创建和录制命令列表和捆绑包
本主题介绍 Direct3D 12 应用中录制命令列表和捆绑包。 命令列表和捆绑包都允许应用记录图形处理单元(GPU)上后续执行的绘图或状态更改调用。
除了命令列表之外,API 还通过添加二级命令列表(称为 捆绑包)来利用 GPU 硬件中存在的功能。 捆绑的目的是允许应用将少量 API 命令组合在一起,以供以后执行。 创建捆绑时,驱动程序会执行尽量多的预处理,以降低以后的执行开销。 捆绑包被设计为可以多次使用和重复使用。 另一方面,命令列表通常只执行一次。 但是,只要应用程序在提交新执行之前确保先前的执行完成,则可以多次执行命令列表。
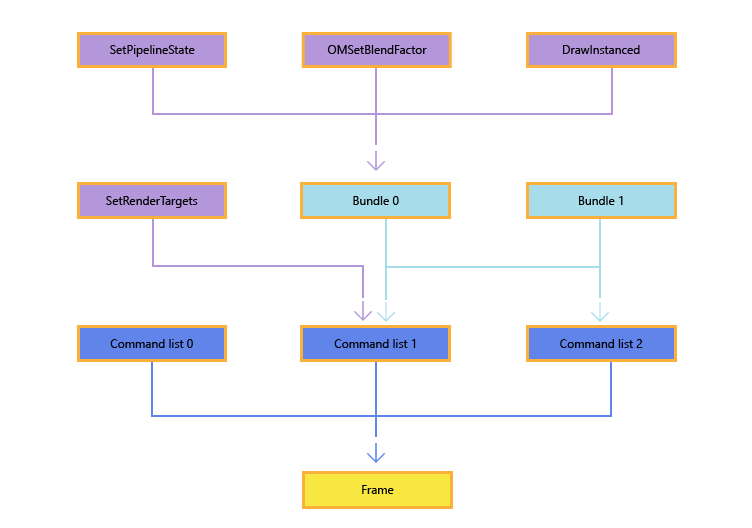
通常,API 调用构成捆绑,API 调用和捆绑构成命令列表,而命令列表构成单个帧。下图演示了此结构,请注意命令列表 1 和命令列表 2 中重复使用了捆绑 1,图中的 API 方法名称仅用作示例,可以使用许多不同的 API 调用。
创建和执行捆绑包和直接命令列表存在不同的限制,本主题中介绍了这些差异。
创建命令列表
直接命令列表和捆绑包通过调用 ID3D12Device::CreateCommandList 或 ID3D12Device4::CreateCommandList1来创建。
使用 ID3D12Device4::CreateCommandList1 创建关闭的命令列表,而不是创建新列表并立即关闭它。 这避免了使用分配器和 PSO 创建列表但不使用它们的低效性。
ID3D12Device::CreateCommandList 采用以下参数作为输入:
D3D12_COMMAND_LIST_TYPE
D3D12_COMMAND_LIST_TYPE 枚举指示正在创建的命令列表的类型。 它可以是直接命令列表、捆绑包、计算命令列表或复制命令列表。
ID3D12CommandAllocator
命令分配器允许应用管理为命令列表分配的内存。 命令分配器是通过调用 CreateCommandAllocator创建的。 创建命令列表时,由 D3D12_COMMAND_LIST_TYPE指定的分配器的命令列表类型必须与要创建的命令列表的类型匹配。 一个给定的分配器可同时与多个“当前正在记录”命令列表相关联,不过,可以使用一个命令分配器来创建任意数量的 GraphicsCommandList 对象。
若要回收命令分配器分配的内存,应用调用 ID3D12CommandAllocator::Reset。 这允许分配器重新用于新命令,但不会减小其基础大小。 但在执行此作之前,应用必须确保 GPU 不再执行与分配器关联的任何命令列表;否则,调用将失败。 此外,请注意,此 API 不是自由线程的,因此不能从多个线程同时在同一分配器上调用。
ID3D12PipelineState
命令列表的初始管道状态。 在 Microsoft Direct3D 12 中,大多数图形管道状态都使用 ID3D12PipelineState 对象在命令列表中设置。 应用将在应用初始化期间创建大量此类内容,然后通过使用 ID3D12GraphicsCommandList::SetPipelineState更改当前绑定的状态对象来更新状态。 有关管道状态对象的详细信息,请参阅 管理 Direct3D 12中的图形管道状态。
请注意,捆绑不会继承以前的调用在直接命令列表(捆绑的父级)中设置的管道状态。
如果此参数为 NULL,则使用默认状态。
记录命令列表
创建后,命令列表处于录制状态。 还可以通过调用 ID3D12GraphicsCommandList::Reset重新使用现有命令列表,这也使命令列表处于录制状态。 与 ID3D12CommandAllocator::Reset不同,可以在命令列表仍在执行时调用 重置。 典型的模式是提交命令列表,然后立即重置它,以便为另一个命令列表重复使用分配的内存。 请注意,一次只能有一个与每个命令分配器关联的命令列表处于录制状态。
命令列表处于录制状态后,只需调用 ID3D12GraphicsCommandList 接口的方法即可将命令添加到列表中。 其中许多方法都支持Microsoft Direct3D 11 开发人员熟悉的常见 Direct3D 功能;其他 API 是 Direct3D 12 的新增功能。
将命令添加到命令列表后,可以通过调用 关闭将命令列表切换出录制状态。
命令分配器可以增长,但不会收缩 - 应考虑池化并重用分配器,以最大限度提高应用程序的效率。 在重置之前,可以将多个列表记录到同一个分配器中,前提是一次只有一个列表记录给给定的分配器。 可以将每个列表可视化为拥有分配器的一部分,该部分指示 ID3D12CommandQueue::ExecuteCommandLists 将要执行的内容。
