MLflow 追蹤的代理程式可觀察性
本文說明如何使用 Databricks 上的 MLflow 追蹤,將可檢視性新增至您的產生 AI 應用程式。
什麼是 MLflow 追蹤?
MLflow 跟踪 提供從開發到部署的端對端生成式 AI 應用程式觀察能力。 追蹤功能與 Databricks 的生成式 AI 工具組全面整合,能夠在整個開發和生產生命週期內捕捉詳細深入的洞見。
以下是在 Gen AI 應用程式中追蹤的主要使用案例:
簡化偵錯:追蹤可讓您更輕鬆瞭解 Gen AI 應用程式的每個步驟,讓您更輕鬆地診斷和解決問題。
離線評估:追蹤會產生寶貴的代理評估數據,讓您能夠測量並隨著時間改善代理的品質。
生產監視:追蹤可讓您查看代理程式行為和詳細的執行步驟,讓您監視及優化生產中的代理程式效能。
稽核記錄:MLflow 追蹤會產生代理程式動作和決策的完整稽核記錄。 這對於確保發生非預期問題時的合規性和支持偵錯至關重要。
需求
MLflow 追蹤可在 MLflow 2.13.0 版和更新版本上使用。 Databricks 建議安裝最新版的 MLflow,以存取最新的功能和改進。
%pip install mlflow>=2.13.0 -qqqU
%restart_python
自動追蹤
MLflow 自動記錄 可讓您將單行新增至程式代碼,以快速檢測代理程式,mlflow.<library>.autolog()。
MLflow 支援對大多數受歡迎的代理編寫庫進行自動紀錄。 如需有關各個撰寫庫的詳細資訊,請參閱 MLflow 自動記錄功能說明文件:
| 圖書館 | 自動記錄版本支援 | 自動記錄命令 |
|---|---|---|
| LangChain | 0.1.0 ~ 最新 | mlflow.langchain.autolog() |
| Langgraph | 0.1.1 ~ 最新 | mlflow.langgraph.autolog() |
| OpenAI | 1.0.0 ~ 最新 | mlflow.openai.autolog() |
| LlamaIndex | 0.10.44 ~ 最新 | mlflow.llamaindex.autolog() |
| DSPy | 2.5.17 ~ 最新 | mlflow.dspy.autolog() |
| Amazon Bedrock | 1.33.0 ~ 最新版 (boto3) | mlflow.bedrock.autolog() |
| 人類 | 0.30.0 ~ 最新 | mlflow.anthropic.autolog() |
| AutoGen | 0.2.36 ~ 0.2.40 | mlflow.autogen.autolog() |
| Google Gemini | 1.0.0 ~ 最新 | mlflow.gemini.autolog() |
| CrewAI | 0.80.0 ~ 最新 | mlflow.crewai.autolog() |
| LiteLLM | 1.52.9 ~ 最新 | mlflow.litellm.autolog() |
| Groq | 0.13.0 ~ 最新 | mlflow.groq.autolog() |
| 密史特拉 | 1.0.0 ~ 最新 | mlflow.mistral.autolog() |
停用自動記錄
在 Databricks Runtime 15.4 ML 及以上版本中,以下函式庫預設會啟用自動記錄追蹤功能:
- LangChain
- Langgraph
- OpenAI
- LlamaIndex
若要停用這些連結庫的自動記錄追蹤,請在筆記本中執行下列命令:
`mlflow.<library>.autolog(log_traces=False)`
手動新增痕跡
雖然自動記錄提供方便的方式檢測代理程式,但您可能會想要更細微地檢測代理程式,或新增自動記錄不會擷取的其他追蹤。 在這些情況下,請使用 MLflow 追蹤 API 手動新增追蹤。
MLflow 追蹤 API 是用於新增追蹤的低程式代碼 API,而不必擔心管理追蹤的樹狀結構。 MLflow 會利用 Python 堆疊自動確定適當的父級/子級跨度關係。
結合自動記錄和手動追蹤
手動追蹤 API 可以搭配自動記錄使用。 MLflow 結合由自動記錄和手動追蹤所建立的跨度,以建立代理執行的完整追蹤。 如需結合自動記錄和手動追蹤的範例,請參閱 使用 MLflow 追蹤配置叫用代理的工具。
使用 @mlflow.trace 裝飾器進行函式追蹤
手動為程式代碼添加監控的最簡單方法是使用 @mlflow.trace 裝飾器來修飾一個函式。
MLflow 追蹤裝飾器 會建立一個與裝飾函式範圍相關的「區段」,此區段代表追蹤中的執行單位,並顯示為追蹤視覺化中的單一行。 範圍會擷取函式的輸入和輸出、延遲,以及從函式引發的任何例外狀況。
例如,下列程式代碼會建立名為 my_function 的範圍,以擷取輸入自變數 x 和 y 和輸出。
import mlflow
@mlflow.trace
def add(x: int, y: int) -> int:
return x + y
您也可以自訂範圍名稱、範圍類型,以及將自訂屬性新增至範圍:
