使用 Azure Data Factory 將資料從內部部署 Hadoop 叢集移轉至 Azure 儲存體
適用於: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
Azure Data Factory 提供具效能、強固,且符合成本效益的機制,以將資料從內部部署 HDFS 大規模移轉至 Azure Blob 儲存體或 Azure Data Lake Storage Gen2。
Data Factory 提供兩種將資料從內部部署 HDFS 移轉至 Azure 的基本方法。 您可以根據您的案例選取方法。
- Data Factory DistCp 模式 (建議):在 Data Factory 中,您可以使用 DistCp (分散式複製) 將檔案依原狀複製到 Azure Blob 儲存體 (包括分段複製) 或 Azure Data Lake Store Gen2。 使用與 DistCp 整合的 Data Factory,利用現有的強大叢集來達到最佳的複製輸送量。 您也可以從 Data Factory 獲得彈性排程和統一監視體驗的優點。 根據 Azure Data Factory 組態而定,複製活動會自動建構 distcp 命令,並且將資料提交至 Hadoop 叢集,然後監視複製狀態。 建議使用 Data Factory DistCp 模式,將資料從內部部署 Hadoop 叢集移轉至 Azure。
- Data Factory 原生整合執行階段模式:DistCp 並非適合所有案例的選項。 例如,在 Azure 虛擬網路環境中,DistCp 工具不支援使用 Azure 儲存體虛擬網路端點的 Azure ExpressRoute 私人對等互連。 此外,在某些情況下,您不想要使用現有的 Hadoop 叢集作為移轉資料的引擎,因此不會對叢集造成大量負載,這可能會影響現有 ETL 作業的效能。 您可以改為使用 Data Factory 整合執行階段的原生功能,作為將資料從內部部署 HDFS 複製到 Azure 的引擎。
本文提供這兩種方法的下列資訊:
- 效能
- 複本恢復功能
- 網路安全性
- 高階解決方案架構
- 實作最佳做法
效能
