准备使用 Apache Spark
Apache Spark 是一个分布式数据处理框架,通过协调群集中多个处理节点之间的工作,实现大规模数据分析,在 Microsoft Fabric 中,这种群集被称为 Spark 池。 更简单地说,Spark 使用“分治法”,通过跨多台计算机分发工作来快速处理大量数据。 分发任务和整理结果的过程由 Spark 进行处理。
Spark 可运行以各种语言编写的代码,这些语言包括 Java、Scala(基于 Java 的脚本语言)、Spark R、Spark SQL 和 PySpark(Python 的特定于 Spark 的变体)。 实际上,大多数数据工程和分析工作负载都是通过结合使用 PySpark 和 Spark SQL 来完成的。
Spark 池
Spark 池由分配数据处理任务的计算节点组成。 下图显示了一般体系结构。
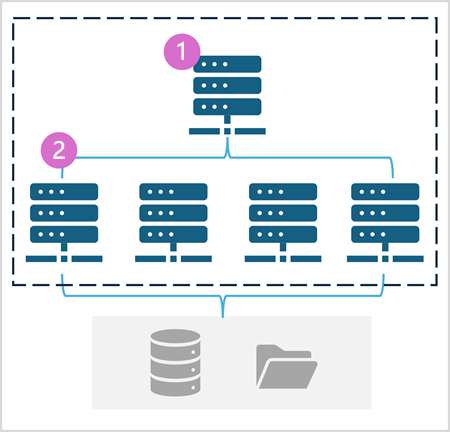
如图所示,Spark 池包含两种类型的节点:
- Spark 池中的头节点通过驱动程序协调分布式进程。
- 池中包括多个工作器节点,在这些节点上,执行程序进程执行实际数据处理任务。
Spark 池使用这种分布式计算体系结构来访问和处理兼容数据存储中的数据,例如基于 OneLake 的数据湖屋。
Microsoft Fabric 中的 Spark 池
Microsoft Fabric 在每个工作区中都提供了一个初学者池,以便用户快速启动和运行 Spark 作业,而不需要过多的设置和配置。 可以对初学者池进行配置,以便根据特定的工作负载需求或成本约束来优化其中包含的节点。
此外,还可以创建具有特定节点配置的自定义 Spark 池,以满足特定数据处理需求。
注意
Fabric 管理员可以在 Fabric 容量级别禁用自定义 Spark 池设置的功能。 有关详细信息,请参阅 Fabric 文档中的数据工程和数据科学的容量管理设置。
可以在工作区设置的“数据工程/科学”部分管理初学者池的设置并创建新的 Spark 池。
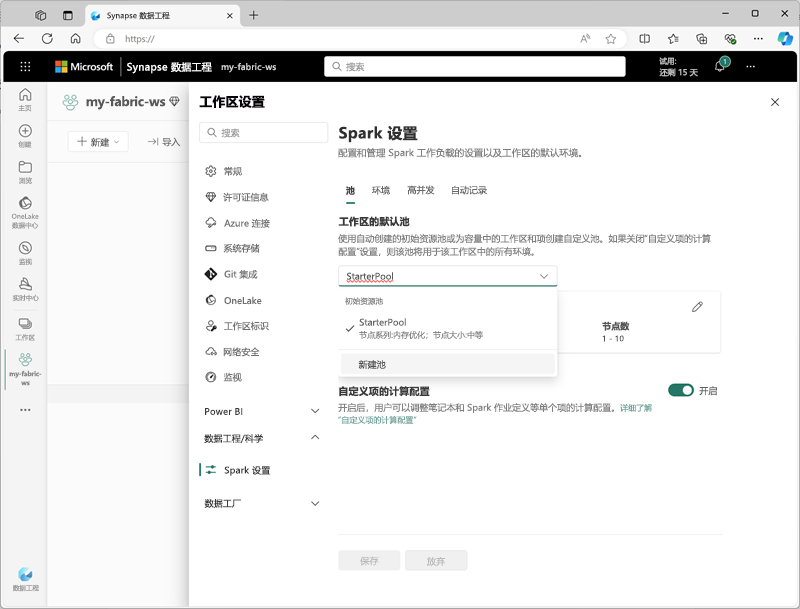
Spark 池的特定配置设置包括:
- 节点系列:用于 Spark 群集节点的虚拟机类型。 在大多数情况下,内存优化节点提供最佳性能。
- 自动缩放:是否根据需要自动预配节点,如果是,则需要指定分配给池的初始节点数和最大节点数。
- 动态分配:是否根据数据量在工作器节点上动态分配执行程序进程。
如果在工作区中创建了一个或多个自定义 Spark 池,则可以将其中一个(或初学者池)设置为默认池,以便在没有为给定 Spark 作业指定特定池时使用。
提示
有关如何在 Microsoft Fabric 中管理 Spark 池的详细信息,请参阅 Microsoft Fabric 文档中的在 Microsoft Fabric 中配置初学者池和如何在 Microsoft Fabric 中创建自定义 Spark 池。
运行时和环境
Spark 开放源代码生态系统包括多个版本的 Spark 运行时,它决定了所安装的 Apache Spark、Delta Lake、Python 和其他核心软件组件的版本。 此外,还可以在运行时中安装和使用各种代码库来执行常见的任务(有时也包括非常特殊的任务)。 由于大量 Spark 处理是使用 PySpark 执行的,因此大量的 Python 库可确保无论需要执行什么任务,都有一个库可以提供帮助。
在某些情况下,组织可能需要定义多个环境,以支持各种数据处理任务。 每个环境定义了一个特定的运行时版本,以及执行特定操作必须安装的库。 然后,数据工程师和科学家就可以选择在特定任务中与 Spark 池一起使用的环境。
Microsoft Fabric 中的 Spark 运行时
Microsoft Fabric 支持多个 Spark 运行时,并将继续支持新发布的运行时。 可以通过工作区设置界面指定启动 Spark 池时默认环境使用的 Spark 运行时。
提示