from mlflow.entities import SpanType
@mlflow.trace(
# By default, the function name is used as the span name. You can override it with the `name` parameter.
name="my_add_function",
# Specify the span type using the `span_type` parameter.
span_type=SpanType.TOOL,
# Add custom attributes to the span using the `attributes` parameter. By default, MLflow only captures input and output.
attributes={"key": "value"}
)
def add(x: int, y: int) -> int:
return x + y
使用內容管理員追蹤任意程式代碼區塊
若要為任意程式代碼區塊建立範圍,而不只是函式,請使用 mlflow.start_span() 做為包裝程式代碼區塊的內容管理員。 範圍會在進入上下文時開始,並在退出上下文時結束。 應該手動使用上下文管理員所產生的 span 物件的 setter 方法來提供 span 的輸入和輸出。 如需詳細資訊,請參閱 MLflow 文件 - 上下文處理程式。
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
低層次的追蹤函式庫
MLflow 也提供低階 API,以明確控制追蹤樹狀結構。 請參閱 MLflow 檔案 - 手動偵測。
追蹤範例:結合自動記錄和手動追蹤
下列範例結合 OpenAI 自動記錄和手動追蹤,以完整檢測工具呼叫代理程式。
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
client = OpenAI()
# Enable OpenAI autologging to capture LLM API calls
# (*Not necessary if you are using the Databricks Runtime 15.4 ML and above, where OpenAI autologging is enabled by default)
mlflow.openai.autolog()
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool-calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model requests tool calls, invoke the function(s) with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
使用標籤標註記錄追蹤
MLflow 追蹤標籤 是鍵值對,可讓您將自定義的元數據新增至追蹤,例如交談標識碼、使用者標識碼、Git 提交哈希等。標籤顯示在 MLflow UI 中,讓您可以篩選和搜尋追蹤。
標記可以使用 MLflow API 或 MLflow UI 設定為進行中或已完成的追蹤。 下列範例示範如何使用 mlflow.update_current_trace() API 將標記新增至進行中的追蹤。
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
若要深入瞭解標記追蹤,以及如何使用它們來篩選和搜尋追蹤,請參閱 MLflow 文件 - 設定追蹤標籤。
檢視追蹤
