在 Unity 目錄中使用功能數據表
此頁面說明如何在 Unity Catalog 中建立和使用功能資料表。
此頁面僅適用於為 Unity Catalog 啟用的工作區。 如果您的工作區未啟用 Unity Catalog,請參閱 在工作區功能庫中使用功能表(舊版)。
如需此頁面範例中使用的命令和參數詳細資訊,請參閱特徵工程 Python API 參照。
需求
Unity Catalog 中的特徵工程需要 Databricks Runtime 13.2 LTS 或更高版本。 此外,Unity Catalog 中繼存放區必須具有權限模型 1.0 版。
在 Unity Catalog Python 用戶端中安裝特徵工程
Unity Catalog 中的特徵工程具有 Python 用戶端 FeatureEngineeringClient。 此類別可在 databricks-feature-engineering 套件的 PyPI 上找到,並預安裝在 Databricks Runtime 13.3 LTS ML 和更新版本中。 如果您使用非 ML Databricks Runtime,必須手動安裝用戶端。
相容性矩陣圖可用於尋找 Databricks Runtime 版本的正確版本。
%pip install databricks-feature-engineering
dbutils.library.restartPython()
在 Unity Catalog 中建立功能資料表的目錄和結構描述
必須建立新的目錄,或使用功能資料表的現有目錄。
若要建立新的目錄,必須擁有CREATE CATALOG的 權限。
CREATE CATALOG IF NOT EXISTS <catalog-name>
若要使用現有目錄,必須擁有目錄的 USE CATALOG 權限。
USE CATALOG <catalog-name>
Unity Catalog 中的功能資料表必須儲存在結構描述中。 若要在目錄中建立新的結構描述,必須擁有目錄的 CREATE SCHEMA 權限。
CREATE SCHEMA IF NOT EXISTS <schema-name>
在 Unity Catalog 中建立功能資料表
注意
您可以使用 Unity Catalog 中包含主索引鍵約束的現有 Delta 資料表作為功能資料表。 如果資料表沒有定義主索引鍵,必須使用 ALTER TABLE DDL 陳述式更新資料表,以新增條件約束。 請參閱在 Unity Catalog 中使用現有的 Delta 資料表作為功能資料表。
不過,將主索引鍵新增至透過 Delta Live Tables 管線發佈至 Unity Catalog 的串流資料表或具體化檢視,需要修改串流資料表或具體化檢視定義的結構描述,以包含主索引鍵,然後重新整理串流資料表或具體化檢視。 請參閱使用 Delta Live Tables 管線建立的串流資料表或具體化檢視作為功能資料表。
Unity Catalog 中的功能資料表是 Delta 資料表。 功能資料表必須有主索引鍵。 功能資料表,就像 Unity Catalog 中的其他資料資產一樣,是使用三層命名空間來存取的:<catalog-name>.<schema-name>.<table-name>。
您可以使用 Databricks SQL、Python FeatureEngineeringClient 或 Delta Live Tables 管線,在 Unity Catalog 中建立功能資料表。
Databricks SQL
您可以使用任何具有主索引鍵條件約束的 Delta 資料表作為功能資料表。 下列程式碼示範如何建立具有主索引鍵的資料表:
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
);
若要建立時間序列功能資料表,請將時間資料行新增為主索引鍵資料行,並指定 TIMESERIES 關鍵字。 TIMESERIES 關鍵字需要 Databricks Runtime 13.3 LTS 或更新版本。
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
);
建立資料表之後,您可以依循慣常做法將資料寫入其中 (就像寫入其他 Delta 資料表一樣),並將其作為功能資料表。
Python
如需下列範例中使用的命令和參數詳細資料,請參閱特徵工程 Python API 參照。
- 撰寫 Python 函式來計算功能。 每個函式的輸出應該是具有唯一主索引鍵的 Apache Spark DataFrame。 主索引鍵可能包含一個或多個資料行。
- 藉由具現化
FeatureEngineeringClient和使用create_table來建立功能資料表。 - 使用
write_table填入功能資料表。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Prepare feature DataFrame
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
customer_features_df = compute_customer_features(df)
# Create feature table with `customer_id` as the primary key.
# Take schema from DataFrame output by compute_customer_features
customer_feature_table = fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fe.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite primary key, pass all primary key columns in the create_table call
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# To create a time series table, set the timeseries_columns argument
# customer_feature_table = fe.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# timeseries_columns='date',
# ...
# )
使用 Delta Live Tables 管線在 Unity Catalog 中建立功能資料表
從包含主索引鍵條件約束之 Delta Live Tables 管線發佈的任何資料表都可以作為功能資料表使用。 若要使用主索引鍵在 Delta Live Tables 管線中建立資料表,可以使用 Databricks SQL 或 Delta Live Tables Python 程式設計介面。
若要使用主索引鍵在 Delta Live Tables 管線中建立資料表,請使用下列語法:
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id)
""")
def customer_features():
return ...
