使用在線數據表提供即時功能
重要
在線數據表在下列區域中處於公開預覽狀態:westus、eastus、eastus2、northeuropewesteurope。 如需定價資訊,請參閱 線上表格定價。
在線數據表是 Delta 數據表的唯讀複本,以針對在線存取優化的數據列導向格式儲存。 在線數據表是完全無伺服器數據表,可透過要求負載自動調整輸送量容量,並提供低延遲和高輸送量存取任何規模的數據。 線上資料表專為搭配馬賽克 AI 模型服務、特徵服務及擷取增強生成(RAG)應用程式而設計,這些應用程式用於快速查找資料。
您也可以在查詢中使用 Lakehouse Federation的在線數據表。 使用 Lakehouse 同盟時,您必須使用無伺服器 SQL 倉儲來存取在線數據表。 僅支援讀取作業 (SELECT)。 此功能僅用於互動或偵錯用途,不應用於生產或任務關鍵性工作負載。
使用 Databricks UI 建立線上數據表是一個單步驟的過程。 只要在 [目錄瀏覽器] 中選取 [Delta] 資料表,然後選取 [建立在線表格]。 您也可以使用 REST API 或 Databricks SDK 來建立和管理在線數據表。 請參閱 使用 API 操作線上表格。
需求
- 必須為 Unity 目錄啟用此工作區。 根據 文件 建立 Unity Catalog 中繼數據存放區,並在工作區啟用,然後創建一個目錄。
- 模型必須在 Unity 目錄中註冊,才能存取在線數據表。
使用UI操作線上數據表
本節說明如何建立和刪除在線數據表,以及如何檢查在線數據表的狀態和觸發更新。
使用UI建立線上數據表
您可以使用目錄總管建立線上數據表。 如需有關必要權限的資訊,請參閱使用者權限。
若要建立在線數據表,來源 Delta 數據表必須有主鍵。 如果您想要使用的 Delta 資料表沒有主鍵,請依照下列指示建立一個資料表:在 Unity 目錄中使用現有的 Delta 資料表做為功能資料表。
在 [目錄總管] 中,流覽至您要同步至在線數據表的源數據表。 從「建立」功能表,選取「在線表格」。
![選擇 [建立線上資料表]](../../_static/images/machine-learning/feature-store/create-online-table.png)
使用對話框中的選取器來設定在線數據表。
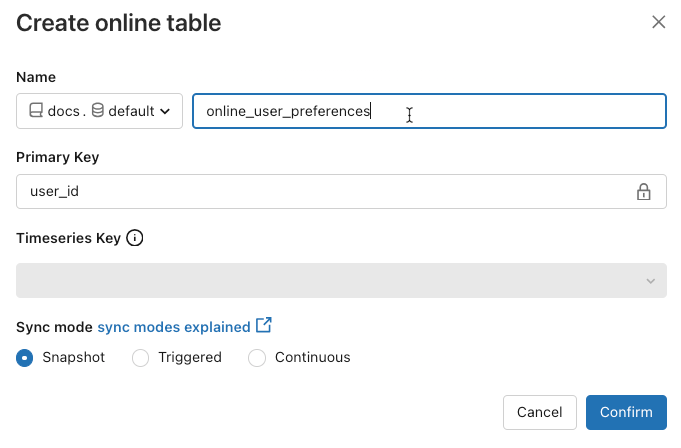
名稱:用於 Unity Catalog 中線上資料表的名稱。
主鍵:來源資料表中的欄位在線上資料表中作為主鍵。
時間序索引鍵:(選用)。 源數據表中的欄位被用作時間序列鍵。 當指定時,線上資料表只包含每個主鍵具有最新時序鍵值的資料列。
