使用 Azure Data Factory 或 Synapse Analytics 從 HDFS 伺服器複製資料
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
本文概述如何從 Hadoop 分散式檔案系統 (HDFS) 伺服器複製資料。 若要深入了解,請閱讀 Azure Data Factory 和 Synapse Analytics 的介紹文章。
支援的功能
此 HDFS 連接器支援下列功能:
| 支援的功能 | IR |
|---|---|
| 複製活動 (來源/-) | 4.9 |
| 查閱活動 | 4.9 |
| 刪除活動 | 4.9 |
① Azure 整合執行階段 ② 自我裝載整合執行階段
具體而言,HDFS 連接器支援:
- 使用 Windows (Kerberos) 或「匿名」驗證來複製檔案。
- 使用 webhdfs 通訊協定或「內建 DistCp」支援來複製檔案。
- 依原樣複製檔案,或使用支援的檔案格式和壓縮轉碼器來剖析或產生檔案。
必要條件
如果您的資料存放區位於內部部署網路、Azure 虛擬網路或 Amazon 虛擬私人雲端中,則必須設定自我裝載整合執行階段以與其連線。
如果您的資料存放區是受控雲端資料服務,則可使用 Azure Integration Runtime。 如果只能存取防火牆規則中核准的 IP,您可以將 Azure Integration Runtime IP 新增至允許清單。
您也可以使用 Azure Data Factory 中的受控虛擬網路整合執行階段功能來存取內部部署網路,而不需要安裝和設定自我裝載整合執行階段。
如需 Data Factory 支援的網路安全性機制和選項的詳細資訊,請參閱資料存取策略。
注意
請確定整合執行階段可以存取 Hadoop 叢集的「所有」[名稱節點伺服器]:[名稱節點連接埠] 和 [資料節點伺服器]:[資料節點連接埠]。 預設 [名稱節點連接埠] 是 50070,而預設 [資料節點連接埠] 是 50075。
開始使用
若要透過管線執行複製活動,您可以使用下列其中一個工具或 SDK:
使用 UI 建立連結至 HDFS 的服務
使用下列步驟,在 Azure 入口網站 UI 中建立連結至 HDFS 的服務。
前往 Azure Data Factory 或 Synapse 工作區的 [管理] 索引標籤,選取 [連結服務],然後按一下 [新增]:
搜尋 HDFS 並選取 HDFS 連接器。
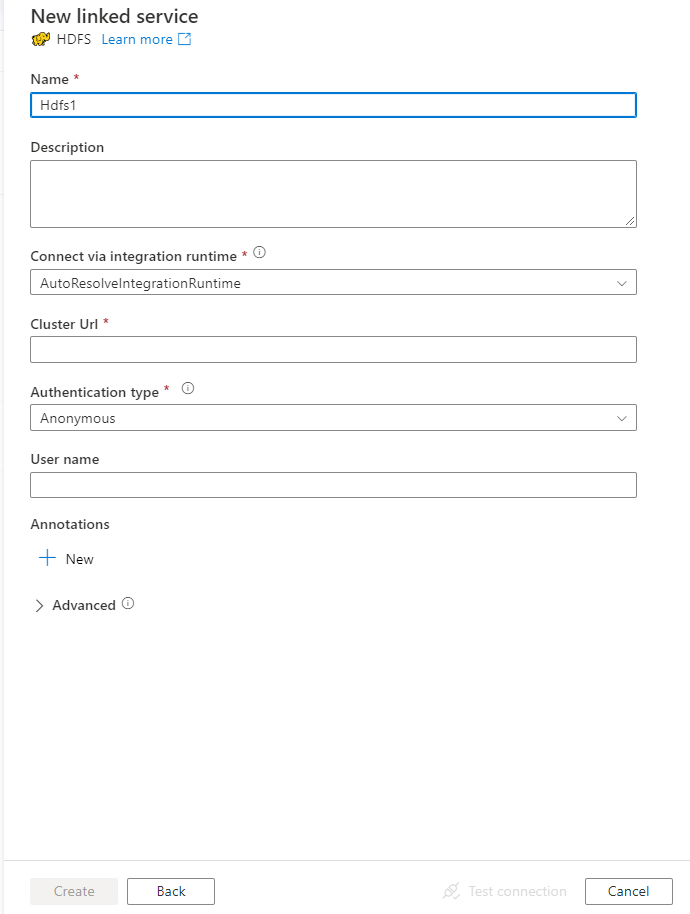
設定服務詳細資料,測試連線,然後建立新的連結服務。
連接器設定詳細資料
下列各節提供屬性的相關詳細資料,這些屬性是用來定義 HDFS 專屬的 Data Factory 實體。
連結服務屬性
HDFS 連結服務支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | type 屬性必須設定為 Hdfs。 | Yes |
| URL | HDFS 的 URL | Yes |
| authenticationType | 允許的值為 Anonymous 或 Windows。 若要設定內部部署環境,請參閱針對 HDFS 連接器使用 Kerberos 驗證一節。 |
Yes |
| userName | Windows 驗證的使用者名稱。 針對 Kerberos 驗證,請指定 <username>@<domain>.com。 | 是 (若為 Windows 驗證) |
| password | Windows 驗證的密碼。 將此欄位標記為 SecureString 以將其安全地儲存,或參考 Azure 金鑰保存庫中儲存的祕密。 | 是 (適用於 Windows 驗證) |
| connectVia | 用來連線到資料存放區的整合執行階段。 若要深入了解,請參閱必要條件一節。 如未指定整合執行階段,服務將使用預設的 Azure Integration Runtime。 | No |
範例:使用匿名驗證
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
範例:使用 Windows 驗證
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
資料集屬性
如需定義資料集的區段和屬性完整清單,請參閱資料集。
Azure Data Factory 支援下列檔案格式。 請參閱每篇文章,以取得以格式為基礎的設定。
