Mosaic AI 向量搜尋
本文概述了Databricks的向量資料庫解決方案Mosaic AI向量搜尋,描述了該搜尋工具的功能和運作方式。
什麼是 Mosaic AI 向量搜尋?
Mosaic AI 向量搜尋是一個向量資料庫,內建於 Databricks Data Intelligence Platform,並與其治理及生產力工具整合。 向量資料庫是一種經過最佳化的資料庫,可用來儲存和擷取嵌入向量。 內嵌是資料語意內容的數學表示法,通常是文字或影像資料。 內嵌是由大型語言模型所產生,是許多衍生式 AI 應用程式的關鍵元件,相依於尋找彼此類似的檔或影像。 範例包括 RAG 系統、推薦系統,以及影像與視訊辨識。
使用馬賽克 AI 向量搜尋,您可以從 Delta 數據表建立向量搜尋索引。 索引包含內嵌資料與中繼資料。 然後,您可以使用 REST API 來查詢索引,以識別最類似的向量,並傳回相似性的文件。 您可以建構索引,以在更新基礎 Delta 資料表時自動同步處理。
馬賽克 AI 向量搜尋支援下列各項:
馬賽克 AI 向量搜尋如何運作?
Mosaic AI 向量搜尋使用階層式導航小世界 (HNSW) 演算法來進行近似鄰居搜尋,並使用L2距離量度來測量嵌入向量相似性。 如果您想要使用餘弦相似性,您需要先將資料點內嵌正常化,再將它們饋送至向量搜尋。 當資料點正常化時,L2 距離所產生的排名與餘弦相似性所產生的排名相同。
Mosaic AI 向量搜尋也支援混合式關鍵字相似性搜尋,其結合了以向量為基礎的內嵌搜尋與傳統關鍵字型搜尋技術。 此方法會比對查詢中完全符合的詞語,同時使用以向量為基礎的相似性搜尋來擷取查詢的語意關係與上下文。
藉由整合這兩種技術,混合式關鍵字相似性搜尋會擷取不僅包含完全符合關鍵字的文件,還會擷取概念上類似的文件,以提供更完整且相似性的搜尋結果。 此方法特別適用於 RAG 應用程式,其中的源數據具有唯一關鍵詞,例如 SKU 或不適合純相似性搜尋的標識符。
如需 API 的詳細資訊,請參閱 Python SDK 參考 與 查詢向量搜尋端點。
相似性搜尋計算
相似性搜尋計算會使用下列公式:
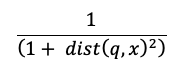
其中 dist 是查詢 q 與索引專案 x之間的 Euclidean 距離:
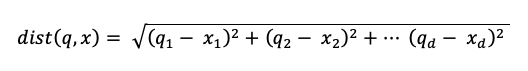
關鍵字搜尋演算法
相關性分數是使用 Okapi BM25計算。 所有文字或字串資料行都會被搜尋,包括文字或字串格式的源文字嵌入資料行和元數據資料行。 Tokenization 函數會在字邊界分割、移除標點符號,並將所有文字轉換成小寫。
如何合併相似性搜尋與關鍵字搜尋
相似性搜尋與關鍵字搜尋結果會透過互惠排名融合 (RRF) 函式結合。
RRF 會根據每個方法重新評分每個文件的分數:
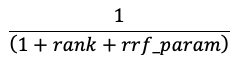
在上述方程式中,排名從 0 開始,加總每個文件的分數,並傳回最高評分的文件。
rrf_param 控制較高排名與較低排名之文件的相對重要性。 根據文獻,rrf_param 定於60。