同步模式:指定同步處理管線如何更新在線數據表。 選擇 快照、觸發或 連續。
政策 描述 快照 管道會執行一次,以擷取來源表格的快照,並將其複製到線上表格。 源數據表的後續變更會自動反映在在線數據表中,方法是擷取來源的新快照集並建立新的複本。 線上資料表的內容會原子性地更新。 觸發 資料管道執行一次,以便在線上數據表中建立源數據表的初始快照副本。 不同於快照同步模式,當在線數據表重新整理時,只會取得自上次管線執行以來的變更,並將其套用到在線數據表上。 增量重新整理可以根據排程手動觸發或自動觸發。 連續 管道持續運行。 來源表格的後續變更會逐步套用至線上表格,並以即時串流模式進行。 不需要手動重新整理。
注意
若要支援 觸發 或 連續 同步模式,源數據表必須已啟用 變更數據摘要。
- 完成時,按一下 [確認]。 在線數據表頁面隨即出現。
- 新的在線數據表會在建立對話框中指定的目錄、架構和名稱下建立。 在目錄總管中,在線資料表會以線上資料表圖示
 。
。
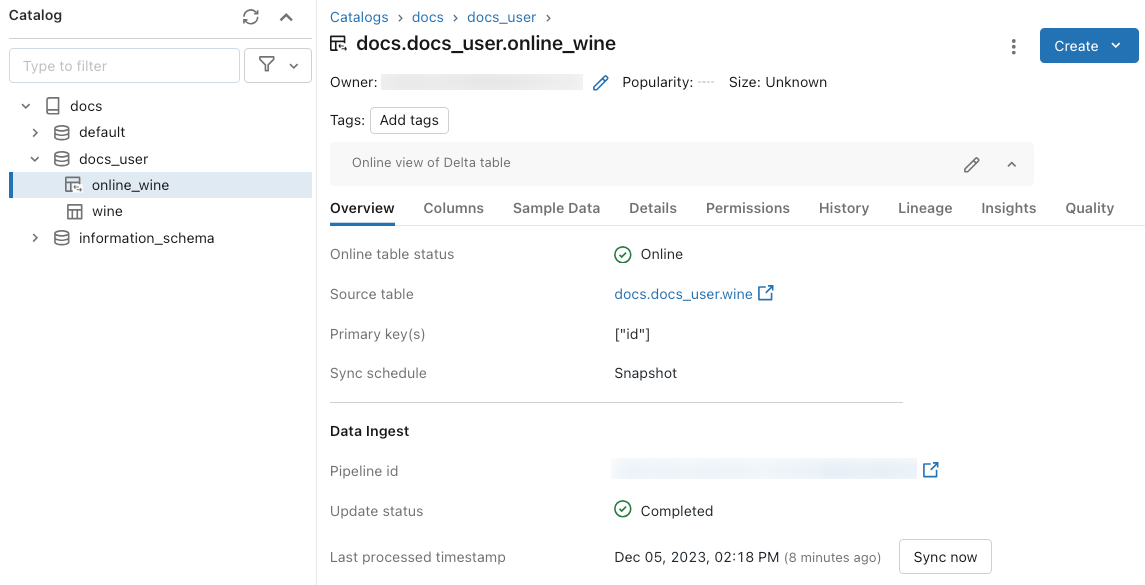
使用UI取得狀態和觸發更新
若要檢查在線數據表的狀態,請按兩下 Catalog 中資料表的名稱以開啟它。 在線數據表頁面隨即出現,[概觀] 索引標籤開啟。 數據擷取 區段會顯示最新更新的狀態。 若要觸發更新,請點擊 立即同步。 數據攝取 區段也包含更新資料表的 DLT 管線連結。
安排定期更新
針對使用 快照 或 觸發器 同步模式的在線資料表,您可以安排自動定期更新。 更新排程是由更新數據表的 DLT 管線所管理。
- 在 [目錄總管] 中,流覽至在線數據表。
- 在 資料引入 區段中,點選管線的連結。
- 在右上角,按兩下 [排程]
,然後新增排程或更新現有的排程。
使用UI刪除線上資料表
從在線數據表頁面中,從 ![]() 選單中選擇 刪除。
選單中選擇 刪除。
使用 API 處理線上表格
您也可以使用 Databricks SDK 或 REST API 來建立和管理在線數據表。
如需參考資訊,請參閱適用於 Python 的 Databricks SDK 或 REST API 的參考文件。
需求
Databricks SDK 0.20 版或更新版本。
使用 API 建立在線數據表
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
在線數據表會在建立之後自動開始同步處理。
使用 API 取得狀態和觸發重新整理
您可以遵循下列範例來檢視在線數據表的狀態和規格。 如果您的在線數據表不是連續的,而且您想要觸發其數據的手動重新整理,您可以使用管線 API 來執行此動作。
使用與線上資料表規格中線上資料表相關聯的管線ID,並在管線上啟動新的更新以觸發刷新。 這相當於在 [目錄總管] 中的在線數據表 UI 中單擊 [立即同步]。