在格式型資料集內的 location 設定下,HDFS 支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 在資料集的 location 下,type 屬性必須設定為 HdfsLocation。 |
Yes |
| folderPath | 資料夾的路徑。 如果您想要使用萬用字元來篩選資料夾,則請略過此設定,並在活動來源設定中指定路徑。 | No |
| fileName | 所指定 folderPath 下的檔案名稱。 如果您想要使用萬用字元來篩選檔案,則請略過此設定,並在活動來源設定中指定檔案名稱。 | No |
範例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線和活動。 本節提供 HDFS 來源所支援的屬性清單。
HDFS 作為來源
Azure Data Factory 支援下列檔案格式。 請參閱每篇文章,以取得以格式為基礎的設定。
在格式型複製來源內 storeSettings 設定下,HDFS 支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | storeSettings 下的 type 屬性必須設定為 HdfsReadSettings。 |
Yes |
| 找到要複製的檔案 | ||
| 選項 1:靜態路徑 |
請從資料集中指定的資料夾或檔案路徑複製。 如果您想要複製資料夾中的所有檔案,請另外將 wildcardFileName 指定為 *。 |
|
| 選項 2:萬用字元 - wildcardFolderPath |
含有萬用字元的資料夾路徑,可用來篩選來源資料夾。 允許的萬用字元為: * (符合零或多個字元) 和 ? (符合零或單一字元)。 如果實際資料夾名稱內有萬用字元或逸出字元 ^,請使用此逸出字元來逸出。 如需更多範例,請參閱資料夾和檔案篩選範例。 |
No |
| 選項 2:萬用字元 - wildcardFileName |
在指定 folderPath/wildcardFolderPath 下含有萬用字元的檔案名稱,用於篩選來源檔案。 允許的萬用字元如下: * (比對零或多個字元) 和 ? (比對零或單一字元);如果您的實際檔案名稱包含萬用字元或此逸出字元,請使用 ^ 來逸出。 如需更多範例,請參閱資料夾和檔案篩選範例。 |
Yes |
| 選項 3:檔案清單 - fileListPath |
指出此項目即可複製指定的檔案集。 請指向含有所要複製檔案清單的文字檔 (一行一個檔案,使用資料集中所設定路徑的相對路徑)。 當您使用此選項時,請不要指定資料集中的檔案名稱。 如需更多範例,請參閱檔案清單範例。 |
No |
| 其他設定 | ||
| 遞迴 | 指出是否從子資料夾、或只有從指定的資料夾,以遞迴方式讀取資料。 當 recursive 設定為 true 且接收器是檔案型存放區時,就不會在接收器上複製或建立空的資料夾或子資料夾。 允許的值為 true (預設值) 和 false。 設定 fileListPath 時,此屬性不適用。 |
No |
| deleteFilesAfterCompletion | 指出成功移至目的地存放區之後,是否要從來源存放區中刪除二進位檔案。 檔案刪除會針對每個檔案執行,因此,當複製活動失敗時,您會看到已將某些檔案複製到目的地,而且已從來源刪除,而其他檔案仍保留在來源存放區上。 此屬性僅適用於二進位檔案複製案例。 預設值:false。 |
No |
| modifiedDatetimeStart | 檔案會根據「上次修改時間」屬性進行篩選。 如果檔案的上次修改時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd,則會選取檔案。 此時間會以 2018-12-01T05:00:00Z 格式套用至 UTC 時區。 此屬性可以是 NULL,這意謂著不會對資料集套用任何檔案屬性篩選。 當 modifiedDatetimeStart 有日期時間值,但 modifiedDatetimeEnd 為 NULL 時,表示系統將會選取上次修改時間屬性大於或等於此日期時間值的檔案。 當 modifiedDatetimeEnd 有日期時間值,但 modifiedDatetimeStart 為 NULL 時,則表示系統將會選取上次修改時間屬性小於此日期時間值的檔案。設定 fileListPath 時,此屬性不適用。 |
No |
