必要條件:收集需求
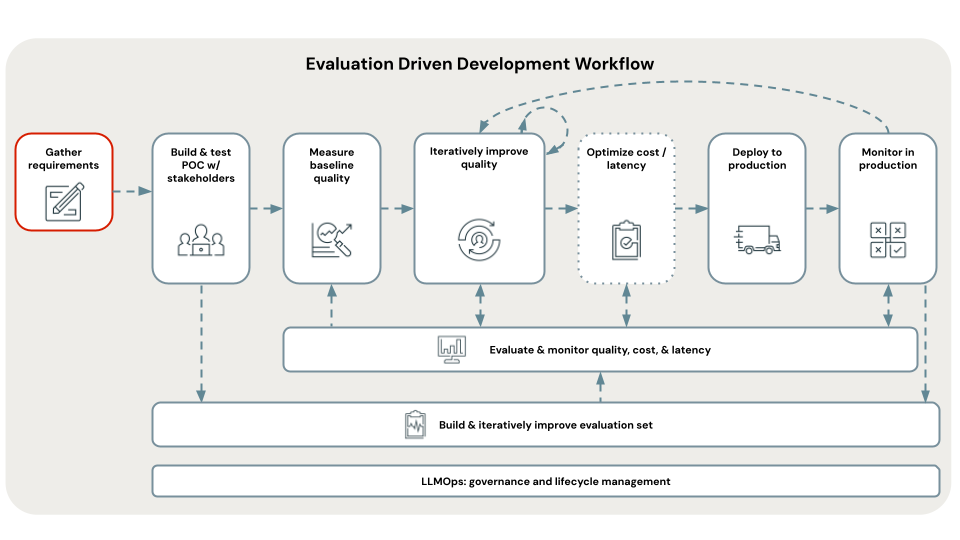
定義清楚且全面的使用案例需求,是開發成功 RAG 應用程式的第一個重要步驟。 這些需求有兩個主要用途。 首先,它們有助於判定 RAG 是否為指定使用案例的最合適方法。 如果 RAG 確實適合,這些需求可指導解決方案設計、實作和評估決策。 在專案開始時投資時間以收集詳細需求,可避免開發程序後期出現重大挑戰和挫折,並確保產生的解決方案符合終端使用者和利害關係人的需求。 妥善定義的需求為開發生命週期的後續階段提供基礎,我們將逐步解說。
如需本節中的範例程式碼,請參閱 GitHub 存放庫。 您也可以使用存放庫程式代碼作為範本,用來建立您自己的 AI 應用程式。
使用案例是否適合 RAG?
您需要建立的第一件事是 RAG 是否適用於您的使用案例。 鑒於對 RAG 的炒作,大家很容易將其視為任何問題的可能解決方案。 不過,RAG 何時適合以及何時不適合存在細微差別。
RAG 在下列情況下為合適:
- 因擷取的資訊 (非結構化和結構化) 而無法完全符合 LLM 的內容視窗
- 從多個來源合成資訊 (例如,從主題的不同文章產生重點的摘要)
- 根據使用者查詢進行動態擷取是必要的 (例如,指定使用者查詢,判定要從中擷取的資料來源)
- 使用案例需要根據擷取的資訊產生新內容 (例如,回答問題、提供說明、提供建議)
RAG 在下列情況下可能不合適:
- 任務不需要查詢特定的擷取。 例如,產生通話文字記錄摘要;即使個別文字記錄在 LLM 提示中以內容的形式提供,擷取的資訊仍會針對每個摘要保持不變。
- 要擷取的整個資訊集適合 LLM 的內容視窗
- 需要極低延遲的回應 (例如,當需要回應時,以毫秒為單位)
- 以規則為基礎的簡單或範本式回應就已足夠 (例如,根據關鍵字提供預先定義答案的客戶支援聊天機器人)
探索的需求
在您確定 RAG 適合使用案例之後,請考慮下列問題,以擷取具體需求。 需求的優先順序如下:
🟢 P0:啟動 POC 之前,必須先定義此需求。
🟡 P1:在進入實際執行環境之前必須定義,但在 POC 期間可以反覆精簡完善。
⚪ P2:最好有需求。
這不是問題的完整清單。 不過,它應該為擷取 RAG 解決方案的主要需求提供紮實的基礎。
使用者體驗
定義使用者如何與 RAG 系統互動,以及預期的回應種類
🟢 [P0] RAG 鏈結的一般要求看起來會是什麼樣子的? 詢問利害關係人是否有潛在使用者查詢的範例。
🟢 [P0] 使用者預期會有哪種回應 (簡短答案、長格式說明、組合或其他內容)?
🟡 [P1] 使用者如何與系統互動? 透過聊天介面、搜尋列或其他形式?
🟡 [P1] hat 聲調或樣式應該產生回應? (正式、交談、技術?)
🟡 [P1] 應用程式如何處理模棱兩可、不完整或無關的查詢? 在這種情況下,是否應該提供任何形式的意見反應或指導?
⚪ [P2] 產生的輸出是否有特定的格式或簡報需求? 除了鏈結的回應之外,輸出是否應該包含任何中繼資料?
資料
判定將用於 RAG 解決方案的資料本質、來源和品質。
🟢 [P0] 有哪些可用來源可供使用?
