Fabric Spark 的本机执行引擎
本机执行引擎是 Microsoft Fabric 中 Apache Spark 作业执行的突破性增强功能。 此矢量化引擎通过直接在 Lakehouse 基础结构上运行 Spark 查询来优化这些查询的性能和效率。 引擎的无缝集成意味着无需修改代码,并可避免供应商锁定。 它支持 Apache Spark API,并且与 Runtime 1.3 (Apache Spark 3.5) 兼容,适用于 Parquet 和 Delta 格式。 无论数据在 OneLake 中的位置如何,或者是否通过快捷方式访问数据,本机执行引擎都会最大限度地提高效率和性能。
本机执行引擎可显著提升查询性能,同时最大限度地降低运营成本。 与传统 OSS(开源软件)Spark 相比,它提供非凡的速度提升,最高可达四倍,并已通过 TPC-DS 1 TB 基准验证。 该引擎擅长管理各种数据处理应用场景,从常规数据引入、批处理作业和 ETL(提取、转换、加载)任务到复杂的数据科学分析和响应式交互查询。 用户受益于加速的处理时间、提高的吞吐量和优化的资源利用率。
本机执行引擎基于两个关键 OSS 组件:Velox、Meta 引入的 C++ 数据库加速库和 Apache Gluten (incubating),这是一个中间层,负责将基于 JVM 的 SQL 引擎的执行卸载到 Intel 引入的本机引擎。
注意
本机执行引擎目前提供公共预览版。 有关详细信息,请参阅当前限制。 我们鼓励在工作负载上启用本机执行引擎,无需额外付费。 你将受益于更快的作业执行,而无需支付更多费用 - 实际上,你为相同的工作支付得更少。
何时使用本机执行引擎
本机执行引擎提供了一个解决方案,用于在大型数据集上运行查询;其通过使用底层数据源的本机功能来优化性能,并将通常与传统 Spark 环境中的数据移动和序列化相关的开销降到最低。 该引擎支持各种运算符和数据类型,包括汇总哈希聚合、广播嵌套循环联接 (BNLJ) 和精确的时间戳格式。 但是,要充分利用引擎的功能,应考虑其最佳用例:
- 使用 Parquet 和 Delta 格式的数据时,该引擎非常有效,其可以在本机高效地处理这些数据。
- 涉及复杂转换和聚合的查询可从引擎的列式处理和矢量化功能受益匪浅。
- 性能增强在查询不通过避免不支持的功能或表达式来触发回退机制的应用场景最为显著。
- 该引擎非常适合计算密集型查询,而不是简单或 I/O 绑定查询。
有关本机执行引擎支持的运算符和函数的信息,请参阅 Apache Gluten 文档。
启用本机执行引擎
要在预览阶段使用本机执行引擎的完整功能,需要特定的配置。 以下过程演示如何为笔记本、Spark 作业定义和整个环境激活此功能。
重要
本机执行引擎支持最新的 GA 运行时版本,即 Runtime 1.3(Apache Spark 3.5、Delta Lake 3.2)。 在 Runtime 1.3 中发布本机执行引擎后,已停止对以前的版本的支持:Runtime 1.2(Apache Spark 3.4、Delta Lake 2.4)。 我们鼓励所有客户升级到最新的 Runtime 1.3。 如果您在 Runtime 1.2 上使用本机执行引擎,本机加速即将被禁用。
在环境级别启用
为了确保统一性能增强,请在与环境关联的所有作业和笔记本上启用本机执行引擎:
导航到环境设置。
转到“Spark 计算”。
转到“加速”选项卡。
选中标记为“启用本机执行引擎”的框。
“保存和发布”更改。
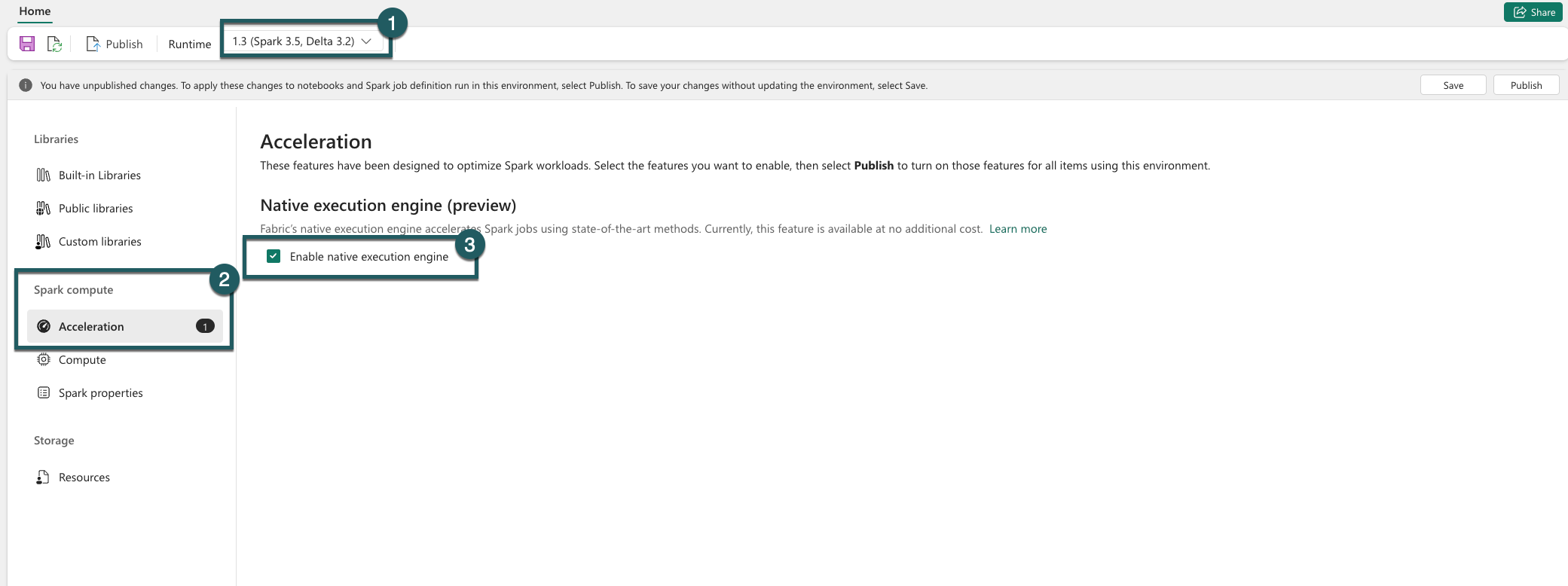

