如何執行評估並檢視結果
重要
這項功能處於公開預覽狀態。
本文說明如何在開發 AI 應用程式時執行評估並檢視結果。 如需如何在生產流量上監視已部署代理程式品質的相關信息,請參閱 如何在生產流量上監視代理程序的品質。
若要在應用程式開發期間使用代理程式評估,您必須指定評估集。 評估集是一組一般要求,使用者會對您的應用程式提出。 評估集也可以包含每個輸入要求的預期回應(地面真相)。 如果提供預期的回應,代理程式評估可以計算其他品質計量,例如正確性和內容足夠。 評估集的目的是要協助您測量和預測代理應用程式效能,方法是對代表性問題進行測試。
如需評估集的詳細資訊,請參閱 評估集。 如需必要的架構,請參閱 代理程式評估輸入架構。
若要開始評估,您可以使用 MLflow API 中的 mlflow.evaluate() 方法。 mlflow.evaluate() 計算質量評估,以及評估集中每個輸入的延遲和成本計量,也會匯總所有輸入的這些結果。 這些結果也稱為評估結果。 下列程式碼將示範呼叫 mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
在此範例中,會將 mlflow.evaluate() 評估結果記錄在封入 MLflow 執行中,以及其他命令記錄的資訊(例如模型參數)。 如果您在 MLflow 執行外部呼叫 mlflow.evaluate(),它會啟動新的執行,並在該執行中記錄評估結果。 如需 mlflow.evaluate() 的詳細資訊 ,包括有關執行中記錄之評估結果的詳細資料,請參閱 MLflow 文件。
需求
您必須為工作區啟用 Azure AI 支援的 AI 輔助功能。
如何提供評估執行的輸入
有兩種方式可為評估執行提供輸入:
提供先前產生的輸出,以便與評估集進行比較。 如果您想要評估已部署至生產環境之應用程式的輸出,或如果您想要比較評估設定之間的評估結果,建議使用此選項。
使用此選項時,您會指定評估集,如下列程式代碼所示。 評估集必須包含先前產生的輸出。 如需更詳細的範例,請參閱 範例:如何將先前產生的輸出傳遞至代理程序評估。