有关 Microsoft Fabric 中 Spark 运行时的详细信息,请参阅 Microsoft Fabric 文档中的 Fabric 中的 Apache Spark 运行时。
Microsoft Fabric 中的环境
可以在 Fabric 工作区中创建自定义环境,以便针对不同的数据处理操作使用特定的 Spark 运行时、库和配置设置。
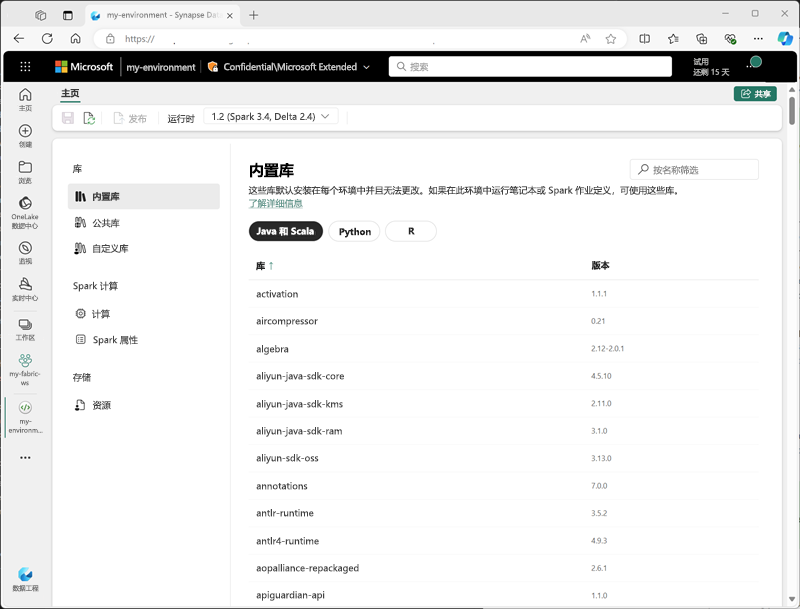
创建环境时,可以:
- 指定应使用的 Spark 运行时。
- 查看每个环境中安装的内置库。
- 从 Python 包索引 (PyPI) 安装特定的公共库。
- 通过上传包文件来安装自定义库。
- 指定环境应使用的 Spark 池。
- 指定 Spark 配置属性以替代默认行为。
- 上传需要在环境中提供的资源文件。
在创建了至少一个自定义环境后,可以在工作区设置中将其指定为默认环境。
提示
有关如何在 Microsoft Fabric 中使用自定义环境的详细信息,请参阅 Microsoft Fabric 文档中的在 Microsoft Fabric 中创建、配置和使用环境。
其他 Spark 配置选项
管理 Spark 池和环境是在 Fabric 工作区中管理 Spark 处理的主要方式。 不过,还可以使用一些其他选项进行进一步优化。
本机执行引擎
Microsoft Fabric 中的本机执行引擎是一种矢量化处理引擎,可直接在湖屋基础结构上运行 Spark 操作。 在处理 Parquet 或 Delta 文件格式的大型数据集时,使用本机执行引擎可以显著提高查询的性能。
若要使用本机执行引擎,可以在环境级别或单个笔记本中启用它。 若要在环境级别启用本机执行引擎,请在环境配置中设置以下 Spark 属性:
- spark.native.enabled:true
- spark.shuffle.manager:org.apache.spark.shuffle.sort.ColumnarShuffleManager
若要为特定脚本或笔记本启用本机执行引擎,可以在代码开头设置这些配置属性,如下所示:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
提示
有关本机执行引擎的详细信息,请参阅 Microsoft Fabric 文档中的 Fabric Spark 的本机执行引擎。
高并发模式
在 Microsoft Fabric 中运行 Spark 代码时,会启动 Spark 会话。 可以使用高并发模式在多个并发用户或进程之间共享 Spark 会话,从而优化 Spark 资源的使用效率。 为笔记本启用高并发模式后,多个用户可以在使用同一 Spark 会话的笔记本中运行代码,同时确保代码隔离,避免一个笔记本中的变量受到另一个笔记本中代码的影响。 还可以为 Spark 作业启用高并发模式,从而在并发执行非交互式 Spark 脚本时实现类似的效率。
要启用高并发模式,请使用工作区设置界面的“数据工程/科学”部分。
提示
有关高并发模式的详细信息,请参阅 Microsoft Fabric 文档中的 Apache Spark for Fabric 中的高并发模式。
自动 MLFlow 日志记录
MLFlow 是一个开放源代码库,用于在数据科学工作负载中管理机器学习训练和模型部署。 MLFlow 的一个关键功能是能够记录模型训练和管理操作。 默认情况下,Microsoft Fabric 使用 MLFlow 隐式记录机器学习试验活动,而不需要数据科学家包含显式代码来实现。 可以在工作区设置中禁用此功能。
Fabric 容量的 Spark 管理
管理员可以在 Fabric 容量级别管理 Spark 设置,从而能够限制和覆盖组织内工作区中的 Spark 设置。
提示
有关如何在 Fabric 容量级别管理 Spark 配置的详细信息,请参阅 Microsoft Fabric 文档中配置和管理 Fabric 容量的数据工程和数据科学设置。