在 Data Factory DistCp 模式中,輸送量與單獨使用 DistCp 工具相同。 Data Factory DistCp 模式會將現有 Hadoop 叢集的容量最大化。 您可以使用 DistCp 進行大型叢集間或叢集內部複製。
DistCp 使用 MapReduce 來影響其散發、錯誤處理和復原以及報告。 會將檔案和目錄清單展開為工作對應的輸入。 每個工作都會複製來源清單中指定的檔案分割。 您可以使用與 DistCp 整合的 Data Factory 來建置管線,以充分利用您的網路頻寬、儲存體 IOPS 和頻寬,以將環境的資料移動輸送量最大化。
Data Factory 原生整合執行階段模式也允許不同層級的平行處理原則。 您可以使用平行處理原則來充分利用網路頻寬、儲存體 IOPS 和頻寬,將資料移動輸送量最大化:
- 單一複製活動可以利用可調整的計算資源。 透過自我裝載整合執行階段,您可以手動擴大電腦,或擴增至多部電腦 (最多四個節點)。 單一複製活動會將其檔案集分割到所有節點。
- 單一複製活動會使用多個執行緒來從資料存放區讀取和寫入至資料存放區。
- Data Factory 控制流程可以平行啟動多個複製活動。 例如,您可以使用 For Each 迴圈。
如需詳細資訊,請參閱複製活動效能指南。
復原能力
在 Data Factory DistCp 模式中,您可以針對不同層級的復原能力使用不同的 DistCp 命令列參數 (例如,-i 以忽略失敗,或 -update 當來源檔案和目的地檔案的大小不同時寫入資料)。
在 Data Factory 原生整合執行階段模式的單一複製活動執行中,Data Factory 具有內建的重試機制。 可以處理資料存放區或基礎網路中特定層級的暫時性失敗。
從內部部署 HDFS 到 Blob 儲存體,以及從內部部署 HDFS 到 Data Lake Store Gen2 進行二進位檔複製時,Data Factory 會自動執行大型範圍的檢查點檢查。 如果複製活動執行失敗或逾時,在後續的重試 (請確定重試計數 > 1),複製會從最後一個失敗點繼續,而不是從頭開始。
網路安全性
根據預設,Data Factory 會透過 HTTPS 通訊協定使用加密連線將資料從內部部署 HDFS 傳輸到 Blob 儲存體或 Azure Data Lake Storage Gen2。 HTTPS 會提供傳輸中的資料加密,並可防止竊聽和中間人攻擊。