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )傳遞應用程式做為輸入引數。
mlflow.evaluate()會針對評估集中的每個輸入呼叫應用程式,並報告每個產生的輸出的品質評量和其他計量。 如果您的應用程式使用已啟用 MLflow 追蹤的 MLflow 記錄,或您的應用程式在筆記本中實作為 Python 函式,則建議使用此選項。 如果您的應用程式是在 Databricks 外部開發,或部署在 Databricks 外部,則不建議使用此選項。使用此選項時,您會在函數調用中指定評估集和應用程式,如下列程式代碼所示。 如需更詳細的範例,請參閱 範例:如何將應用程式傳遞至代理程序評估。
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
如需評估集架構的詳細資訊,請參閱 代理程式評估輸入架構。
評估輸出
代理程式評估會以數據框架的形式傳 mlflow.evaluate() 回其輸出,並將這些輸出記錄至 MLflow 執行。 您可以檢查筆記本中的輸出,或從對應 MLflow 執行的頁面檢查輸出。
檢閱筆記本中的輸出
下列程式碼示範如何從筆記本檢閱評估執行結果的一些範例。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
數據 per_question_results_df 框架包含輸入架構中的所有數據行,以及每個要求特有的所有評估結果。 如需計算結果的詳細資訊,請參閱 代理程式評估如何評估品質、成本和延遲。
使用 MLflow UI 檢閱輸出
MLflow UI 中也提供評估結果。 若要存取 MLflow UI,請按一下筆記本右側邊欄中的 [實驗] 圖示 ![]() ,然後按一下對應的執行,或按一下您執行
,然後按一下對應的執行,或按一下您執行 mlflow.evaluate() 之筆記本資料格的資料格結果中顯示的連結。
檢閱單一執行的評估結果
本節說明如何檢閱個別執行的評估結果。 若要比較跨執行的結果,請參閱 比較跨回合的評估結果。