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'DLT: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in DLT: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
使用 API 刪除線上數據表
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
刪除在線數據表會停止任何進行中的數據同步處理,並釋放其所有資源。
使用功能服務端點提供線上資料表數據
針對裝載於 Databricks 外部的模型和應用程式,您可以建立功能服務端點,以從在線數據表提供功能。 端點使用 REST API 提供低延遲的功能。
建立特徵規格。
當您建立功能規格時,您可以指定來源 Delta 資料表。 這允許同時在離線和線上案例中使用特徵規格。 針對在線查閱,服務端點會自動使用在線數據表來執行低延遲功能查閱。
來源 Delta 數據表和在線數據表必須使用相同的主鍵。
功能規格可以在目錄瀏覽器的 [功能] 索引標籤中檢視。
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )建立功能服務端點。
此步驟假設您已建立名為
user_preferences_online_table的線上資料表,以同步處理 Delta 資料表中的數據user_preferences。 使用功能規格來建立功能服務端點。 端點會使用相關聯的在線數據表,透過 REST API 提供資料。注意
執行這項作業的用戶必須是離線數據表和在線數據表的擁有者。
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )從功能服務端點取得數據。
若要存取 API 端點,請將 HTTP GET 要求傳送至端點 URL。 此範例顯示如何使用 Python API 執行此作業。 如需其他語言和工具,請參閱特徵服務。
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
搭配RAG應用程式使用在線數據表
RAG 應用程式是在線數據表的常見使用案例。 您可以為 RAG 應用程式所需的結構化資料建立在線數據表,並將它裝載在提供端點的功能上。 RAG 應用程式會使用功能提供端點來查閱線上表格中的相關資料。
常見步驟如下:
- 建立功能服務端點。
- 使用 LangChain 或任何使用端點查詢相關資料的類似套件建立一個工具。
- 使用 LangChain 代理程式或類似代理程式中的工具來擷取相關資料。