一种简单的分配器池策略应该针对大约 numCommandLists * MaxFrameLatency 个分配器。 例如,如果记录 6 个列表并允许最多 3 个潜在帧,则可以合理地期望 18-20 个分配器。 一种更高级的池化策略,在同一线程上为多个列表重用分配器,可以针对 numRecordingThreads * MaxFrameLatency 个分配器。 在前面的例子中,如果线程 A、B 分别记录了 2 个列表,而线程 C 和线程 D 各记录了 1 个列表,那么您可以实际考虑设置 12 到 14 个分配器。
使用围栏来确定给定分配器何时能够重复使用。
由于命令列表可以在执行后立即重置,因此可以轻松地进行池化,每次调用 ID3D12CommandQueue::ExecuteCommandLists后,就将其添加回池中。
例
以下代码片段演示了命令列表的创建和记录。 请注意,此示例包含以下 Direct3D 12 功能:
- 管道状态对象 - 这些对象用于从命令列表中设置呈现管道的大部分状态参数。 有关详细信息,请参阅 在 Direct3D 12中管理图形管道状态。
- 描述符堆 - 应用使用描述符堆来管理对内存资源的管道绑定。
- 资源屏障 - 这用于管理资源从一种状态到另一种状态的转换,例如从呈现目标视图到着色器资源视图。 有关详细信息,请参阅 使用资源屏障来同步资源状态。
例如
void D3D12HelloTriangle::LoadAssets()
{
// Create an empty root signature.
{
CD3DX12_ROOT_SIGNATURE_DESC rootSignatureDesc;
rootSignatureDesc.Init(0, nullptr, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
ComPtr<ID3DBlob> signature;
ComPtr<ID3DBlob> error;
ThrowIfFailed(D3D12SerializeRootSignature(&rootSignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1, &signature, &error));
ThrowIfFailed(m_device->CreateRootSignature(0, signature->GetBufferPointer(), signature->GetBufferSize(), IID_PPV_ARGS(&m_rootSignature)));
}
// Create the pipeline state, which includes compiling and loading shaders.
{
ComPtr<ID3DBlob> vertexShader;
ComPtr<ID3DBlob> pixelShader;
#if defined(_DEBUG)
// Enable better shader debugging with the graphics debugging tools.
UINT compileFlags = D3DCOMPILE_DEBUG | D3DCOMPILE_SKIP_OPTIMIZATION;
#else
UINT compileFlags = 0;
#endif
ThrowIfFailed(D3DCompileFromFile(GetAssetFullPath(L"shaders.hlsl").c_str(), nullptr, nullptr, "VSMain", "vs_5_0", compileFlags, 0, &vertexShader, nullptr));
ThrowIfFailed(D3DCompileFromFile(GetAssetFullPath(L"shaders.hlsl").c_str(), nullptr, nullptr, "PSMain", "ps_5_0", compileFlags, 0, &pixelShader, nullptr));
// Define the vertex input layout.
D3D12_INPUT_ELEMENT_DESC inputElementDescs[] =
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 0, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 },
{ "COLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 12, D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA, 0 }
};
// Describe and create the graphics pipeline state object (PSO).