若要建立時間序列功能資料表,請將時間資料行新增為主索引鍵資料行,並指定 TIMESERIES 關鍵字。
Databricks SQL
CREATE LIVE TABLE customer_features (
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
) AS SELECT * FROM ...;
Python
import dlt
@dlt.table(
schema="""
customer_id int NOT NULL,
ts timestamp NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (customer_id, ts TIMESERIES)
""")
def customer_features():
return ...
建立資料表之後,您可以依循慣常做法將資料寫入其中 (就像寫入其他 Delta Live Tables 資料集一樣),並將其作為功能資料表。
在 Unity Catalog 中使用現有的 Delta 資料表作為功能資料表
Unity Catalog 中具有主索引鍵的任何 Delta 資料表都可以是 Unity Catalog 中的功能資料表,您可以將功能 UI 和 API 與資料表搭配使用。
注意
- 只有資料表擁有者才能宣告主索引鍵條件約束。 擁有者名稱顯示在目錄總管的資料表詳細資料頁面上。
- 驗證 Unity Catalog 中的特徵工程是否支援 Delta 資料表中的資料類型。 請參閱不支援的資料類型。
- TIMESERIES 關鍵字需要 Databricks Runtime 13.3 LTS 或更新版本。
如果現有的 Delta 資料表沒有主索引鍵條件約束,可以依循如下方法建立一個:
將主索引鍵資料行設定為
NOT NULL。 對於每個主索引鍵資料行,執行:ALTER TABLE <full_table_name> ALTER COLUMN <pk_col_name> SET NOT NULL變更資料表以新增主索引鍵條件約束:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1, pk_col2, ...)pk_name是主索引鍵條件約束的名稱。 依慣例,您可以使用帶有_pk尾碼的資料表名稱 (沒有結構描述和目錄)。 例如,名稱為"ml.recommender_system.customer_features"的資料表會將customer_features_pk作為主索引鍵條件約束的名稱。若要讓資料表成為時間序列功能資料表,請在其中一個主索引鍵資料行上指定 TIMESERIES 關鍵字,如下所示:
ALTER TABLE <full_table_name> ADD CONSTRAINT <pk_name> PRIMARY KEY(pk_col1 TIMESERIES, pk_col2, ...)在資料表上新增主索引鍵條件約束之後,資料表會出現在功能 UI 中,您可以使用它作為功能資料表。
使用 Delta Live Tables 管線建立的串流資料表或具體化檢視作為功能資料表
Unity Catalog 中具有主索引鍵的任何串流資料表或具體化檢視都可以是 Unity Catalog 中的功能資料表,您可以將功能 UI 和 API 與資料表搭配使用。
注意
若要設定現有串流資料表或具體化檢視的主索引鍵,請在管理物件的筆記本中更新串流資料表或具體化檢視的結構描述。 然後,重新整理資料表以更新 Unity Catalog 物件。
以下是將主索引鍵加入具體化檢視的語法:
Databricks SQL
CREATE OR REFRESH MATERIALIZED VIEW existing_live_table(
id int NOT NULL PRIMARY KEY,
...
) AS SELECT ...
Python
import dlt
@dlt.table(
schema="""
id int NOT NULL PRIMARY KEY,
...
"""
)
def existing_live_table():
return ...
