步驟 1: 複製程式代碼存放庫並建立計算
如需本節中的範例程式碼,請參閱 GitHub 存放庫。 您也可以使用存放庫程式代碼作為範本,用來建立您自己的 AI 應用程式。
請遵循下列步驟,將範例程式代碼載入至 Databricks 工作區,並設定應用程式的全域設定。
需求
- 啟用了 Unity Catalog 和無伺服器計算 的 Azure Databricks 工作區。
- 現有的 馬賽克 AI 向量搜尋端點或建立新向量搜尋端點 的許可權(在此案例中,安裝程式筆記本會為您建立一個端點)。
- 寫入現有 Unity 目錄架構的存取權,其中會儲存包含剖析和區塊化檔和向量搜尋索引的輸出 Delta 數據表,或建立新目錄和架構的許可權(在此案例中,安裝程式筆記本會為您建立一個目錄和架構)。
- 執行 DBR 14.3 或更新版本且可存取因特網的單一使用者叢集。 需要有因特網存取權,才能下載必要的 Python 和系統套件。 請勿使用執行 Databricks Runtime 的叢集進行 機器學習,因為這些教學課程與 Databricks Runtime ML 發生 Python 套件衝突。
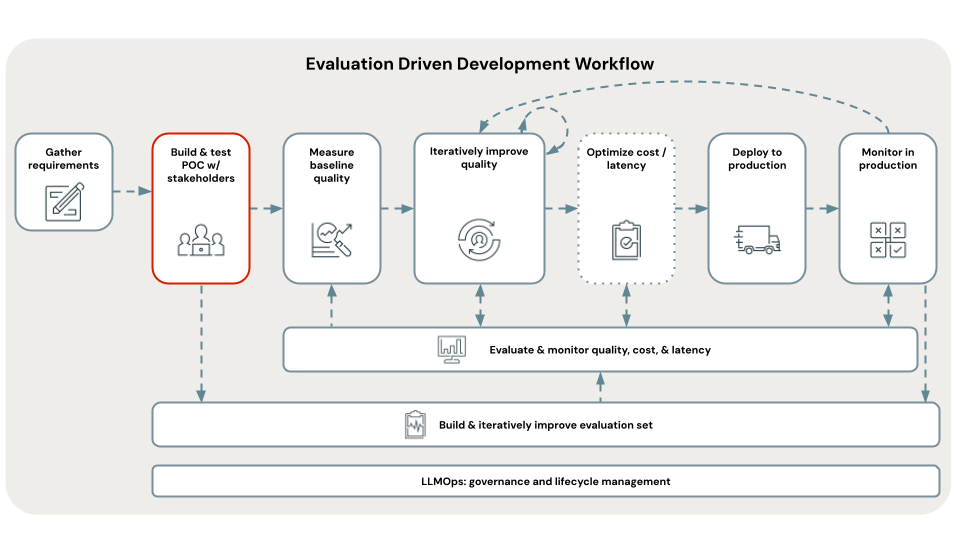
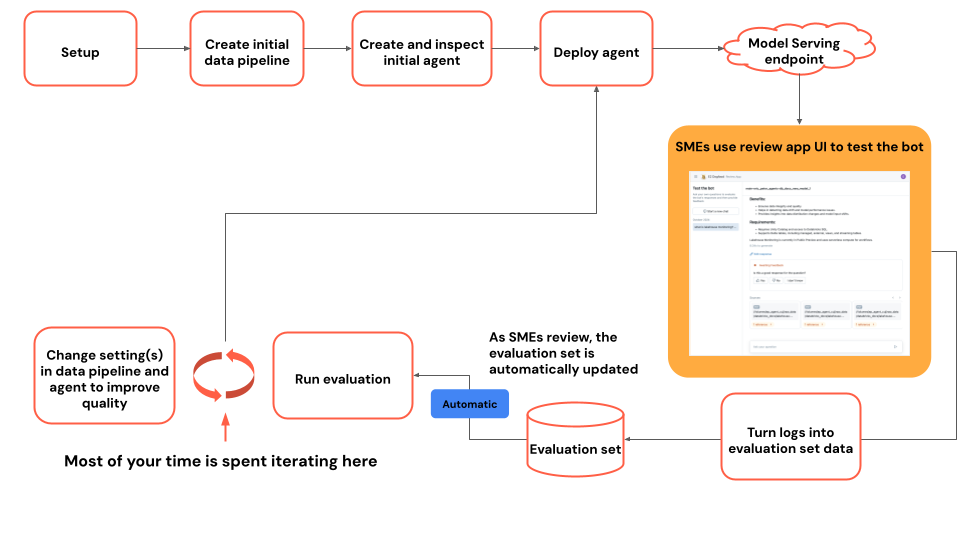
教學課程流程圖
此圖顯示本教學課程中使用的步驟流程。
指示
使用 Git 資料夾將此存放庫複製到您的工作區。
開啟rag_app_sample_code/00_global_config筆記本,然後調整該處的設定。
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"