| modifiedDatetimeEnd | 同上。 | |
| enablePartitionDiscovery | 針對已分割的檔案,指定是否要從檔案路徑剖析分割區,並將其新增為其他來源資料行。 允許的值為 false (預設值) 和 true。 |
No |
| partitionRootPath | 啟用分割區探索時,請指定絕對根路徑,將已分割的資料夾當成資料行進行讀取。 如果未指定,則根據預設, - 當您使用資料集中的檔案路徑或來源上的檔案清單時,分割區根路徑是資料集中所設定的路徑。 - 當您使用萬用字元資料夾篩選時,分割區根路徑是第一個萬用字元前面的子路徑。 例如,假設您將資料集中的路徑設定為 "root/folder/year=2020/month=08/day=27": - 如果您將分割區根路徑指定為 "root/folder/year=2020",則除了檔案內的資料行之外,複製活動還會分別產生值為 "08" 和 "27" 的兩個資料行 month 和 day。- 如果未指定分割區根路徑,則不會產生額外的資料行。 |
No |
| maxConcurrentConnections | 在活動執行期間建立至資料存放區的同時連線上限。 僅在想要限制並行連線時,才需要指定值。 | No |
| DistCp 設定 | ||
| distcpSettings | 要在您使用 HDFS DistCp 時使用的屬性群組。 | No |
| resourceManagerEndpoint | YARN (Yet Another Resource Negotiator) 端點 | 是,如果使用 DistCp 的話 |
| tempScriptPath | 資料夾路徑,用來儲存暫存 DistCp 命令指令碼。 系統會產生指令碼檔案,並在複製作業完成之後將其移除。 | 是,如果使用 DistCp 的話 |
| distcpOptions | 對於 DistCp 命令提供的其他選項。 | No |
範例:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
資料夾和檔案篩選範例
本節描述搭配資料夾路徑和檔案名稱使用萬用字元篩選條件時所產生的行為。
| folderPath | fileName | 遞迴 | 來源資料夾結構和篩選結果 (會擷取以粗體顯示的檔案) |
|---|---|---|---|
Folder* |
(空白,使用預設值) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(空白,使用預設值) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
檔案清單範例
本節描述在複製活動來源中使用檔案清單路徑時所產生的行為。 假設您的來源資料夾結構如下,且想要複製以粗體顯示的檔案:
| 範例來源結構 | FileListToCopy.txt 中的內容 | 組態 |
|---|---|---|
| 根 FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv 中繼資料 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在資料集內: - 資料夾路徑: root/FolderA在複製活動來源中: - 檔案清單路徑: root/Metadata/FileListToCopy.txt 檔案清單路徑指向相同資料存放區中的文字檔,其中包括所要複製檔案的清單 (一行一個檔案,使用資料集中所設定路徑的相對路徑)。 |
使用 DistCp 從 HDFS 複製資料
DistCp 是 Hadoop 原生命令列工具,用來在 Hadoop 叢集中執行分散式複製。 當您在 DistCp 中執行命令時,其會先列出要複製的所有檔案,然後在 Hadoop 叢集中建立數個對應作業。 每個對應作業都會執行從來源到接收器的二進位複製。
複製活動支援使用 DistCp 將檔案依原樣複製到 Azure Blob 儲存體 (包括分段複製) 或 Azure Data Lake Store。 在此情況下,DistCp 可以利用叢集的能力,而不是在自我裝載整合執行階段上執行。 尤其是,如果您的叢集相當強大,使用 DistCp可提供更好的複製輸送量。 根據設定,複製活動會自動建構 DistCp 命令、將其提交至 Hadoop 叢集,並監視複製狀態。
必要條件