對於每個資料來源:
- 🟢 [P0] 資料是結構化還是非結構化?
- 🟢 [P0] 擷取資料的來源格式為何 (例如 PDF、具有影像/資料表的文件、結構化 API 回應)?
- 🟢 [P0] 該資料位於何處?
- 🟢 [P0] 有多少資料可供使用?
- 🟡 [P1] 資料更新的頻率為何? 應如何處理這些更新?
- 🟡 [P1] 每個資料來源是否有任何已知的資料品質問題或不一致?
請考慮建立詳細目錄資料表來合併這項資訊,例如:
| 資料來源 | 來源 | 檔案類型 | 大小 | 更新頻率 |
|---|---|---|---|---|
| 資料來源 1 | Unity 目錄磁碟區 | JSON | 10GB | 每日 |
| 資料來源 2 | 公用 API | XML | NA (API) | 即時 |
| 資料來源 3 | SharePoint | PDF、.docx | 500MB | 每月 |
效能條件約束
擷取 RAG 應用程式的效能和資源需求。
🟡 [P1] 產生回應的可接受延遲上限為何?
🟡 [P1] 第一個權杖可接受的最大時間為何?
🟡 [P1] 如果輸出正在進行串流,可接受的總延遲是否較高?
🟡 [P1] 計算資源是否有任何成本限制可供推斷?
🟡 [P1] 預期的使用模式和尖峰負載為何?
🟡 [P1] 系統應該能夠處理多少並行使用者或要求? Databricks 會透過使用模型服務自動調整的能力,以原生方式處理這類可擴縮性需求。
評估
建立隨著時間評估及改善 RAG 解決方案的方式。
🟢 [P0] 您想要影響的業務目標/KPI 為何? 什麼是基準值以及什麼事目標?
🟢 [P0] 哪些使用者或利害關係人會提供初始和持續的意見反應?
🟢 [P0] 應該使用哪些計量來評估產生的回應品質? Mosaic AI 代理程式評估提供一組建議使用的計量。
🟡 [P1] RAG 應用程式必須擅長哪些問題集才能進入實際執行環境?
🟡 [P1] [評估集] 是否存在? 是否可以取得使用者查詢的評估集,以及應擷取的基準真相答案和 (選用) 正確支援文件?
🟡 [P1] 如何收集並納入系統的使用者意見反應?
安全性
識別任何安全性和隱私權考量。
🟢 [P0] 是否有需要謹慎處理的敏感性/保密資料?
🟡 [P1] 存取控制是否需要在解決方案中實作 (例如,指定的使用者只能從一組受限制的文件擷取)?
部署
了解 RAG 解決方案如何整合、部署和維護。
🟡 RAG 解決方案應如何與現有的系統和工作流程整合?
🟡 模型應該如何部署、調整及進行版本設定? 本教學課程涵蓋如何使用 MLflow、Unity 目錄、代理程式 SDK 和模型服務,在 Databricks 上處理端對端生命週期。
範例
例如,請考慮這些問題如何套用至 Databricks 客戶支援小組使用的此範例 RAG 應用程式:
| 區域 | 考量 | 需求 |
|---|---|---|
| 使用者體驗 | - 互動形式。 - 一般使用者查詢範例。 - 預期的回應格式和樣式。 - 處理模棱兩可或無關的查詢。 |
- 與 Slack 整合的聊天介面。 - 範例查詢:「如何減少叢集啟動時間?」 「我有什麼樣的支援計劃?」 - 適當時,清除程式碼片段的技術回應,以及相關文件的連結。 - 必要時提供內容相關的建議,並呈報至支援工程師。 |
| 資料 | - 資料來源的數目和類型。 - 資料格式和位置。 - 資料大小和更新頻率。 - 資料品質與一致性。 |
- 三個資料來源。 - 公司文件 (HTML、PDF)。 - 已解決的支援票證 (JSON)。 - 社群論壇文章 (差異資料表)。 - 儲存在 Unity 目錄的資料,每周更新一次。 - 資料大小總計:5GB。 - 專用 DOC 與支援小組維護的資料結構和品質一致。 |
| 效能 | - 可接受延遲上限。 - 成本條件約束。 - 預期的使用方式和並行。 |
- 延遲需求上限。 - 成本條件約束。 - 預期的尖峰負載。 |
| 評估 | - 評估資料集可用性。 - 品質計量。 - 使用者意見反應收集。 |
- 來自每個產品領域的主題專家可協助檢閱輸出,並調整不正確的答案來建立評估資料集。 - 商務 KPI。 - 增加支援票證解決率。 - 減少每個支援票證花費的使用者時間。 - 品質計量。 - LLM 判斷的回答正確性和相關性。 - LLM 評委擷取精確度。 - 使用者附議或反對。 - 意見反應收集。 - 檢測 Slack 已提供讚成/反對。 |
| 安全性 | - 敏感性資料處理。 - 存取控制需求。 |
- 擷取來源中不應含有敏感性客戶資料。 - 透過 Databricks Community SSO 進行使用者驗證。 |
| 部署 | - 與現有系統整合。 - 部署與版本設定。 |
- 與支援票證系統整合。 - 部署為 Databricks 模型服務端點的鏈結。 |