语音输入

在 HoloLens 上,语音是重要输入形式之一。 可以通过它直接命令某个全息影像,不需使用手势。 可以将语音输入作为一种传达意图的自然方式。 语音特别适合遍历复杂接口,因为它允许用户通过一个命令来访问嵌套菜单。
语音输入由在所有通用 Windows 应用中支持语音的同一引擎提供支持。 在 HoloLens 上,语音识别始终在设备“设置”中配置的 Windows 显示语言中运作。
语音和凝视
使用语音命令时,头部或眼睛凝视是典型的瞄准机制,无论是使用光标进行“选择”还是将命令传递给正在注视的应用程序。 甚至可能不需要显示任何凝视光标(“看到它,说出来”)。 有些语音命令根本不需要目标,例如“转到开始菜单”或“你好小娜”。
设备支持
| 功能 | HoloLens(第一代) | HoloLens 2 | 沉浸式头戴显示设备 |
| 语音输入 | ✔ | ✔ | ✔️(带麦克风) |
“选择”命令
HoloLens(第一代)
即使你的应用没有专门添加语音支持,用户也可以简单地通过系统语音命令“选择”来激活全息影像。 此行为与 HoloLens 上的隔空敲击相同,按下 HoloLens 点击器上的“选择”按钮或按下 Windows Mixed Reality 运动控制器上的触发器。 你将听到一个声音,并看到带有“选择”的工具提示作为确认显示。 “选择”是通过低功耗关键字检测算法启用的,这意味着你可以随时发出该口令,这对电池使用时间的影响是非常小的。 甚至可以把手放在身体两侧发出“选择”口令。
HoloLens 2
若要在 HoloLens 2 上使用“选择”语音命令,首先需要打开凝视光标作为指针。 启用口令很容易记住,只需说“选择”。
若要退出模式,请再次使用手进行隔空敲击,用手指接近按钮或使用系统手势。
图像:发出“选择”口令以使用语音命令进行选择

你好小娜
可以说“你好小娜”,随时启动 Cortana。 你不必等待她出现,继续询问你的问题或向她提供指令。 例如,尝试说出一个句子“你好小娜,今天天气怎么样?”。 要详细了解 Cortana 以及你可以做什么,请询问她! 说“你好小娜,我可以说什么?”,她将拉取一个工作命令和建议命令列表。 如果正在使用 Cortana 应用,请选择边栏上的“?”图标以拉取此同一菜单。
HoloLens 特定命令
- “我可以说什么?”
- “转到开始菜单”- 而不是使用开花手势来访问开始菜单
- “启动 <应用>”
- “将 <应用> 移至此处”
- “拍摄照片”
- “开始录制”
- “停止录制”
- “显示手部射线”
- “隐藏手部射线”
- “增加亮度”
- “降低亮度”
- “提高音量”
- “降低音量”
- “静音”或“取消静音”
- “关闭设备”
- “重新启动设备”
- “进入睡眠状态”
- “What time is it?”
- “我还剩多少电量?”
“看到它,说出来”
HoloLens 语音输入的“看到它,说出来”模型,其中按钮上的标签告诉用户他们还可以发出哪些语音命令。 例如,查看 HoloLens(第一代)的应用窗口时,用户可以发出“调整”命令来调整应用在世界中的位置。
图像:用户可以发出“调整”命令,他们可在应用栏中看到该命令来调整应用的位置