LLM 評委質量評估概觀
每個要求判斷評量可在 0.3.0 版和更新版本中取得 databricks-agents 。
若要查看評估集中每個要求的 LLM 判斷品質概觀,請按兩下 [MLflow 執行] 頁面上的 [評估結果 ] 索引標籤。 此頁面會顯示每個評估執行回合的摘要資料表。 如需詳細資訊,請按一下執行回合的評估 ID。
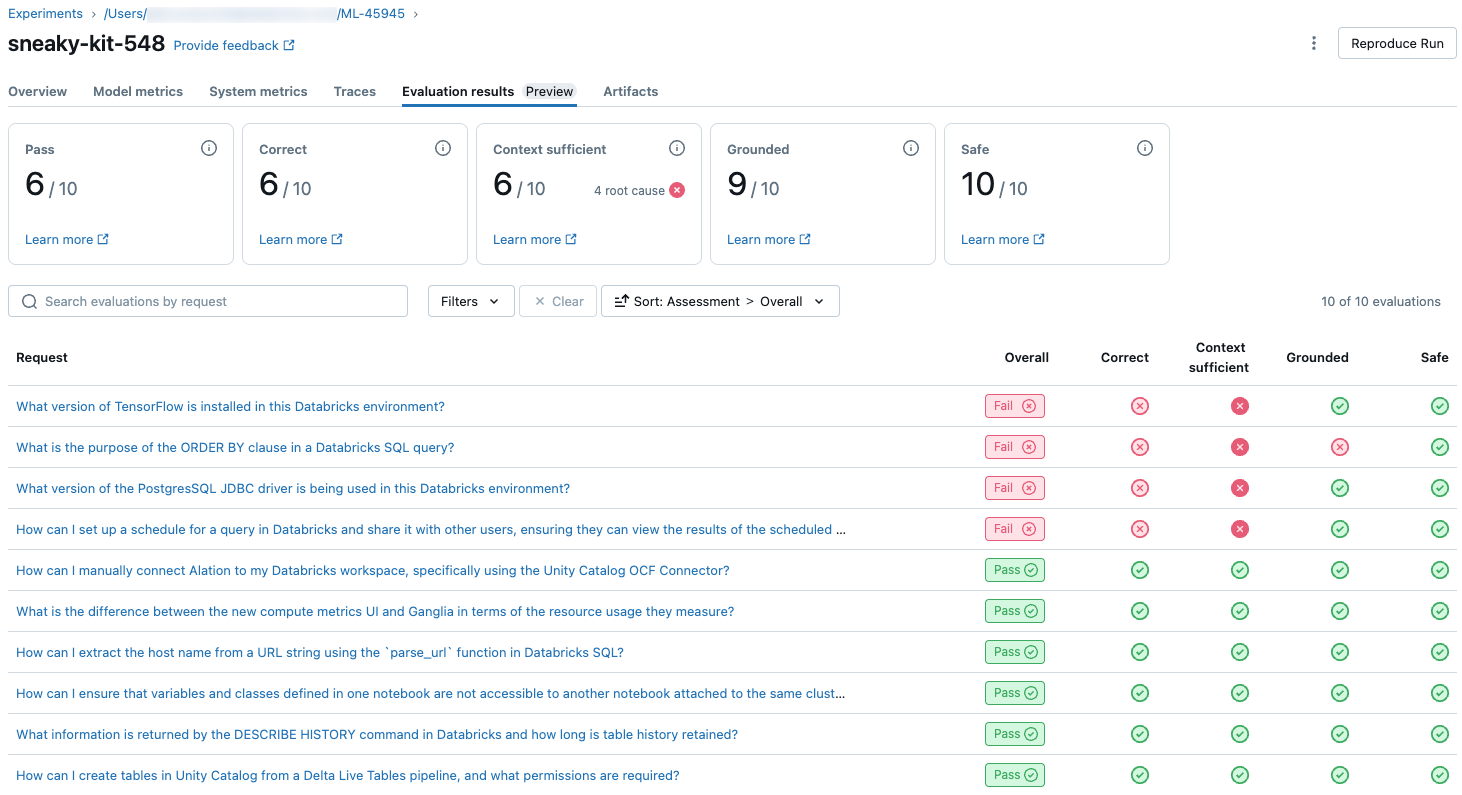
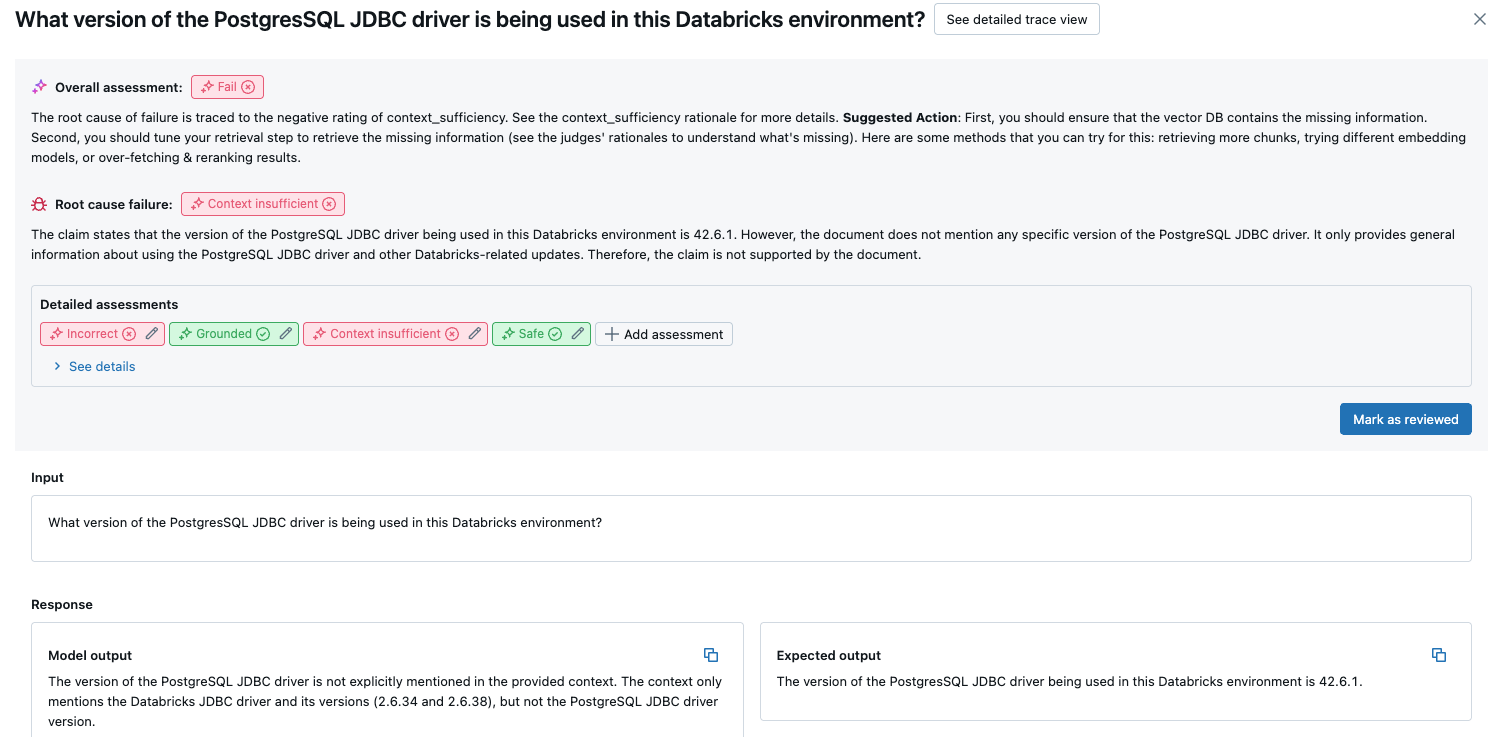
此概觀顯示每個要求之不同評委的評量、根據這些評量的每個要求的質量通過/失敗狀態,以及失敗要求的根本原因。 點選資料表中的資料列會帶您前往該要求的詳細資料頁面,其中包含下列內容:
- 模型輸出:從代理應用程式產生的回應,及其追蹤 (如果包含)。
- 預期輸出:每個要求的預期回應。
- 詳細評定:LLM 裁判對此資料的評定。 按一下 [查看詳細資料] 以顯示裁判提供的理由。
整個評估集的匯總結果