使用 Unity 目錄中的現有檢視做為功能數據表
若要使用檢視做為功能數據表,您必須使用 databricks-feature-engineering 0.7.0 版或更新版本,其內建於 Databricks Runtime 16.0 ML 中。
Unity Catalog 中的簡單 SELECT 檢視可以是 Unity Catalog 中的特徵表,而且您可以使用「Features API」搭配該資料表。
注意
- 簡單的 SELECT 檢視定義為從 Unity Catalog 中的單一 Delta 表建立的檢視,它可用作特徵表,而其主鍵選取時不含 JOIN、GROUP BY或 DISTINCT 子句。 SQL 語句中可接受的關鍵詞為 SELECT、FROM、WHERE、ORDER BY、LIMIT和 OFFSET。
- 如需支持的數據類型,請參閱 支援的數據類型。
- 由檢視支援的功能數據表不會出現在功能UI中。
- 如果在源 Delta 資料表中有欄位被重新命名,則必須將視圖定義中的 SELECT 語句中的欄位也重新命名以保持一致。
以下是可作為功能數據表的簡單 SELECT 檢視範例:
CREATE OR REPLACE VIEW ml.recommender_system.content_recommendation_subset AS
SELECT
user_id,
content_id,
user_age,
user_gender,
content_genre,
content_release_year,
user_content_watch_duration,
user_content_like_dislike_ratio
FROM
ml.recommender_system.content_recommendations_features
WHERE
user_age BETWEEN 18 AND 35
AND content_genre IN ('Drama', 'Comedy', 'Action')
AND content_release_year >= 2010
AND user_content_watch_duration > 60;
以檢視為基礎的功能數據表可用於離線模型定型和評估。 它們無法發佈至在線商店。 無法根據這些功能提供來自這些數據表和模型的功能。
更新 Unity Catalog 中的功能資料表
您可以藉由新增新功能,或根據主索引鍵修改特定資料列,來更新 Unity Catalog 中的功能資料表。
不應更新下列功能資料表中繼資料:
- 主索引鍵。
- 分割區索引鍵。
- 現有功能的名稱或資料類型。
變更它們會導致使用功能來訓練和提供模型的下游管線中斷。
將新功能新增至 Unity Catalog 中的現有功能資料表
可以使用下列兩種方式之一,將新功能新增至現有功能資料表:
- 更新現有的功能計算函式,並使用傳回的 DataFrame 執行
write_table。 這會更新功能資料表結構描述,並根據主索引鍵合併新的功能值。 - 建立新的功能計算函式來計算新的功能值。 這個新計算函式傳回的 DataFrame 必須包含功能資料表的主索引鍵和資料分割索引鍵 (如果已定義)。 使用 DataFrame 執行
write_table,以使用相同的主索引鍵將新功能寫入現有的功能資料表。
僅更新功能資料表中的特定資料列
在 mode = "merge" 中使用 write_table。
write_table 呼叫中傳送之 DataFrame 中,不存在主索引鍵的資料列保持不變。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.write_table(
name='ml.recommender_system.customer_features',
df = customer_features_df,
mode = 'merge'
)
排程工作以更新功能資料表
為了確保功能資料表中的功能一律具有最新的值,Databricks 建議您建立一個工作來執行筆記本,定期 (例如每天) 更新功能資料表。 如果您已建立非排程工作,可以將其轉換成排程工作,以確保功能值一律為最新狀態。 請參閱 Databricks 上的協調流程 概觀。
更新功能資料表的程式碼會使用 mode='merge',如下列範例所示。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = compute_customer_features(data)
fe.write_table(
df=customer_features_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
儲存日常功能的過去的值
使用複合主索引鍵定義功能資料表。 在主索引鍵中包含日期。 例如,對於功能資料表 customer_features,可以使用複合主索引鍵 (date、customer_id) 和資料分割索引鍵 date,以有效率地讀取。
Databricks 建議您在資料表上啟用液態群集,以有效率地讀取。 如果不使用液態叢集,請將日期資料行設定為資料分割索引鍵,以提升讀取效能。
Databricks SQL
CREATE TABLE ml.recommender_system.customer_features (
customer_id int NOT NULL,
`date` date NOT NULL,
feat1 long,
feat2 varchar(100),
CONSTRAINT customer_features_pk PRIMARY KEY (`date`, customer_id)
)
-- If you are not using liquid clustering, uncomment the following line.
-- PARTITIONED BY (`date`)
COMMENT "Customer features";