- 建立模型服務端點來託管應用程式。
如需逐步指示和範例筆記本,請參閱特徵工程範例:結構化 RAG 應用程式。
筆記本範例
下列筆記本說明如何將功能發佈至在線數據表,以進行即時服務和自動化功能查閱。
線上表格範例說明文件
使用 Mosaic AI Model Serving 的線上數據表
您可以使用線上數據表來查閱馬賽克 AI 模型服務的功能。 當您將功能數據表同步至在線數據表時,使用該功能數據表的功能定型模型會在推斷期間自動從在線數據表查詢特徵值。 不需要進行其他組態設定。
使用
FeatureLookup訓練模型。針對模型定型,請使用模型定型集中離線功能數據表的功能,如下列範例所示:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )使用 Mosaic AI 模型服務為模型提供服務。 模型會自動從線上表格查找特徵。 如需詳細資料,請參閱使用 Databricks 模型服務自動查詢特徵。
使用者權限
您必須具有下列權限才能建立線上資料表:
-
SELECT源數據表的權限。 - 在目的目錄
USE_CATALOG上的權限。 - 目標架構上的
USE_SCHEMA和CREATE_TABLE權限。
若要管理在線數據表的數據同步處理管線,您必須是在線數據表的擁有者,或被授與在線數據表上的 REFRESH 許可權。 沒有目錄USE_CATALOG和USE_SCHEMA許可權的使用者將不會在目錄總管中看到在線數據表。
Unity Catalog 中繼存放區必須擁有 特權模型版本 1.0。
端點權限模型
系統會自動為功能服務或模型服務端點建立唯一的服務主體,並具有從在線數據表查詢數據所需的有限許可權。 此服務主體允許端點獨立於建立資源的使用者存取資料,並確保當建立者離開工作區時端點可以繼續運作。
此服務主體的存留期是端點的存留期。 稽核日誌可能顯示系統為 Unity Catalog 目錄的擁有者產生的紀錄,並授與此服務主體所需的必要權限。
限制
- 每個源數據表只支援一個在線數據表。
- 在線數據表及其源數據表最多可以有1000個數據行。
- 數據類型為 ARRAY、MAP 或 STRUCT 的欄位不能作為線上資料表的主鍵。
- 如果使用數據行做為在線數據表的主鍵,則會忽略數據行包含 Null 值之源數據表中的所有數據列。
- 不支援外部、系統和內部數據表做為源數據表。
- 未啟用 Delta 變更資料提要的源資料表僅支援 快照 同步模式。
- Delta Sharing 表格僅支援 快照 同步模式。
- 在線數據表的目錄、架構和數據表名稱只能包含英數位元和底線,不得以數字開頭。 不允許使用虛線 (
-)。 - String 類型的數據行長度限制為 64KB。