若要在執行代理後檢閱追蹤,請使用以下其中一個選項:
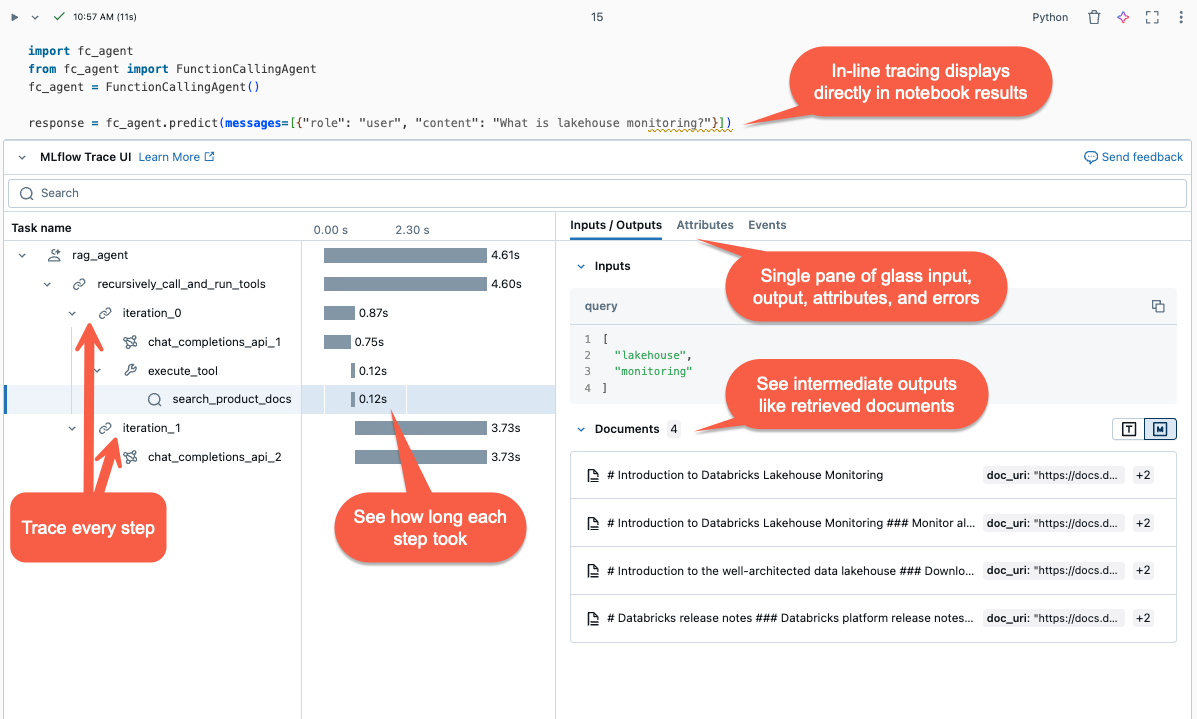
- 內嵌視覺化:在 Databricks 筆記本中,追蹤會內嵌呈現在單元格輸出中。
- MLflow 實驗:在 Databricks 中,前往 實驗> 選擇實驗 >跟蹤 以檢視和搜尋該實驗的所有記錄。
- MLflow 運行:當代理程式在活躍的 MLflow 運行下執行時,追蹤會出現在 MLflow UI 的 [運行] 頁面上。
- 代理程式評估 UI:在馬賽克 AI 代理程式評估中,您可以在評估結果中點擊 查看詳細的執行記錄檢視 來檢閱每個代理程式的執行記錄。
- 追蹤搜尋 API:若要以程式設計方式擷取追蹤,請使用 追蹤搜尋 API。
使用追蹤評估代理程式
追蹤資料可作為評估代理人的重要資源。 藉由擷取模型執行的詳細資訊,MLflow 追蹤在離線評估中至關重要。 您可以使用追蹤數據,針對黃金數據集評估代理程式的效能、找出問題,以及改善代理程式的效能。
%pip install -U mlflow databricks-agents
%restart_python
import mlflow
# Get the recent 50 successful traces from the experiment
traces = mlflow.search_traces(
max_results=50,
filter_string="status = 'OK'",
)
traces.drop_duplicates("request", inplace=True) # Drop duplicate requests.
traces["trace"] = traces["trace"].apply(lambda x: x.to_json()) # Convert the trace to JSON format.
# Evaluate the agent with the trace data
mlflow.evaluate(data=traces, model_type="databricks-agent")
若要深入了解代理評估,請參閱 執行評估並檢視結果。
使用推斷數據表監視已部署的代理程式
將代理程式部署至馬賽克 AI 模型服務之後,您可以使用 推斷數據表 來監視代理程式。 推斷數據表包含來自檢閱應用程式的要求、回應、代理程序追蹤和代理程式意見反應的詳細記錄。 這項資訊可讓您偵錯問題、監視效能,以及建立用於離線評估的黃金數據集。
若要開啟代理程式部署的推斷資料表,請參閱 啟用 AI 代理程式的推斷資料表。
查詢線上追蹤
使用筆記本來查詢推斷數據表並分析結果。
若要將追蹤可視化,請執行 display(<the request logs table>) 並選取要檢查的數據列:
# Query the inference table
df = spark.sql("SELECT * FROM <catalog.schema.my-inference-table-name>")
display(df)
監視代理程式
請參閱 如何監控您的 Gen AI 應用程式。
追蹤額外負荷延遲
追蹤紀錄是以異步方式寫入,以降低效能影響。 不過,追蹤仍會對端點回應速度增加延遲,特別是當每個推斷要求的追蹤大小很大時。 Databricks 建議先測試您的端點,以瞭解部署至生產環境前的追蹤延遲影響。
下表提供追踪大小對延遲影響的大致估算:
| 每個請求的跟蹤大小 | 回應速度延遲的影響 (毫秒) |
|---|---|
| 約10 KB | ~1 毫秒 |
| ~ 1 MB | 50 ~ 100 毫秒 |
| 10 MB | 150 毫秒 ~ |
故障排除
如需疑難解答和常見問題,請參閱 MLflow 文件:追蹤操作指南 和 MLflow 文件:常見問題