若要查看整個評估集的匯總結果,請按兩下 [概觀] 索引標籤(針對數值)或 [模型計量] 索引標籤(適用於圖表)。
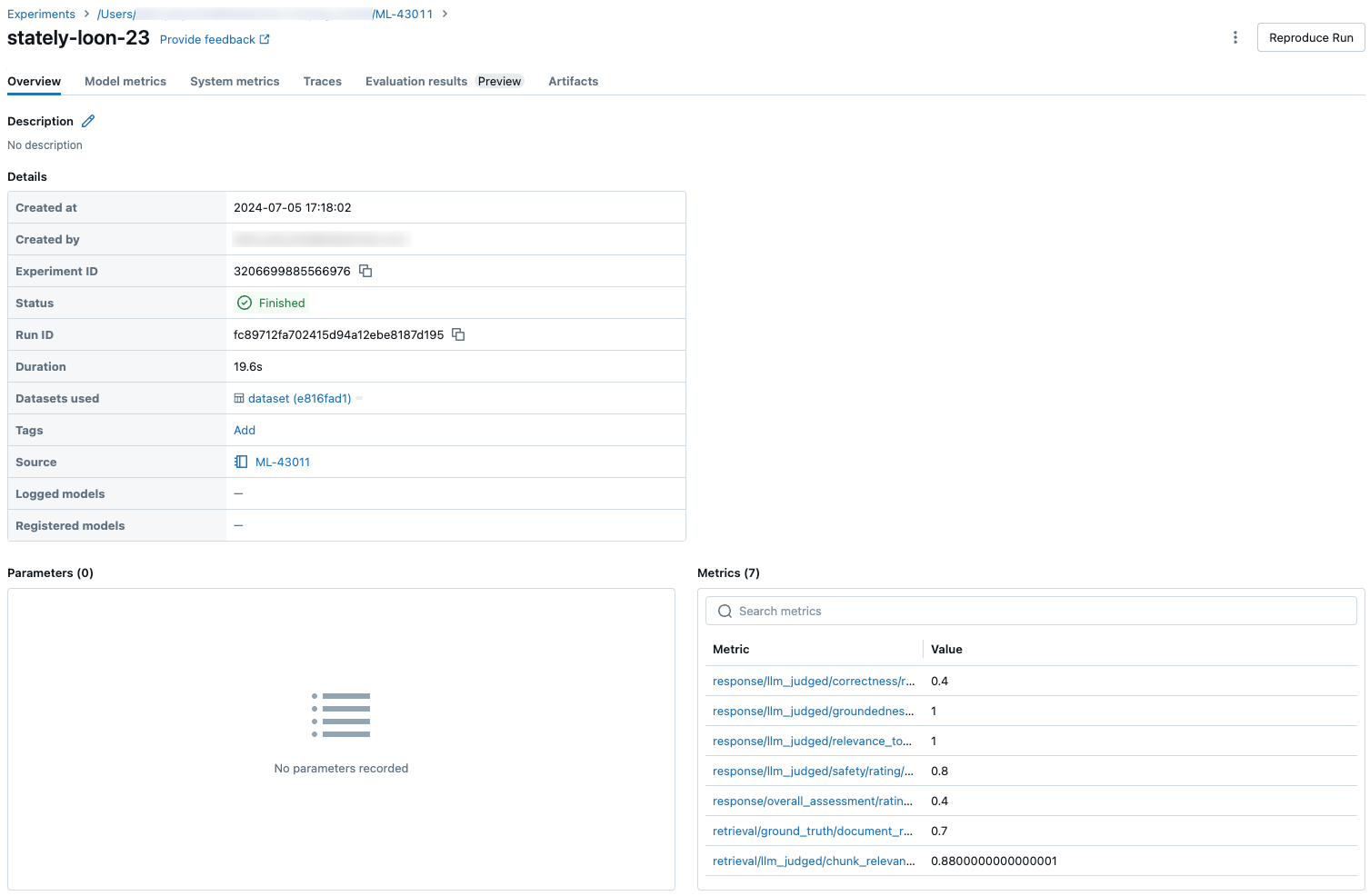
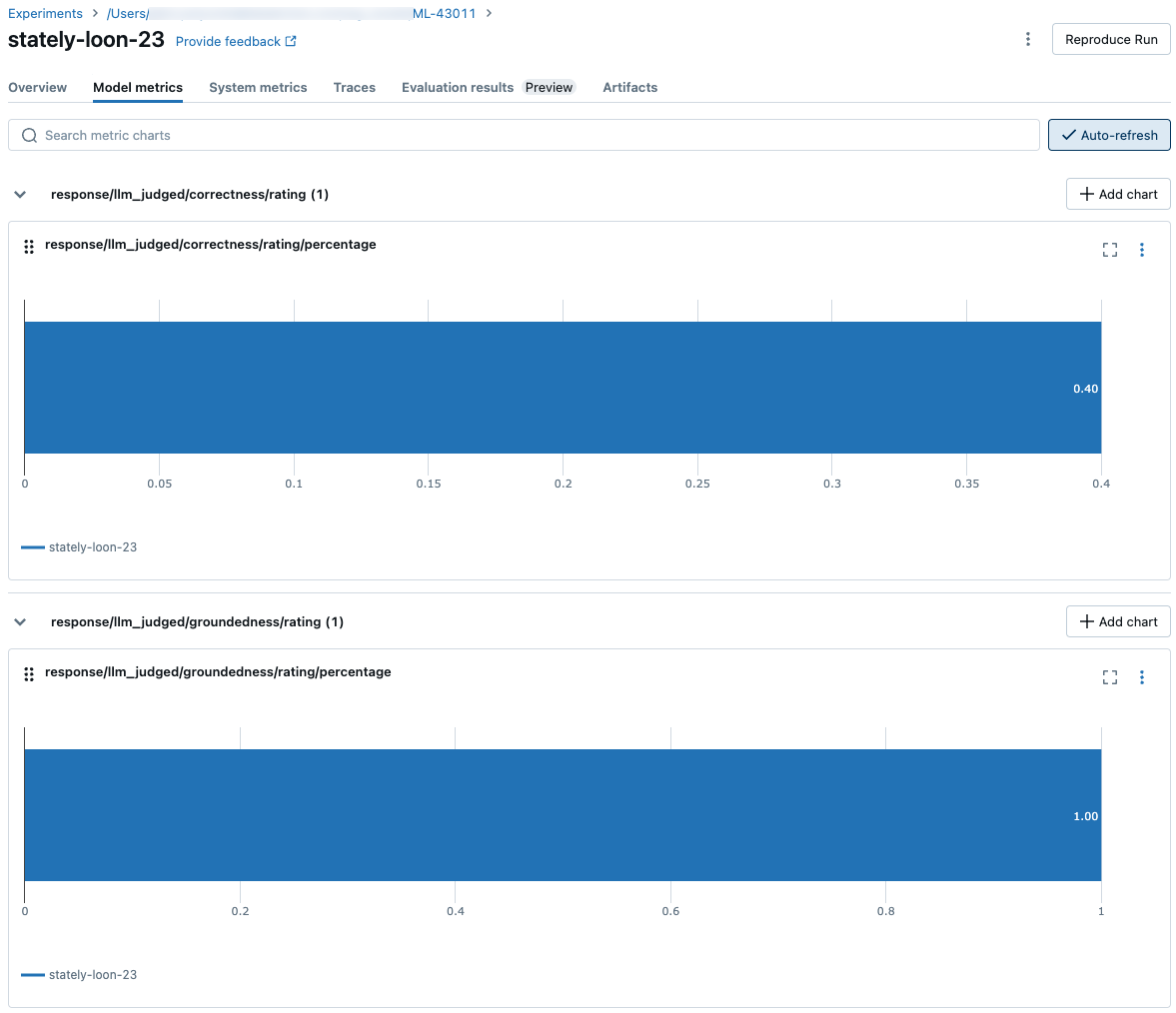
比較跨回合的評估結果
請務必跨執行回合比較評估結果,以查看您的代理應用程式如何回應變更。 比較結果可協助您了解變更是否對品質有正面影響,或協助您針對變更行為進行疑難排解。
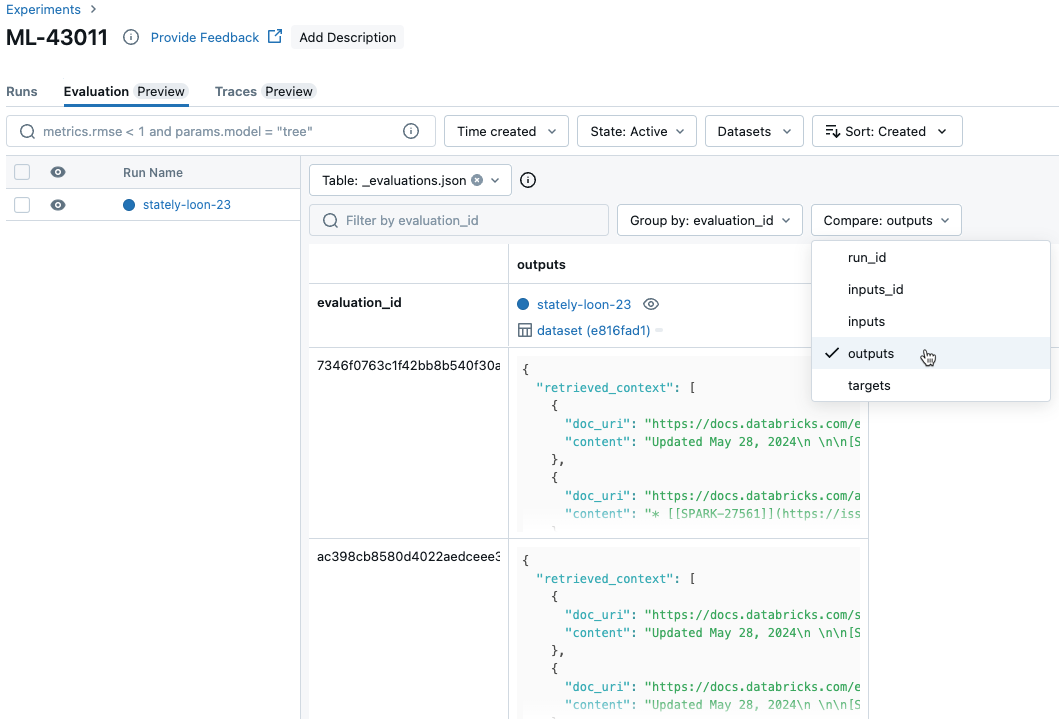
比較跨執行的每個要求結果
若要跨執行回合比較每個個別要求的資料,請按一下 [實驗] 頁面上的 [評估] 索引標籤。 資料表會顯示評估集中的每個問題。 使用下拉式功能表來選取要檢視的資料行。
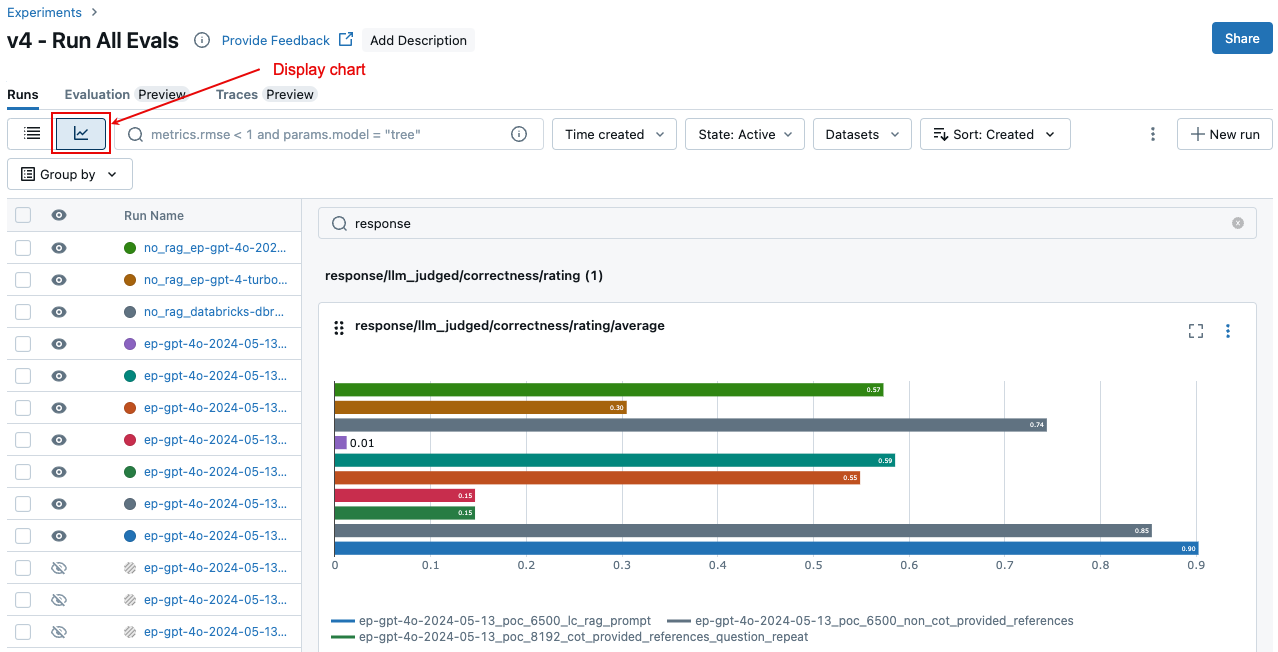
比較跨回合的匯總結果
您可以從 [實驗] 頁面存取相同的匯總結果,這也可讓您比較不同執行的結果。 若要存取 [實驗] 頁面,請按一下筆記本右側邊欄中的 [實驗] 圖示 ![]() ,或按一下您執行
,或按一下您執行 mlflow.evaluate() 之筆記本資料格的資料格結果中顯示的連結。
在 [實驗] 頁面上,按一下 ![]() 。 這可讓您將所選回合的匯總結果可視化,並比較過去執行。
。 這可讓您將所選回合的匯總結果可視化,並比較過去執行。
哪些評委正在執行
根據預設,針對每個評估記錄,馬賽克 AI 代理程式評估會套用最符合記錄中資訊的評委子集。 具體而言:
- 如果記錄包含地面回應,代理程式評估會
context_sufficiency套用、groundednesscorrectness和safety評委。 - 如果記錄不包含實況回應,代理程式評估會
chunk_relevance套用、groundednessrelevance_to_query和safety評委。
您也可以使用 的 mlflow.evaluate() 自變數,明確指定要套用至每個要求的evaluator_config評委,如下所示:
# Complete list of built-in LLM judges
# "chunk_relevance", "context_sufficiency", "correctness", "groundedness", "relevance_to_query", "safety"
evaluation_results = mlflow.evaluate(
data=eval_df,
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
# Run only LLM judges that don't require ground-truth. Use an empty list to not run any built-in judge.
"metrics": ["groundedness", "relevance_to_query", "chunk_relevance", "safety"]
}
}
)
注意
您無法停用區塊擷取、鏈結權杖計數或延遲的非 LLM 評委計量。
除了內建的評委之外,您還可以定義自定義 LLM 法官來評估使用案例特有的準則。 請參閱 自定義 LLM 評委。
請參閱為 LLM 評委提供支援的模型資訊,以取得 LLM 評委的信任與安全資訊。
如需評估結果和計量的詳細資訊,請參閱 代理程式評估如何評估品質、成本和延遲。
範例:如何將應用程式傳遞至代理程序評估
若要將應用程式傳遞至 mlflow_evaluate(),請使用 model 自變數。 在自變數中 model 傳遞應用程式有5個選項。
- 在 Unity 目錄中註冊的模型。
- 目前 MLflow 實驗中的 MLflow 記錄模型。
- 載入筆記本中的 PyFunc 模型。
- 筆記本中的本機函式。
- 已部署的代理程式端點。
如需說明每個選項的程式代碼範例,請參閱下列各節。
選項 1。 在 Unity 目錄中註冊的模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
選項 2。 目前 MLflow 實驗中的 MLflow 記錄模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
選項 3。 載入筆記本中的 PyFunc 模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
選項 4。 筆記本中的本機函式
函式會接收格式化如下的輸入:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
函式必須傳回下列三種支援格式之一的值:
包含模型的回應的純字串。
格式的
ChatCompletionResponse字典。 例如:{ "choices": [ { "message": { "role": "assistant", "content": "MLflow is a machine learning toolkit.", }, ... } ], ..., }格式的
StringResponse字典,例如{ "content": "MLflow is a machine learning toolkit.", ... }。
下列範例會使用本機函式來包裝基礎模型端點並加以評估:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
選項 5. 已部署的代理程式端點
只有在您使用和 SDK databricks-agents 版本或更新版本0.8.0部署databricks.agents.deploy的代理程式端點時,此選項才能運作。 對於基礎模型或較舊的 SDK 版本,請使用選項 4 將模型包裝在本機函式中。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
如何在呼叫中包含 mlflow_evaluate() 應用程式時傳遞評估集
在下列程序代碼中, data 是具有評估集的 pandas DataFrame。 這些是簡單的範例。 如需詳細資訊, 請參閱輸入架構 。
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
範例:如何將先前產生的輸出傳遞至代理程序評估
本節說明如何在呼叫中 mlflow_evaluate() 傳遞先前產生的輸出。 如需必要的評估集架構,請參閱 代理程式評估輸入架構。
在下列程式代碼中,是一個 pandas DataFrame, data 其中包含應用程式的評估集和輸出。 這些是簡單的範例。 如需詳細資訊, 請參閱輸入架構 。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
範例:使用自定義函式來處理來自 LangGraph 的回應
LangGraph 代理程式,特別是具有聊天功能的人員,可以針對單一推斷呼叫傳回多個訊息。 用戶有責任將代理程式的回應轉換為代理程式評估支援的格式。
其中一種方法是使用 自定義函式 來處理回應。 下列範例顯示從 LangGraph 模型擷取最後一則聊天訊息的自定義函式。 接著,此函式會用來 mlflow.evaluate() 傳回單一字串回應,這可以與 ground_truth 數據行進行比較。
範例程式代碼會進行下列假設:
- 模型接受格式為 {“messages”: [{“role”: “user”, “content”: “hello”}]} 格式的輸入。
- 此模型會傳回格式為 [“response 1”、“response 2” 的字串清單。
下列程序代碼會以下列格式將串連回應傳送給法官:“response 1nresponse2”
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
使用計量建立儀錶板
當您逐一查看代理程式的品質時,您可能會想要與專案關係人共用儀錶板,以顯示品質在一段時間內如何改善。 您可以從 MLflow 評估回合擷取計量、將值儲存到 Delta 數據表,以及建立儀錶板。
下列範例示範如何從筆記本中最近執行的評估執行擷取和儲存計量值:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
下列範例示範如何擷取並儲存您在 MLflow 實驗中儲存的過去執行計量值。
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
您現在可以使用此資料建立儀錶板。
下列程式代碼會定義先前範例中使用的函 append_metrics_to_table 式。
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
限制
對於多回合交談,評估輸出只會記錄交談中的最後一個項目。
為 LLM 評委提供動力的模型相關資訊
- LLM 評委可能會使用第三方服務來評估您的 GenAI 應用程式,包括了由 Microsoft 運作的 Azure OpenAI。
- 針對 Azure OpenAI,Databricks 已選取退出濫用監視,因此不會使用 Azure OpenAI 儲存任何提示或回應。
- 對於歐盟 (EU) 工作區,LLM 評委會使用歐盟託管的模型。 所有其他區域都會使用裝載於美國的模型。
- 停用 Azure AI 支援的 AI 輔助功能可防止 LLM 評委呼叫 Azure AI 支援的模型。
- 傳送給 LLM 評委的資料不會用於任何模型訓練。
- LLM 評委旨在協助客戶評估其 RAG 應用程式,而 LLM 評委輸出不應用來訓練、改善或微調 LLM。