或者,如果您為了提高安全性,不想透過公用網際網路傳輸資料,您可以透過 ExpressRoute 以私人對等互連連結傳輸資料。
解決方案架構
此影像描述透過公用網際網路移轉資料:
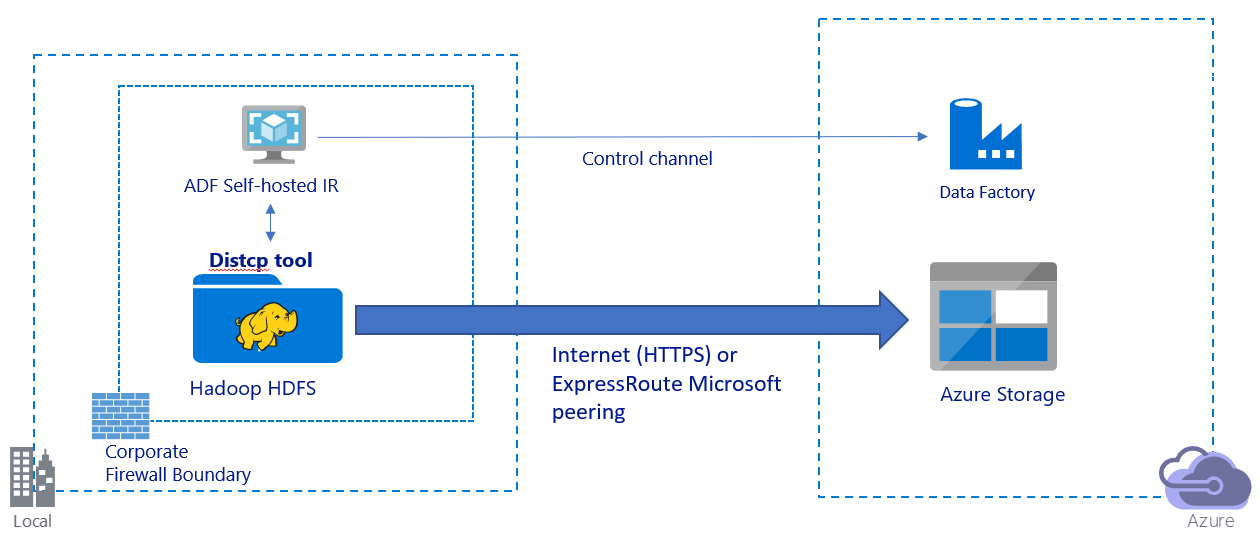
- 在此架構中,資料會透過公用網際網路,使用 HTTPS 安全地進行傳輸。
- 建議您在公用網路環境中使用 Data Factory DistCp 模式。 您可以利用功能強大的現有叢集來達到最佳的複製輸送量。 您也可以從 Data Factory 獲得彈性排程和統一監視體驗的優點。
- 針對此架構,您必須在公司防火牆後方的 Windows 電腦上安裝 Data Factory 自我裝載整合執行階段,才能將 DistCp 命令提交至 Hadoop 叢集,並監視複製狀態。 因為電腦不是移動資料的引擎 (僅針對控制用途),所以電腦的容量不會影響資料移動的輸送量。
- 支援 DistCp 命令的現有參數。
此影像描述透過私人連結移轉資料:
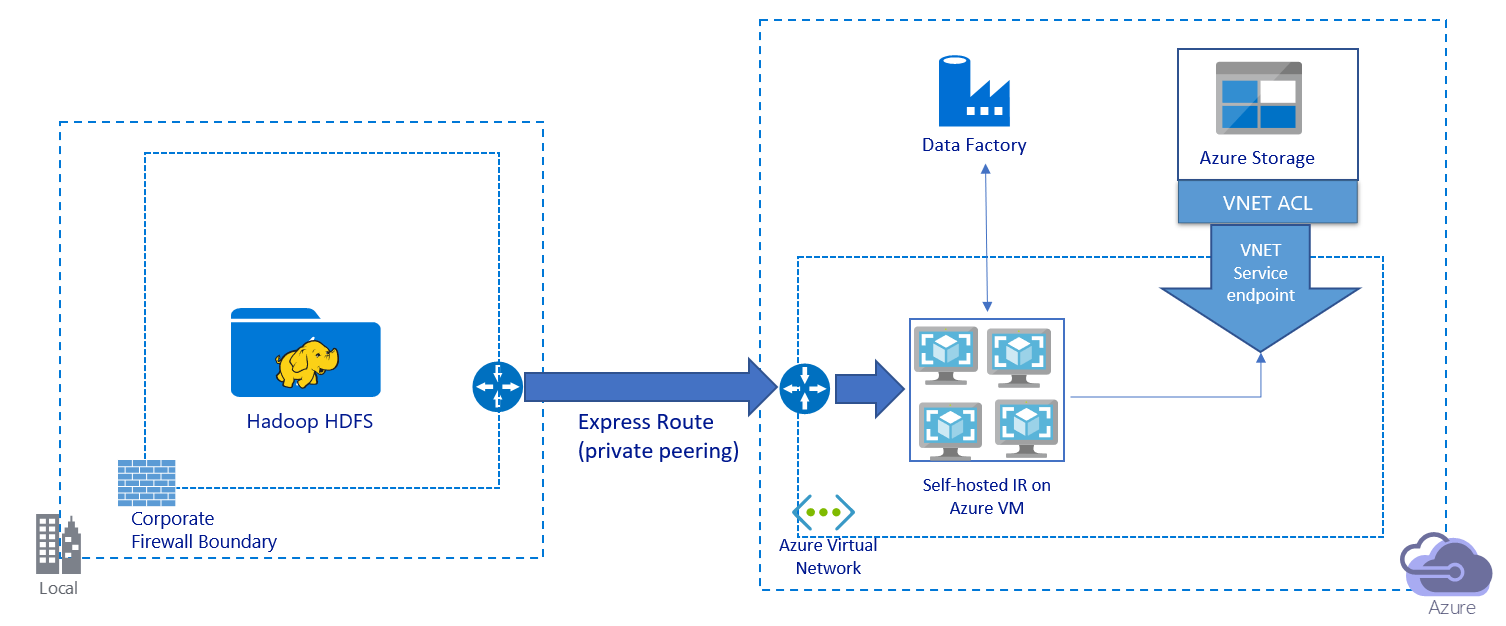
- 在此架構中,資料會透過 Azure ExpressRoute 以私人對等互連連結進行移轉。 資料永遠不會透過公用網際網路周遊。
- DistCp 工具不支援具有 Azure 儲存體虛擬網路端點的 ExpressRoute 私人對等互連。 建議您透過整合執行階段使用 Data Factory 的原生功能來移轉資料。
- 針對此架構,您必須在 Azure 虛擬網路中的 Windows VM 上安裝 Data Factory 自我裝載整合執行階段。 您可手動擴大 VM,或擴增至多部 VM 來完整利用網路和儲存體 IOPS 或頻寬。
- 針對每部 Azure VM (已安裝 Data Factory 自我裝載整合執行階段) 建議的起始組態是 Standard_D32s_v3,具有 32 個虛擬 CPU 和 128 GB 的記憶體。 您可以監視 VM 在資料移轉期間的 CPU 和記憶體使用量,以查看是否需要擴大 VM 以獲得更佳的效能,或是縮小 VM 以降低成本。
- 您也可以將單一自我裝載整合執行階段與最多 4 個 VM 節點建立關聯,以進行擴增。 針對自我裝載整合執行階段執行的單一複製作業將會自動分割檔案集,並利用所有 VM 節點來以平行方式複製檔案。 為了達到高可用性,建議您從兩個 VM 節點開始,以避免在資料移轉期間發生單一失敗點案例。