当应用遵循此规则时,用户可以轻松了解说什么来控制系统。 在 HoloLens(第 1 代)中注视按钮时,如果按钮已启用语音,你会看到“声音停留”工具提示,如果该按钮支持语音,那么它会在一秒钟后出现,并显示命令要求你发出“按下”它的口令。 若要在 HoloLens 2 中显示语音工具提示,请通过说“选择”或“我可以说什么”来显示语音光标(查看图像)。
图像:“看到它,说出来”命令显示在按钮下方
用于快速全息影像操作的语音命令
在凝视全息影像以快速执行操作任务时,可以发出很多语音命令。 这些语音命令在应用窗口和已放置在世界中的 3D 对象上工作。
全息影像操作命令
- 正面朝我
- 放大 | 增强
- 缩小
在 HoloLens 2 上,还可以与眼睛凝视一起创建更自然的交互,这种方式隐式提供有关所引用内容的上下文信息。 例如,你可以注视全息影像并说“放置此对象”,然后查看要放置它的位置,并说“放在这里”。 或者,你可以注视复杂计算机上的全息部分,并说:“请提供有关此对象的更多信息。
发现语音命令
某些命令(如上述用于快速操作的命令)可以隐藏。 若要了解可以使用哪些命令,请凝视对象,说“我可以说什么?”。 随即弹出可能的命令列表。 还可使用头部凝视光标查看四周,并显示你面前每个按钮的语音提示。
如果需要完整列表,只需随时说“显示所有命令”。
听写
相比使用隔空敲击键入内容,语音听写可以更有效地在应用中输入文本。 这可以大大加快输入速度,并减少用户的工作量。
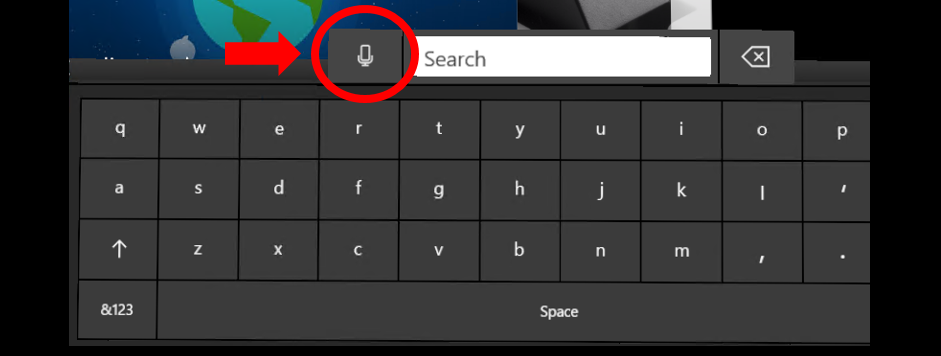
语音听写通过选择键盘上的麦克风按钮开始
只要全息键盘处于活动状态,就可以切换到听写模式,而不是键入。 选择文本输入框一侧的麦克风以开始。
向应用添加语音命令
考虑为生成的任何体验添加语音命令。 语音是控制系统和应用的强大方式。 由于用户说话带有各种方言和口音,正确选择语音关键字将确保用户的命令得到清晰的解释。
最佳实践
以下是一些有助于流畅语音识别的做法。
- 使用简明命令 - 如果可能的话,选择两个或更多音节的关键词。 不同口音的人说单音节词时倾向于使用不同的元音。 示例:“播放视频”优于“播放当前所选视频”
- 使用简单词汇 - 示例:“显示通知”优于“显示标语牌”
- 确保命令是非破坏性的 - 确保任何语音命令操作都是非破坏性的,并且可以很容易地撤消,以防在用户附近说话的另一个人意外触发命令。
- 避免使用类似的语音命令 - 避免注册多个听起来相似的语音命令。 示例:“显示更多”(Show more) 和“显示商店”(Show store) 就很相似。
- 不使用应用时取消注册应用 - 当应用没有处于特定语音命令有效的状态时,请考虑取消注册应用,使其他命令不会与该命令混淆。
- 使用不同的口音进行测试 - 由具有不同口音的用户测试应用。
- 保持语音命令一致性 - 如果“返回”可转到上一页,请在应用程序中保持此行为。
- 避免使用系统命令 - 系统保留了以下语音命令,因此避免在应用程序中使用它们:
- “你好小娜”
- “选择”
- “转到开始菜单”
语音输入的优点
语音输入是传达我们意图的自然方式。 语音特别适用于接口遍历,因为它可以帮助用户完成接口的多个步骤。 在查看某个网页时,用户可以说“返回”,而无需向上并点击应用中的后退按钮。 少量的时间节省对用户的体验感知具有强大的情感效应,并赋予了他们一点超能力。 当我们忙得不可开交或同时处理多项任务时,使用语音也是一种方便的输入方法。 在难以在键盘上打字的设备上,语音听写可能是一种高效的替代文本输入方式。 最后,在某些情况下,当凝视和手势的精度范围有限时,语音可以帮助明确用户的意图。
语音的使用如何让用户受益
- 省时 - 它应该使最终目标更高效。
- 最大限度地减少工作量 - 它应该使任务更加流畅和轻松。
- 减少认知压力 - 它是直观的,易于学习和记忆。
- 这从社会学角度看是可接受的 - 操作应符合社会行为规范。
- 它是常规的 - 语音很容易成为一种习惯行为。
语音输入的挑战
虽然语音输入适用于许多不同的应用程序,但它也面临一些挑战。 了解语音输入的优势和挑战,可以让应用开发人员在如何以及何时使用语音输入方面做出更明智的选择,并为用户创造卓越的体验。
连续输入控制的语音输入:精细控制就是其中之一。 例如,用户可能需要更改其音乐应用中的音量。 她可能会说“声音响点”,但不清楚系统应将音量调至多少。 用户可以说:“稍微响一点”,但“一点”很难量化。 使用语音移动或缩放全息影像同样较为困难。
语音输入检测的可靠性:虽然语音输入系统变得越来越好,但有时它们可能会听错或错误地解释语音命令。 关键在于应对应用程序中的挑战。 当系统正在倾听时,向用户提供反馈,系统所理解的内容阐明了理解用户语音的潜在问题。
共享空间中的语音输:在与他人共享的空间内,语音在社交上可能不被接受。 以下是一些示例:
- 用户可能不希望干扰其他人(例如,在安静的图书馆或共享办公室)
- 在公共场合与自己交谈时,用户可能会感到尴尬,
- 在口述个人或机密消息(包括密码)的同时其他人也会听到,这会让用户感觉不舒服
唯一或未知单词的语音输入:当用户口述系统可能未知的字词(如昵称、某些俚语单词或缩写)时,也难以进行语音输入。
学习语音命令:虽然最终目标是自然地与系统进行交谈,但应用通常仍依赖于特定的预定义语音命令。 与一组重要的语音命令相关的一项挑战是,如何在不让用户负担过重的情况下传授给他们,以及如何帮助用户记住这些语音命令。
语音反馈状态
当语音应用正确时,用户了解他们能说什么,并得到清晰的反馈 - 系统正确地听到了用户说的话。 这两个信号使用户在使用语音作为主要输入方法时充满自信。 下面的图表显示了识别语音输入时光标发生的情况以及它是如何将信息传达给用户的。