- 數據行名稱的長度限制為64個字元。
- 資料列大小上限為 2MB。
- 在公開預覽期間,Unity 目錄中繼存放區中所有在線數據表的組合大小是 2TB 未壓縮的用戶數據。
- 每秒查詢數 (QPS) 上限為 12,000。 請聯絡您的 Databricks 帳戶管理團隊以增加上限。
疑難排解
我看不到 建立線上表格 選項
原因通常是您嘗試從 同步處理的數據表(源數據表)不是支援的型別。 請確保來源資料表的可保護類型(如在目錄資源管理器 詳細資訊 標籤中顯示)是下列支援的選項之一:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
當我建立線上數據表時,我無法選取 觸發 或 連續 同步模式
如果源資料表未啟用 Delta 更改資料傳遞,或是該資料表為檢視或具現化檢視,就會發生這種情況。 若要使用 累加式 同步模式,請在來源資料表上啟用變更資料擷取,或使用非檢視表。
在線數據表更新失敗或狀態顯示為離線
若要開始針對此錯誤進行疑難解答,請按 [Catalog Explorer] 的在線數據表中 [概觀] 索引標籤出現的管線 ID。
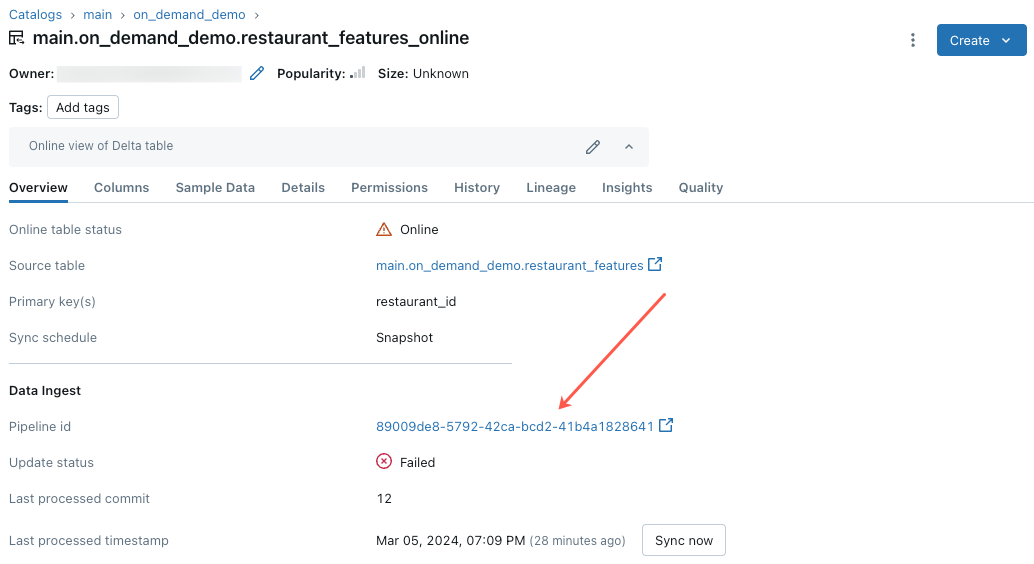
在顯示的管線 UI 頁面上,按一下標註為「無法解析流程 '__online_table'」的項目。
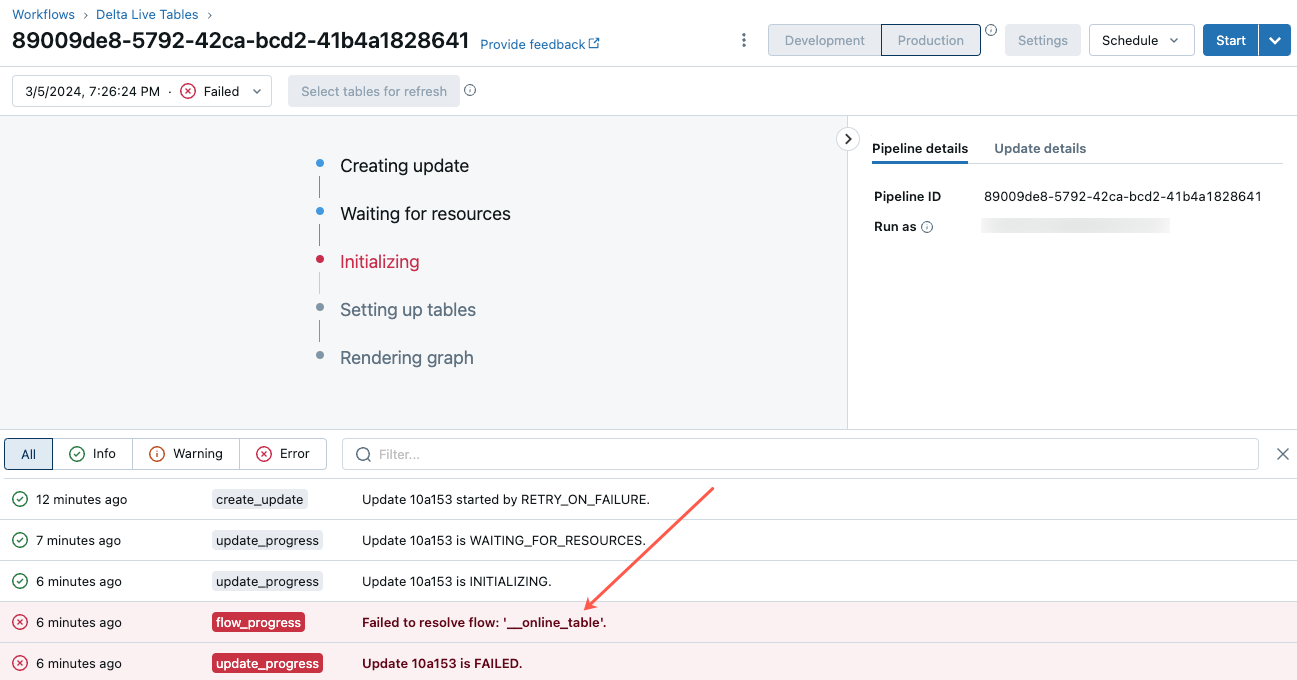
快顯視窗隨即出現,在 [錯誤詳細資料] 區段中提供了詳細資料。
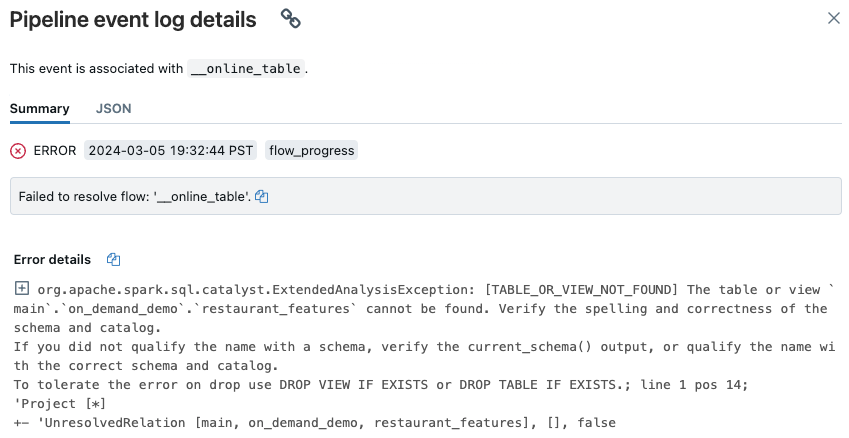 的在線表格詳細資料
的在線表格詳細資料
錯誤的常見原因包括如下:
在線上資料表同步時,源資料表已被刪除,或者被刪除後以相同名稱重新建立。 這特別常見於連續的線上表格,因為它們會不斷同步。
由於防火牆設定,無法透過無伺服器計算存取源數據表。 在這種情況下,[錯誤詳細資料] 區段可能會顯示錯誤訊息「無法啟動叢集 xxx 上的 DLT 服務...」。
在線數據表的匯總大小超過 2 TB(未壓縮的大小)中繼存放區寬限制。 2 TB 的限制是指以數據列導向格式擴充 Delta 數據表之後未壓縮的大小。 數據列格式的數據表大小可以明顯大於目錄總管中顯示的 Delta 資料表大小,這是指以數據行導向格式壓縮的數據表大小。 視數據表的內容而定,差異可能高達 100x。
若要估計 Delta 數據表未壓縮的數據列擴充大小,請使用來自無伺服器 SQL 倉儲的下列查詢。 查詢會以位元組為單位傳回估計的展開數據表大小。 成功執行此查詢也會確認無伺服器計算可以存取源數據表。
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;