- 當您使用此架構時,初始快照集資料移轉和差異資料移轉可供您使用。
實作最佳做法
建議您在實作資料移轉時遵循這些最佳做法。
驗證及認證管理
- 若要向 HDFS 進行驗證,您可以使用 Windows (Kerberos) 或 Anonymous。
- 支援多個驗證類型來連線到 Azure Blob 儲存體。 強烈建議使用 Azure 資源受控識別。 建置在 Microsoft Entra ID 中自動受控 Data Factory 身分識別之上,受控識別可讓您設定管線,而不需在連結的服務定義中提供認證。 或者,您可使用服務主體、共用存取簽章,或儲存體帳戶金鑰來向 Blob 儲存體進行驗證。
- 支援多個驗證類型來連線到 Data Lake Storage Gen2。 強烈建議您使用 Azure 資源受控識別,但是您也可以使用服務主體或儲存體帳戶金鑰。
- 當您不使用 Azure 資源受控識別時,強烈建議將認證儲存在 Azure Key Vault 中,其可供更輕鬆地集中管理和輪換金鑰,而無須修改 Data Factory 連結服務。 這也是 CI/CD 的最佳做法。
初始快照集資料移轉
在 Data Factory DistCp 模式中,您可以建立一個複製活動來提交 DistCp 命令,並使用不同的參數來控制初始資料移轉行為。
在 Data Factory 原生整合執行階段模式中,建議您使用資料分割,特別是當您移轉超過 10 TB 的資料時。 若要分割資料,請使用 HDFS 上的資料夾名稱。 然後,每個 Data Factory 複製作業可以一次複製一個資料夾分割。 您可同時執行多個 Data Factory 複製作業,以達到更佳的輸送量。
若因為網路或資料存放區暫時性的問題而導致複製作業失敗,則可重新執行失敗的複製作業來從 HDFS 重新載入該特定分割。 載入其他分割的其他複製作業不會受到影響。
差異資料移轉
在 Data Factory DistCp 模式中,您可以使用 DistCp 命令列參數 -update,在來源檔案和目的地檔案的大小不同時寫入資料,以進行差異資料移轉。