分數正常化,因此最高分數為 1,而最低分數為 0,請使用下列方程式:
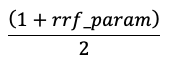
提供向量內嵌的選項
若要在 Databricks 中建立向量資料庫,您必須先決定如何提供向量內嵌。 Databricks 支援三個選項:
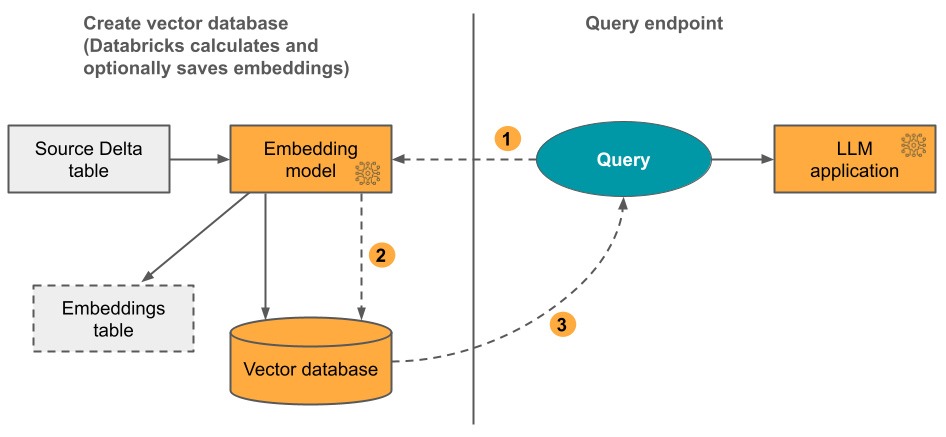
選項 1:使用 Databricks 計算的嵌入來進行 Delta 同步索引 您提供一個來源 Delta 數據表,其中包含以文字格式表示的資料。 Databricks 會使用您指定的模型來計算內嵌,並選擇性地將內嵌儲存至 Unity 目錄中的數據表。 隨著 Delta 數據表的更新,索引會與 Delta 數據表保持同步。
下圖說明此程序:
- 計算查詢內嵌。 查詢可以包含中繼資料篩選。
- 執行相似性搜尋以識別相關性的文件。
- 傳回相關性的文件,並將其附加至查詢。
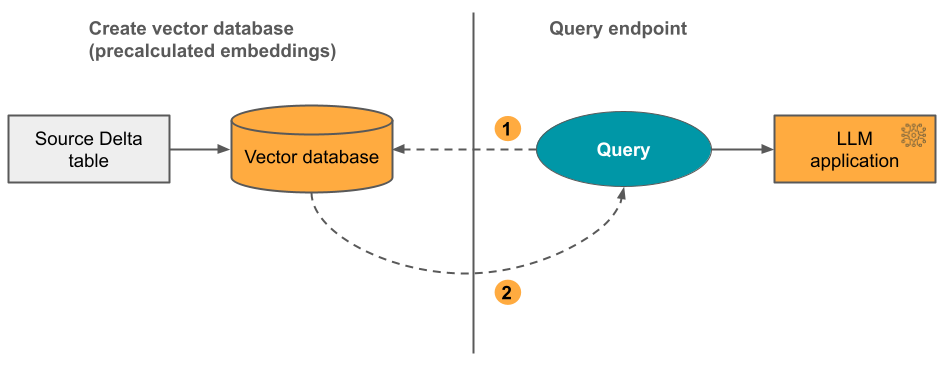
選項 2:Delta 同步索引與自行管理的嵌入 您提供包含預先計算嵌入的原始 Delta 資料表。 隨著 Delta 數據表的更新,索引會與 Delta 數據表保持同步。
下圖說明此程序:
- 查詢是由內嵌所組成,而且可以包含中繼資料篩選。
- 執行相似性搜尋以識別相關性的文件。 傳回相關性的文件,並將其附加至查詢。
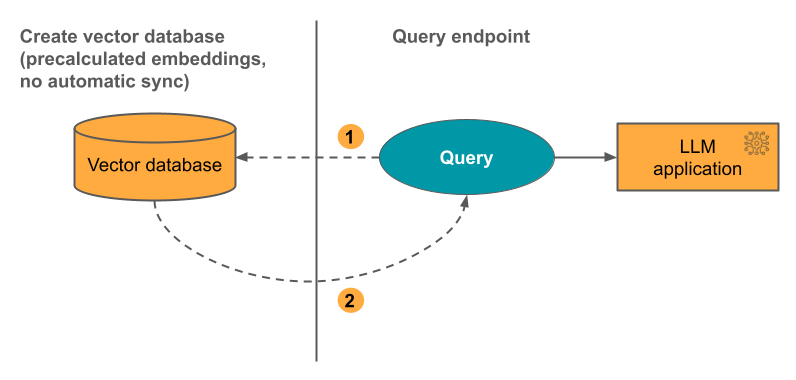
選項 3:直接向量存取索引 內嵌資料表變更時,您必須使用 REST API 手動更新索引。
下圖說明此程序:
如何設定馬賽克 AI 向量搜尋
若要使用 Mosaic AI 向量搜尋,您必須建立下列內容:
向量搜尋端點。 此端點會提供向量搜尋索引。 您可以使用 REST API 或 SDK 來查詢和更新端點。 如需指示,請參閱建立向量搜尋端點。
端點會自動擴充以支援索引的大小或同時並發請求的數量。 端點不會自動縮減。
向量搜尋索引。 向量搜尋索引是從 Delta 數據表建立,並經過優化以提供即時近似近鄰搜尋。 搜尋目標是識別類似查詢的文件。 向量搜尋索引顯示於 Unity 目錄中,並由其控管。 如需指示,請參閱建立向量搜尋索引。
此外,如果您選擇使用 Databricks 計算嵌入,您可以使用預先設定的基礎模型 API 端點,或建立端點服務模型來為您選擇的嵌入模型提供服務。 如需指示,請參閱 依令牌付費基礎模型 API 或 建立基礎模型服務端點。
若要查詢服務端點模型,您可以使用 REST API 或 Python SDK。 您的查詢可以根據 Delta 資料表中的任何數據行來定義篩選。 如需詳細資訊,請參閱在查詢中使用篩選條件、API 參考資料或 Python SDK 參考資料。
需求
- 已啟用 Unity Catalog 的工作區。
- 已啟用無伺服器計算。 如需指示,請參閱連線到無伺服器計算。
- 源數據表必須啟用變更資料饋送。 如需指示,請參閱在 Azure Databricks 使用 Delta Lake 變更資料摘要。