D3D12_GRAPHICS_PIPELINE_STATE_DESC psoDesc = {};
psoDesc.InputLayout = { inputElementDescs, _countof(inputElementDescs) };
psoDesc.pRootSignature = m_rootSignature.Get();
psoDesc.VS = { reinterpret_cast<UINT8*>(vertexShader->GetBufferPointer()), vertexShader->GetBufferSize() };
psoDesc.PS = { reinterpret_cast<UINT8*>(pixelShader->GetBufferPointer()), pixelShader->GetBufferSize() };
psoDesc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT);
psoDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT);
psoDesc.DepthStencilState.DepthEnable = FALSE;
psoDesc.DepthStencilState.StencilEnable = FALSE;
psoDesc.SampleMask = UINT_MAX;
psoDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
psoDesc.NumRenderTargets = 1;
psoDesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
psoDesc.SampleDesc.Count = 1;
ThrowIfFailed(m_device->CreateGraphicsPipelineState(&psoDesc, IID_PPV_ARGS(&m_pipelineState)));
}
// Create the command list.
ThrowIfFailed(m_device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, m_commandAllocator.Get(), m_pipelineState.Get(), IID_PPV_ARGS(&m_commandList)));
// Command lists are created in the recording state, but there is nothing
// to record yet. The main loop expects it to be closed, so close it now.
ThrowIfFailed(m_commandList->Close());
// Create the vertex buffer.
{
// Define the geometry for a triangle.
Vertex triangleVertices[] =
{
{ { 0.0f, 0.25f * m_aspectRatio, 0.0f }, { 1.0f, 0.0f, 0.0f, 1.0f } },
{ { 0.25f, -0.25f * m_aspectRatio, 0.0f }, { 0.0f, 1.0f, 0.0f, 1.0f } },
{ { -0.25f, -0.25f * m_aspectRatio, 0.0f }, { 0.0f, 0.0f, 1.0f, 1.0f } }
};
const UINT vertexBufferSize = sizeof(triangleVertices);
// Note: using upload heaps to transfer static data like vert buffers is not
// recommended. Every time the GPU needs it, the upload heap will be marshalled
// over. Please read up on Default Heap usage. An upload heap is used here for
// code simplicity and because there are very few verts to actually transfer.
ThrowIfFailed(m_device->CreateCommittedResource(
&CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
D3D12_HEAP_FLAG_NONE,
&CD3DX12_RESOURCE_DESC::Buffer(vertexBufferSize),
D3D12_RESOURCE_STATE_GENERIC_READ,
nullptr,
IID_PPV_ARGS(&m_vertexBuffer)));
// Copy the triangle data to the vertex buffer.
UINT8* pVertexDataBegin;
CD3DX12_RANGE readRange(0, 0); // We do not intend to read from this resource on the CPU.
ThrowIfFailed(m_vertexBuffer->Map(0, &readRange, reinterpret_cast<void**>(&pVertexDataBegin)));
memcpy(pVertexDataBegin, triangleVertices, sizeof(triangleVertices));
m_vertexBuffer->Unmap(0, nullptr);
// Initialize the vertex buffer view.
m_vertexBufferView.BufferLocation = m_vertexBuffer->GetGPUVirtualAddress();
m_vertexBufferView.StrideInBytes = sizeof(Vertex);
m_vertexBufferView.SizeInBytes = vertexBufferSize;
}
// Create synchronization objects and wait until assets have been uploaded to the GPU.
{
ThrowIfFailed(m_device->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_fence)));
m_fenceValue = 1;
// Create an event handle to use for frame synchronization.
m_fenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr);
if (m_fenceEvent == nullptr)
{
ThrowIfFailed(HRESULT_FROM_WIN32(GetLastError()));
}
// Wait for the command list to execute; we are reusing the same command
// list in our main loop but for now, we just want to wait for setup to
// complete before continuing.