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.create_table(
name='ml.recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
# If you are not using liquid clustering, uncomment the following line.
# partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
然後,您可以建立程式碼,以從篩選 date 的功能資料表中讀取到感興趣的時間週期。
也可以建立時間序列功能資料表,以在使用 create_training_set 或 score_batch 時啟用時間點查閱。 請參閱在 Unity Catalog 中建立功能資料表。
若要讓功能資料表保持最新狀態,請設定定期排程的工作,以將功能寫入功能資料表,或將新的功能值串流至功能資料表。
建立串流功能計算管線以更新功能
若要建立串流功能計算管線,請將串流 DataFrame 作為引數傳遞至 write_table。 此方法會傳回 StreamingQuery 物件。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_transactions = spark.readStream.table("prod.events.customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fe.write_table(
df=stream_df,
name='ml.recommender_system.customer_features',
mode='merge'
)
從 Unity Catalog 中的功能資料表讀取
使用 read_table 來讀取功能值。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
customer_features_df = fe.read_table(
name='ml.recommender_system.customer_features',
)
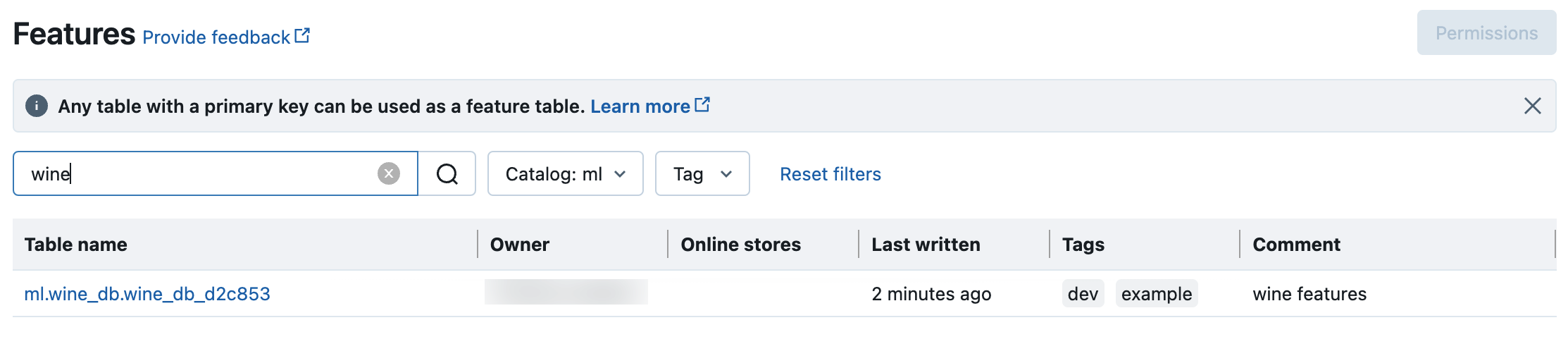
在 Unity Catalog 中搜尋和瀏覽功能資料表
使用功能 UI 來搜尋或瀏覽 Unity Catalog 中的功能資料表。
按下側邊欄中的
 [功能] 以顯示功能 UI。
[功能] 以顯示功能 UI。選取具有目錄選取器的目錄,以檢視該目錄中的所有可用功能資料表。 在搜尋方塊中,輸入功能資料表、功能或批注的所有或部份名稱。 也可以輸入標記的所有或部份索引鍵或值。 搜尋文字不區分大小寫。
取得 Unity Catalog 中功能資料表的中繼資料
使用 get_table 來取得功能資料表中繼資料。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
ft = fe.get_table(name="ml.recommender_system.user_feature_table")
print(ft.features)
在 Unity Catalog 中搭配功能資料表和功能使用標記
可以使用簡單的索引鍵/值組標記來分類和管理功能資料表及功能。
對於功能資料表,可以使用目錄總管、筆記本或 SQL 查詢編輯器中的 SQL 陳述式,或者特徵工程 Python API 來建立、編輯和刪除標記。
對於功能,可以使用目錄總管或者筆記本或 SQL 查詢編輯器中的 SQL 陳述式來建立、編輯和刪除標記。
請參閱將標記套用至 Unity Catalog 安全物件和特徵工程和工作區功能存放區 Python API。
下列範例示範如何使用特徵工程 Python API 來建立、更新和刪除功能資料表標記。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
# Create feature table with tags
customer_feature_table = fe.create_table(
# ...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
# ...
)
# Upsert a tag
fe.set_feature_table_tag(name="customer_feature_table", key="tag_key_1", value="new_key_value")
# Delete a tag
fe.delete_feature_table_tag(name="customer_feature_table", key="tag_key_2")
刪除 Unity Catalog 中的功能資料表
可以使用目錄總管或使用特徵工程 Python API,直接刪除 Unity Catalog 中的 Delta 資料表,以刪除 Unity Catalog 中的功能資料表。
注意
- 刪除功能資料表可能會導致上游生產者和下游取用者 (模型、端點和排程工作) 發生非預期的失敗。 必須透過雲端提供者刪除已發佈的線上商店。
- 當您刪除 Unity Catalog 中的功能資料表時,也會卸除基礎 Delta 資料表。
- Databricks Runtime 13.1 ML 或以下版本不支援
drop_table。 SQL 命令可用於刪除資料表。
可以使用 Databricks SQL 或 FeatureEngineeringClient.drop_table 刪除 Unity Catalog 中的功能資料表:
Databricks SQL
DROP TABLE ml.recommender_system.customer_features;
Python
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
fe.drop_table(
name='ml.recommender_system.customer_features'
)
跨工作區或帳戶在 Unity Catalog 中共用功能資料表
Unity Catalog 中的功能資料表可供指派給資料表 Unity Catalog 中繼存放區的所有工作區存取。
若要與未指派給相同 Unity Catalog 中繼存放區的工作區共用功能資料表,請使用 Delta 共用。