1. 常规光标状态

2. 传达语音反馈,然后消失
3. 返回到常规光标状态
在混合现实中,用户应该知道的关于“语音”的重要事项
- 在将一个按钮设置为目标时,说“选择”(可以在任何位置使用这种方法来选择按钮)。
- 可以在某些应用中通过说出应用栏按钮的标签名称来执行操作。 例如,在查看应用时,用户可以说“移除”命令,从现实中移除应用(这样可以节省用手选择按钮的时间)。
- 你可以说“你好小娜”让 Cortana 开始倾听。你可以向她提问(“你好小娜,埃菲尔铁塔有多高”),告诉她打开应用(“你好小娜,打开 Netflix”),或告诉她调出“开始”菜单(“你好小娜,带我去主页”)等等。
用户对语音的常见问题和关注点
- 我可以说什么?
- 我如何知道系统正确听到了我说的话?
- 系统总是理解错误我的语音命令。
- 当我发出语音命令时,系统不会做出反应。
- 当我发出语音命令时,系统的反应是错误的。
- 我如何将我的语音定向到一个特定的应用或应用命令?
- 我可以使用语音来对 HoloLens 上的全息帧执行命令吗?
通信
对于想要利用 HoloLens 提供的自定义音频输入处理选项的应用程序,了解应用可以使用的各种音频流类别非常重要。 Windows 10 支持多个不同的流类别,HoloLens 利用其中三种类别来启用自定义处理,以优化为语音、通信和其他功能定制的麦克风音频质量,可用于环境音频捕获(即“摄录机”)场景。
- AudioCategory_Communications 流类别针对通话质量和旁白场景进行自定义,为客户端提供用户语音的 16 kHz 24 位单声道音频流
- AudioCategory_Speech 流类别为 HoloLens (Windows) 语音引擎自定义,并提供用户语音的 16 kHz 24 位单声道流。 如果需要,第三方语音引擎可以使用此类别。
- AudioCategory_Other 流类别为环境音频录制自定义,为客户端提供 48 kHz 24 位立体声音频流。
所有这些音频处理都是硬件加速的,这意味着与在 HoloLens CPU 上执行相同的处理相比,其功能耗电量要小得多。 避免在 CPU 上运行其他音频输入处理,以最大程度地延长系统电池使用时间,并充分利用内置的卸载音频输入处理。
语言
HoloLens 2 支持多种语言。 请记住,即使安装了多个键盘,或者应用尝试使用不同的语言创建语音识别器,语音命令也始终以系统的显示语言运行。
疑难解答
如果在使用“选择”和“你好小娜”时遇到任何问题,请尝试移动到更安静的空间,远离干扰源,或者说话声音更大一点。 目前,HoloLens 上的所有语音识别都是专门针对美国英语母语人士进行调整和优化的。
对于 Windows Mixed Reality Developer Edition 2017,在初始 HMD 连接后注销并返回到电脑桌面后,音频终结点管理逻辑将(永久)正常工作。 在通过 WMR OOBE 后首次注销/登录事件之前,用户可能会遇到各种音频功能问题,从无音频到无音频切换,具体取决于首次连接 HMD 之前系统的设置方式。
Unity 的 MRTK(混合现实工具包)中的语音输入
使用 MRTK,可以轻松地在任何对象上分配语音命令。 使用 MRTK 的“语音输入配置文件”来定义关键字。 通过分配“SpeechInputHandler”脚本,可以使任何对象响应“语音输入配置文件”中定义的关键字。 SpeechInputHandler 还提供语音确认标签以提高用户的信任度。