WaitForPreviousFrame();
}
}
创建和记录命令列表后,可以使用命令队列执行该列表。 有关详细信息,请参阅 执行和同步命令列表。
引用计数
大多数 D3D12 API 遵循 COM 约定继续使用引用计数。 这一点的一个显著例外是 D3D12 图形命令列表 API。 ID3D12GraphicsCommandList 上的所有 API 都不包含对传递到这些 API 的对象的引用。 这意味着,应用程序需负责确保永远不会提交引用已销毁资源的命令列表以供执行。
命令列表错误
ID3D12GraphicsCommandList 上的大多数 API 不会返回错误。 建命令列表期间遇到的错误将推迟到 ID3D12GraphicsCommandList::Close。 一种例外情况是 DXGI_ERROR_DEVICE_REMOVED,它会进一步推迟错误。 请注意,这不同于 D3D11,其中许多参数验证错误会静默删除,并且从未返回到调用方。
应用程序在以下 API 调用中可能会看到 DXGI_DEVICE_REMOVED 错误:
命令列表 API 限制
某些命令列表 API 只能在某些类型的命令列表上调用。 下表显示了对每种类型的命令列表调用哪些命令列表 API 有效。 它还显示了在 D3D12 渲染通道中调用哪些 API 有效。
| API 名称 | 图形 | 计算 | 复制 | 捆绑 | 在呈现处理过程中 |
|---|---|---|---|---|---|
| AtomicCopyBufferUINT | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| AtomicCopyBufferUINT64 | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| BeginQuery | ✔ 有效 | ✔ 有效 | |||
| BeginRenderPass | ✔ 有效 | ||||
| BuildRaytracingAccelerationStructure | ✔ 有效 | ✔ 有效 | |||
| ClearDepthStencilView | ✔ 有效 | ||||
| ClearRenderTargetView | ✔ 有效 | ||||
| ClearState | ✔ 有效 | ✔ 有效 | |||
| ClearUnorderedAccessViewFloat | ✔ 有效 | ✔ 有效 | |||
| ClearUnorderedAccessViewUint | ✔ 有效 | ✔ 有效 | |||
| CopyBufferRegion | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| CopyRaytracingAccelerationStructure | ✔ 有效 | ✔ 有效 | |||
| CopyResource | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| CopyTextureRegion | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| CopyTiles | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| DiscardResource | ✔ 有效 | ✔ 有效 | |||
| Dispatch | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| DispatchRays | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| DrawIndexedInstanced | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| DrawInstanced | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| EmitRaytracingAccelerationStructurePostbuildInfo | ✔ 有效 | ✔ 有效 | |||
| 结束查询 | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| EndRenderPass | ✔ 有效 | ✔ 有效 | |||
| ExecuteBundle | ✔ 有效 | ✔ 有效 | |||
| ExecuteIndirect | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| ExecuteMetaCommand | ✔ 有效 | ✔ 有效 | |||
| IASetIndexBuffer | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| IASetPrimitiveTopology | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| IASetVertexBuffers | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| InitializeMetaCommand | ✔ 有效 | ✔ 有效 | |||
| OMSetBlendFactor | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| OMSetDepthBounds | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| OMSetRenderTargets | ✔ 有效 | ||||
| OMSetStencilRef | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| ResolveQueryData | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| ResolveSubresource | ✔ 有效 | ||||
| ResolveSubresourceRegion | ✔ 有效 | ||||
| 资源屏障 | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| RSSetScissorRects | ✔ 有效 | ✔ 有效 | |||
| RSSetShadingRate | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| RSSetShadingRateImage | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| RSSetViewports | ✔ 有效 | ✔ 有效 | |||
| SetComputeRoot32BitConstant | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRoot32BitConstants | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRootConstantBufferView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRootDescriptorTable | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRootShaderResourceView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRootSignature | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetComputeRootUnorderedAccessView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetDescriptorHeaps | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetGraphicsRoot32BitConstant | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRoot32BitConstants | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRootConstantBufferView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRootDescriptorTable | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRootShaderResourceView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRootSignature | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetGraphicsRootUnorderedAccessView | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetPipelineState | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | |
| SetPipelineState1 | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetPredication | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetProtectedResourceSession | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetSamplePositions | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SetViewInstanceMask | ✔ 有效 | ✔ 有效 | ✔ 有效 | ||
| SOSetTargets | ✔ 有效 | ✔ 有效 | |||
| WriteBufferImmediate | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 | ✔ 有效 |
捆绑限制
限制可使 Direct3D 12 驱动程序在记录时执行大部分与捆绑相关的工作,因此能够以较低的开销运行 ExecuteBundle API。 捆绑包引用的所有管道状态对象必须具有相同的呈现目标格式、深度缓冲区格式和示例说明。
不允许在创建类型为D3D12_COMMAND_LIST_TYPE_BUNDLE的命令列表上调用以下命令列表 API 调用:
- 任何 Clear 方法
- 任何 Copy 方法
- DiscardResource
- ExecuteBundle
- ResourceBarrier
- ResolveSubresource
- SetPredication
- BeginQuery
- EndQuery
- SOSetTargets
- OMSetRenderTargets
- RSSetViewports
- RSSetScissorRects
可以在捆绑包上调用 SetDescriptorHeaps,但捆绑描述符堆必须与调用命令列表描述符堆匹配。
如果在捆绑包上调用了这些 API 中的任何一个,运行时将删除调用。 每当出现此错误时,调试层都会发出错误。