在环境级别启用时,所有后续作业和笔记本都会继承该设置。 此继承可确保环境中创建的任何新会话或资源都自动受益于增强的执行功能。
重要
以前,本机执行引擎是通过环境配置中的 Spark 设置启用的。 随着最新更新(正在推出)的发布,我们通过在环境设置的“加速”选项卡中引入切换按钮来简化此操作。 使用新开关重新启用本机执行引擎 - 若要继续使用本机执行引擎,请转到环境设置中的“加速”选项卡,并通过切换按钮启用它。 UI 中新的切换设置现在优先于以前的任何 Spark 属性配置。 如果以前通过 Spark 设置启用了本机执行引擎,则会禁用它,直到通过 UI 切换重新启用。
为笔记本或 Spark 作业定义启用
要为单个笔记本或 Spark 作业定义启用本机执行引擎,必须在执行脚本的开头合并必要的配置:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
对于笔记本,在第一个单元格中插入所需的配置命令。 对于 Spark 作业定义,请在 Spark 作业定义的前线包括配置。 本机执行引擎与实时池集成,因此启用该功能后,它会立即生效,而无需启动新会话。
重要
必须在发起 Spark 会话之前完成本机执行引擎的配置。 启动 Spark 会话后,spark.shuffle.manager 设置变为不可变,无法进行更改。 确保在笔记本的 %%configure 块内或 Spark 会话生成器中为 Spark 作业定义设置这些配置。
在查询级别控制
在租户、工作区和环境级别上启用本机执行引擎(与 UI 无缝集成)的机制正在积极开发中。 此外,还可以针对特定查询禁用本机执行引擎,特别是涉及当前不支持的运算符时(请参阅限制)。 若要禁用,请将包含该查询的特定单元格的 Spark 配置 spark.native.enabled 设置为 false。
%%sql
SET spark.native.enabled=FALSE;