若要使用 DistCp 從 HDFS 將檔案依原樣複製到 Azure Blob 儲存體 (包括分段複製) 或 Azure Data Lake Store,請確定 Hadoop 叢集符合下列需求:
MapReduce 和 YARN 服務已啟用。
YARN 版本是 2.5 或更新。
HDFS 伺服器與目標資料存放區整合:Azure Blob 儲存體或 Azure Data Lake Store (ADLS Gen1):
- 自從 Hadoop 2.7 開始即原生支援 Azure Blob FileSystem。 您只需要在 Hadoop 環境設定中指定 JAR 路徑。
- Azure Data Lake Store FileSystem 是從 Hadoop 3.0.0-alpha1 開始封裝。 如果您的 Hadoop 叢集版本早於該版本,您必須從這裡手動將 Azure Data Lake Store 相關的 JAR 套件 (azure-datalake-store.jar) 匯入至叢集,並在 Hadoop 環境設定中指定 JAR 檔案路徑。
準備 HDFS 中的暫存資料夾。 此暫存資料夾是用來儲存 DistCp 殼層指令碼,因此會佔用 KB 層級的空間。
請確定 HDFS 連結服務中提供的使用者帳戶具有權限,可執行下列動作:
- 在 YARN 中提交應用程式。
- 在暫存資料夾下建立子資料夾和讀取/寫入檔案。
設定
如需 DistCp 相關設定和範例,請移至 HDFS 作為來源一節。
針對 HDFS 連接器使用 Kerberos 驗證
有兩個選項可以設定內部部署環境,以針對 HDFS 連接器使用 Kerberos 驗證。 您可以選擇較適合您情況的選項。
針對任一選項,請確定您針對 Hadoop 叢集開啟 webhdfs:
建立 webhdfs 的 HTTP 主體和 keytab。
重要
根據 Kerberos HTTP SPNEGO 規格,HTTP Kerberos 主體必須以 "HTTP/" 開頭。 您可以在這裡深入了解。
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS 設定選項:在
hdfs-site.xml中新增下列三個屬性。<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
選項 1:加入 Kerberos 領域中的自我裝載整合執行階段機器
需求
- 自我裝載整合執行階段機器必須加入 Kerberos 領域,且不可加入任何 Windows 網域。
如何設定
在 KDC 伺服器上:
建立主體並指定密碼。
重要
使用者名稱不應包含主機名稱。
Kadmin> addprinc <username>@<REALM.COM>
在自我裝載整合執行階段機器上:
執行 Ksetup 公用程式來設定 Kerberos 金鑰發佈中心 (KDC) 伺服器和領域。
電腦必須設定為工作群組的成員,因為 Kerberos 領域與 Windows 網域不同。 您可以藉由執行下列命令來設定 Kerberos 領域和新增 KDC 伺服器,以實現此設定。 將 REALM.COM 取代為您自己的領域名稱。
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>在執行這些命令之後,請重新啟動機器。
使用
Ksetup命令來驗證設定。 輸出應該會像這樣:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
在您的資料處理站或 Synapse 工作區中:
- 使用 Windows 驗證以及您用來連線到 HDFS 資料來源的 Kerberos 主體名稱和密碼,來設定 HDFS 連接器。 如需設定詳細資料,請參閱 HDFS 連結服務屬性一節。
選項 2:啟用 Windows 網域和 Kerberos 領域之間的相互信任
需求
- 自我裝載整合執行階段機器必須加入 Windows 網域。
- 您需要更新網域控制站設定的權限。
如何設定
注意
將下列教學課程中的 REALM.COM 和 AD.COM 取代為您自己的領域名稱和網域控制站。
在 KDC 伺服器上:
編輯 krb5.conf 檔案中的 KDC 設定,讓 KDC 參考下列設定範本來信任 Windows 網域。 根據預設,設定會位於 /etc/krb5.conf。
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }在設定檔案之後,請重新啟動 KDC 服務。
使用下列命令,在 KDC 伺服器中準備名為 krbtgt/REALM.COM@AD.COM 的主體︰