- 若要建立向量搜尋索引,您必須在建立索引的目錄架構上擁有 CREATE TABLE 許可權。
使用訪問控制清單來設定建立和管理向量搜尋端點的許可權。 請參閱 向量搜尋端點 ACL。
數據保護和驗證
Databricks 會實作下列安全性控制來保護您的資料:
- 客戶向 Mosaic AI 向量搜尋的每項請求都會以邏輯方式隔離、驗證及授權。
- Mosaic AI 向量搜尋對靜態資料 (AES-256) 及傳輸中的資料 (TLS 1.2+) 進行加密。
Mosaic AI 向量搜尋支援兩種驗證模式:
服務原則令牌。 系統管理員可以產生服務主體令牌,並將其傳遞至 SDK 或 API。 請參閱使用服務主體。 針對生產使用案例,Databricks 建議使用服務主體憑證。
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )個人存取令牌。 您可以使用個人存取令牌向馬賽克 AI 向量搜尋進行驗證。 請參閱個人存取驗證權杖。 如果您在筆記本環境中使用 SDK,SDK 會自動產生 PAT 令牌以進行驗證。
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
在 2024 年 5 月 8 日或之後建立的端點,支援客戶自控金鑰 (CMK)。
監控使用量與成本
計費使用量系統數據表可讓您監視與向量搜尋索引和端點相關聯的使用量和成本。 查詢範例如下:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
如需計費使用量資料表內容的詳細資訊,請參閱 計費使用量系統資料表參考。 以下範例筆記本中有更多查詢。
向量式搜尋系統中的表格查詢筆記本
資源和資料大小限制
下表摘要說明向量搜尋端點和索引的資源和資料大小限制:
| 資源 | 細微性 | 限制 |
|---|---|---|
| 向量搜尋端點 | 每個工作區 | 100 |
| 嵌入表示 | 每個端點 | 320000000 |
| 嵌入維度 | 每個索引 | 4096 |
| 索引 | 每個端點 | 50 |
| 列 | 每個索引 | 50 |
| 列 | 支援類型:位元組、短整數、整數、長整數、浮點數、雙精度、布林值、字串、時間戳記、日期 | |
| 中繼資料欄位 | 每個索引 | 50 |
| 索引名稱 | 每個索引 | 128 個字元 |
下列限制適用於建立和更新向量搜尋索引:
| 資源 | 粒度 | 限制 |
|---|---|---|
| 差異同步索引的資料列大小 | 每個索引 | 100KB |
| Delta同步索引的嵌置源數據列大小 | 每個索引 | 32764 位元組 |
| 直接向量索引的大量插入請求大小限制 | 每個索引 | 10MB |
| 直接向量索引批次刪除請求的大小上限 | 每個索引 | 10MB |
下列限制適用於查詢 API。
| 資源 | 粒度 | 限制 |
|---|---|---|
| 查詢文字長度 | 每個查詢 | 32764 位元組 |
| 傳回結果數量上限 | 每個查詢 | 1萬 |
限度
不支援列和欄層級權限。 然而,您可以使用篩選 API 來實作自己的應用層級 ACL。