在 Data Factory 原生整合模式中,從 HDFS 識別新檔案或變更檔案的最高效能方式是使用時間分割的命名慣例。 當 HDFS 中的資料在檔案或資料夾名稱中使用時間配量資訊進行時間分割時 (例如,/yyyy/mm/dd/file.csv),您的管線可以輕鬆地識別要累加複製的檔案和資料夾。
或者,如果您 HDFS 中的資料未經過時間分割,Data Factory 可以使用其 LastModifiedDate 值來識別新的檔案或變更的檔案。 Data Factory 會掃描 HDFS 中的所有檔案,只複製上次修改時間戳記大於設定值的新檔案和更新檔案。
如果在 HDFS 中有大量的檔案,則初始檔案掃描可能會花費相當長的時間,無論符合篩選條件的檔案數量為何。 在此案例中,建議您先使用您用於初始快照集移轉的相同分割來分割資料。 然後,檔案掃描可以平行進行。
估計價格
針對將資料從 HDFS 移轉至 Azure Blob 儲存體考慮下列管線:
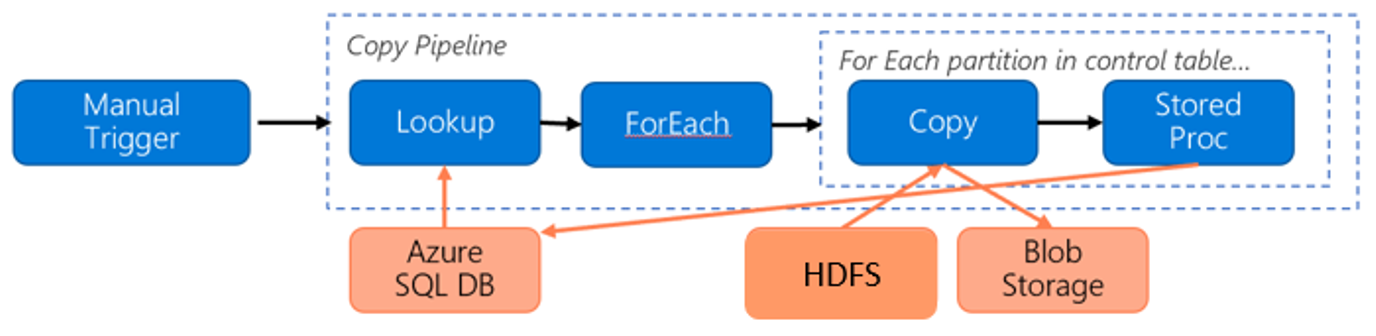
讓我們假設下列資訊:
- 總資料量為 1 PB。
- 您可以使用 Data Factory 原生整合執行階段模式來移轉資料。
- 1 PB 會分成一千個分割,且每個複製都會移動一個分割。
- 每個複製活動都會設定一個與四部電腦相關聯的自我裝載整合執行階段,並達到 500-MBps 輸送量。
- ForEach 並行已設為 4,且彙總輸送量為 2 GBps。
- 總計需要耗費 146 個小時來完成移轉。
以下是根據我們假設的預估價格:
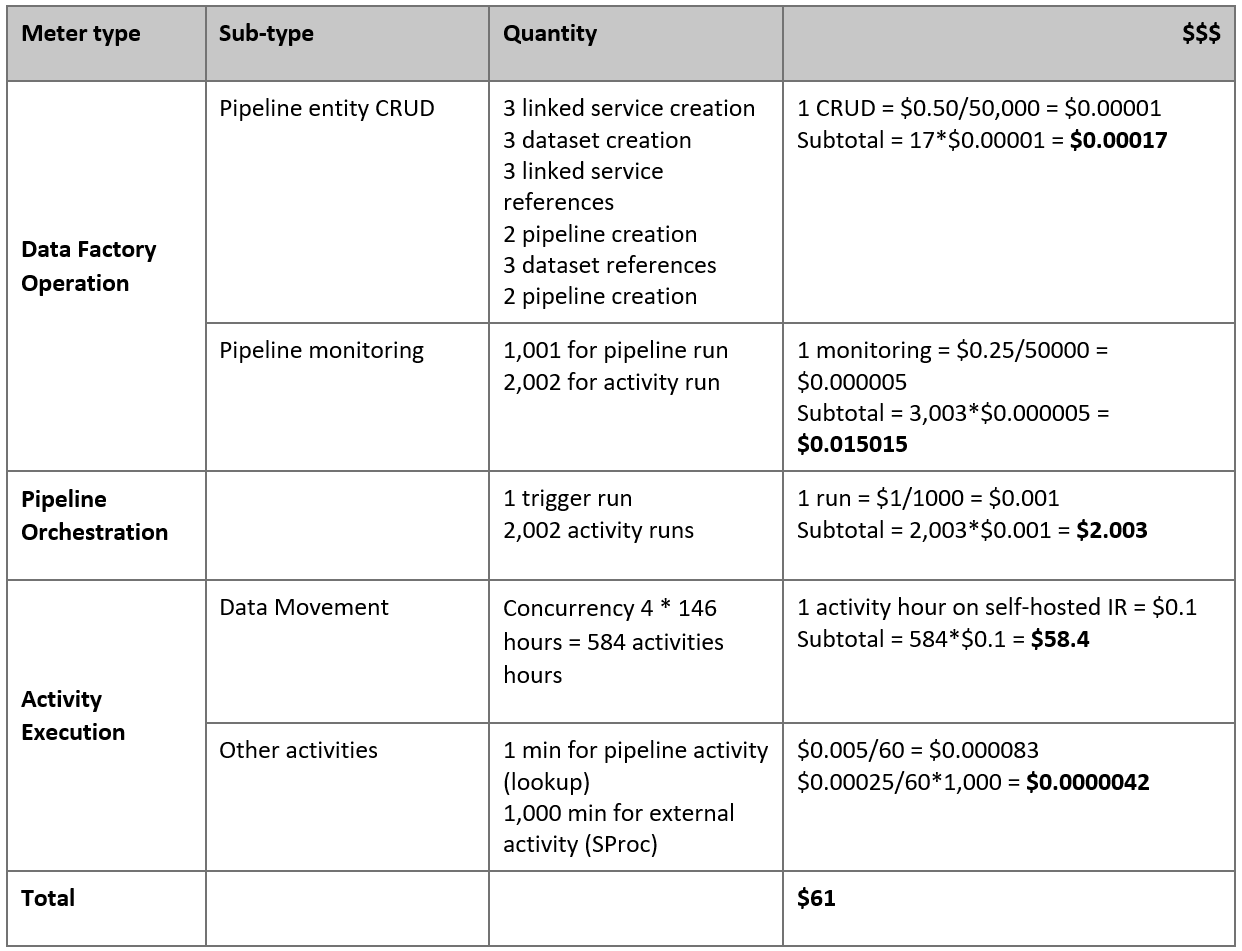
注意
這是假設的定價範例。 實際定價取決於環境中的實際輸送量。 不包含 Azure Windows VM (已安裝自我裝載整合執行階段) 的價格。
其他參考
- HDFS 連接器
- Azure Blob 儲存體連接器
- Azure Data Lake Storage Gen2 連接器
- 複製活動效能調整指南 (機器翻譯)
- 建立和設定自我裝載整合執行階段
- 自我裝載整合執行階段高可用性和可擴縮性
- 資料移動安全性考量 (機器翻譯)
- 在 Azure Key Vault 中儲存認證 (機器翻譯)
- 根據時間分割檔案名稱,以累加方式複製檔案
- 根據 LastModifiedDate 複製新增和變更的檔案 (機器翻譯)
- Data Factory 定價頁面