Kadmin> addprinc krbtgt/REALM.COM@AD.COM在 hadoop.security.auth_to_local HDFS 服務設定檔案中,新增
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//。
在網域控制站上:
執行下列
Ksetup命令來新增領域項目:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM建立 Windows 網域對 Kerberos 領域的信任關係。 [password] 是主體 krbtgt/REALM.COM@AD.COM 的密碼。
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]選取 Kerberos 中使用的加密演算法。
a. 選取 [伺服器管理員]>[群組原則管理]>[網域]>[群組原則物件]>[預設或 Active Domain 原則],然後選取 [編輯]。
b. 在 [群組原則管理編輯器] 窗格中,選取 [電腦設定]>[原則]>[Windows 設定]>[安全性設定]>[本機原則]>[安全性選項],然後設定 [網路安全性: 設定 Kerberos 允許的加密類型]。
c. 選取您要在連線到 KDC 時使用的加密演算法。 您可以選取所有選項。

d. 使用
Ksetup命令來指定要用於所指定領域的加密演算法。C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96建立網域帳戶與 Kerberos 主體之間的對應關係,以便您可以在 Windows 網域中使用 Kerberos 主體。
a. 選取 [系統管理工具]>[Active Directory 使用者和電腦]。
b. 選取 [檢視]>[進階功能],以設定進階功能。
c. 在 [進階功能] 窗格上,以滑鼠右鍵按一下您要建立對應的帳戶,然後在 [名稱對應] 窗格上,選取 [Kerberos 名稱] 索引標籤。
d. 加入來自領域的主體。
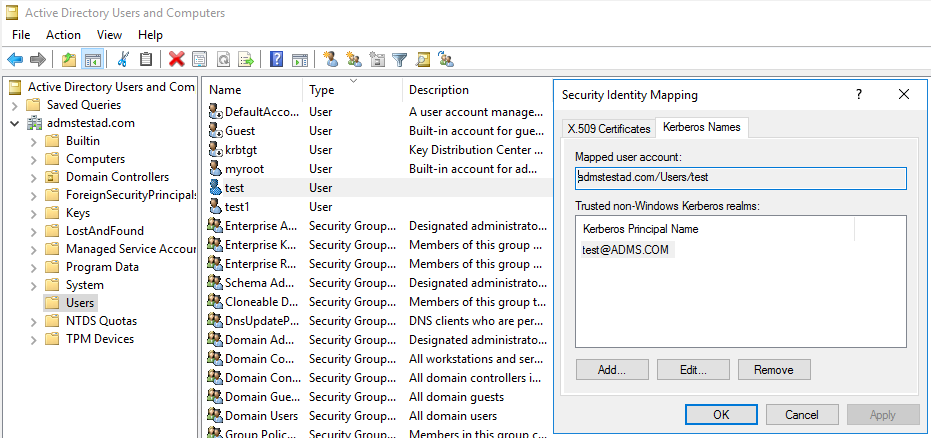
在自我裝載整合執行階段機器上:
執行下列
Ksetup命令來新增領域項目。C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
在您的資料處理站或 Synapse 工作區中:
- 使用 Windows 驗證,搭配要連線到 HDFS 資料來源的網域帳戶或 Kerberos 主體,來設定 HDFS 連接器。 如需設定詳細資料,請參閱 HDFS 連結服務屬性一節。
查閱活動屬性
如需查閱活動屬性的相關資訊,請參閱查閱活動。
刪除活動屬性
如需刪除活動屬性的相關資訊,請參閱刪除活動。
舊版模型
注意
基於回溯相容性,仍照現狀支援下列模型。 建議您使用先前討論過的新模型,因為撰寫 UI 已改為產生新模型。
舊版資料集模型
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的 type 屬性必須設定為 FileShare | Yes |
| folderPath | 資料夾的路徑。 支援萬用字元篩選條件。 允許的萬用字元為 * (比對零或多個字元) 和 ? (比對零或單一字元);如果您的實際檔案名稱包含萬用字元或此逸出字元,請使用 ^ 來逸出。 範例:rootfolder/subfolder/,如需更多範例,請參閱資料夾和檔案篩選範例。 |
Yes |
| fileName | 所指定 "folderPath" 底下檔案的名稱或萬用字元篩選條件。 若未指定此屬性的值,資料集就會指向資料夾中的所有檔案。 針對篩選,允許的萬用字元為 * (符合零或多個字元) 和 ? (符合零個或單一字元)。- 範例 1: "fileName": "*.csv"- 範例 2: "fileName": "???20180427.txt"如果實際資料夾名稱內有萬用字元或逸出字元 ^,請使用此逸出字元來逸出。 |
No |
