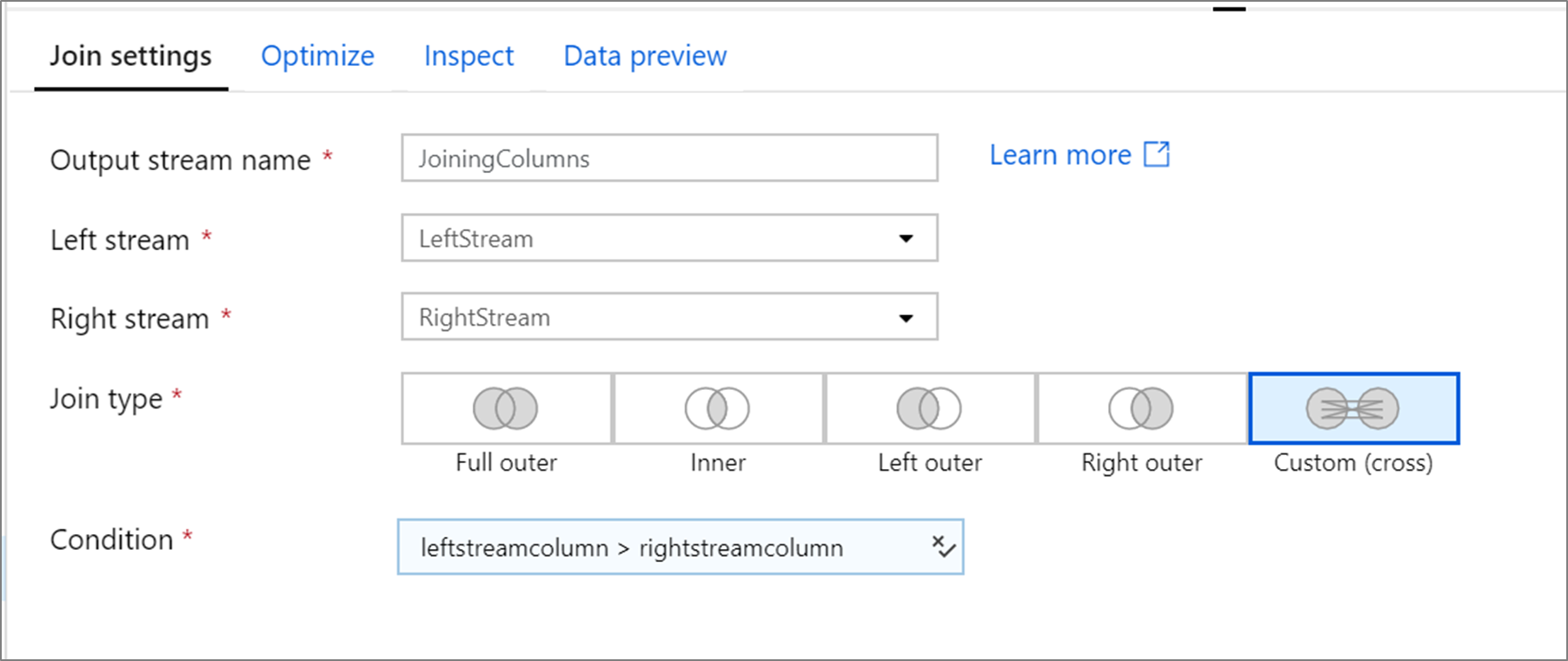
Následující příklad je transformace spojení s názvem JoiningColumns , která přebírá levý stream LeftStream a pravý datový proud RightStream. Tato transformace přebírá dva datové proudy a spojuje všechny řádky, ve kterých je sloupec leftstreamcolumn větší než sloupec rightstreamcolumn. To joinType je cross. Vysílání není povoleno broadcast , má hodnotu 'none'.
V uživatelském rozhraní vypadá tato transformace jako na následujícím obrázku:
Skript toku dat pro tuto transformaci je v následujícím fragmentu kódu:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Související obsah
Po připojení dat vytvořte odvozený sloupec a jímka dat do cílového úložiště dat.