| modifiedDatetimeStart | 檔案會根據「上次修改時間」屬性進行篩選。 如果檔案的上次修改時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd,則會選取檔案。 此時間會以 2018-12-01T05:00:00Z 格式套用至 UTC 時區。 請注意,當您想要將檔案篩選條件套用至大量檔案時,啟用這項設定將影響資料移動的整體效能。 此屬性可以是 NULL,這意謂著不會對資料集套用任何檔案屬性篩選。 當 modifiedDatetimeStart 有日期時間值,但 modifiedDatetimeEnd 為 NULL 時,表示系統將會選取上次修改時間屬性大於或等於此日期時間值的檔案。 當 modifiedDatetimeEnd 有日期時間值,但 modifiedDatetimeStart 為 NULL 時,則表示系統將會選取上次修改時間屬性小於此日期時間值的檔案。 |
No |
| modifiedDatetimeEnd | 檔案會根據「上次修改時間」屬性進行篩選。 如果檔案的上次修改時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd,則會選取檔案。 此時間會以 2018-12-01T05:00:00Z 格式套用至 UTC 時區。 請注意,當您想要將檔案篩選條件套用至大量檔案時,啟用這項設定將影響資料移動的整體效能。 此屬性可以是 NULL,這意謂著不會對資料集套用任何檔案屬性篩選。 當 modifiedDatetimeStart 有日期時間值,但 modifiedDatetimeEnd 為 NULL 時,表示系統將會選取上次修改時間屬性大於或等於此日期時間值的檔案。 當 modifiedDatetimeEnd 有日期時間值,但 modifiedDatetimeStart 為 NULL 時,則表示系統將會選取上次修改時間屬性小於此日期時間值的檔案。 |
No |
| format | 如果您想要在檔案型存放區之間依原樣複製檔案 (二進位複本),請在輸入和輸出資料集定義中略過格式區段。 如果您想要以特定格式來剖析檔案,以下是支援的檔案格式類型:TextFormat、JsonFormat、AvroFormat、OrcFormat、ParquetFormat。 將格式下的 type 屬性設定為這些值其中之一。 如需詳細資訊,請參閱文字格式、JSON 格式、Avro 格式、ORC 格式和 Parquet 格式章節。 |
否 (僅適用於二進位複製案例) |
| 壓縮 | 指定此資料的壓縮類型和層級。 如需詳細資訊,請參閱支援的檔案格式和壓縮轉碼器。 支援的類型如下:GzipDeflateBzip2 和 ZipDeflate。 支援的層級為:Optimal 和 Fastest。 |
No |
提示
若要複製資料夾下的所有檔案,請只指定 folderPath。
若要複製指定名稱的單一檔案,請以資料夾部分指定 folderPath,並以檔案名稱指定 fileName。
若要複製資料夾下的檔案子集,請以資料夾部分指定 folderPath,並以萬用字元篩選指定 fileName。
範例:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
舊版複製活動來源模型
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的 type 屬性必須設定為 HdfsSource。 | Yes |
| 遞迴 | 指出是否從子資料夾、或只有從指定的資料夾,以遞迴方式讀取資料。 當遞迴設定為 true 且接收器是檔案型存放區時,就不會在接收器上複製或建立空的資料夾或子資料夾。 允許的值為 true (預設值) 和 false。 |
No |
| distcpSettings | 使用 HDFS DistCp 時的屬性群組。 | No |
| resourceManagerEndpoint | YARN Resource Manager 端點 | 是,如果使用 DistCp 的話 |
| tempScriptPath | 資料夾路徑,用來儲存暫存 DistCp 命令指令碼。 系統會產生指令碼檔案,並在複製作業完成之後將其移除。 | 是,如果使用 DistCp 的話 |
| distcpOptions | 有額外選項提供給 DistCp 命令。 | No |
| maxConcurrentConnections | 在活動執行期間建立至資料存放區的同時連線上限。 僅在想要限制並行連線時,才需要指定值。 | No |
範例:使用 DistCp 時複製活動中的 HDFS 來源
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
相關內容
如需複製活動所支援作為來源和接收器的資料存放區清單,請參閱支援的資料存放區。