执行禁用本机执行引擎的查询后,必须通过将 spark.native.enabled 设置为 true 为后续单元格重新启用它。 此步骤是必需的,因为 Spark 按顺序执行代码单元。
%%sql
SET spark.native.enabled=TRUE;
识别引擎执行的操作
有多种方法可确定 Apache Spark 作业中的运算符是否使用本机执行引擎进行处理。
Spark UI 和 Spark 历史记录服务器
访问 Spark UI 或 Spark 历史记录服务器以找到需要检查的查询。 若要访问 Spark Web UI,请导航到 Spark 作业定义并运行它。 在“运行”选项卡中,选择在 应用程序名称 旁边的“...”,然后选择 打开 Spark Web UI。 还可以从工作区中的“监视”选项卡访问 Spark UI。 从监视页中选择笔记本或管道,会出现指向活动作业 Spark UI 的直接链接。

在 Spark UI 界面中显示的查询计划中,查找以 Transformer、*NativeFileScan 或 VeloxColumnarToRowExec作为后缀结尾的任何节点名称。 该后缀表示本机执行引擎执行了该操作。 例如,节点可能标记为 RollUpHashAggregateTransformer、ProjectExecTransformer、BroadcastHashJoinExecTransformer、ShuffledHashJoinExecTransformer 或 BroadcastNestedLoopJoinExecTransformer。

数据帧说明
或者,可以在笔记本中执行 df.explain() 命令以查看执行计划。 在输出中,查找相同的“Transformer”、“*NativeFileScan”或“VeloxColumnarToRowExec”后缀。 此方法可快速确认是否由本机执行引擎处理特定操作。

回退机制
在某些情况下,本机执行引擎可能由于不支持的功能等原因而无法执行查询。 在这些情况下,该操作会回退到传统的 Spark 引擎。 此自动回退机制可确保工作流不会中断。


监视引擎执行的查询和 DataFrame
为了更好地了解本机执行引擎如何应用于 SQL 查询和 DataFrame 操作,以及向下钻取到阶段和运算符级别,可以参考 Spark UI 和 Spark 历史记录服务器了解有关本机引擎执行的详细信息。
本机执行引擎选项卡
可以导航到新的“Gluten SQL/DataFrame”选项卡,查看 Gluten 生成信息和查询执行详细信息。 查询表提供有关本机引擎上运行的节点数以及每个查询回退到 JVM 的节点数的见解。

查询执行图
您还可以选择查询说明以进行 Apache Spark 查询执行计划的可视化。 执行图跨阶段及其各自的操作提供本机执行详细信息。 背景色区分执行引擎:绿色表示本机执行引擎,而浅蓝色表示操作在默认 JVM 引擎上运行。

限制
虽然本机执行引擎增强了 Apache Spark 作业的性能,但请注意其当前限制。
- 不支持某些特定于 Delta 的操作(尚不支持,我们正在积极推进),包括合并操作、检查点扫描和删除向量。
- 某些 Spark 功能和表达式与本机执行引擎不兼容,例如用户定义的函数 (UDF) 和
array_contains函数,以及 Spark 结构化流式处理。 将这些不兼容的操作或函数用作导入库的一部分也会导致 Spark 引擎的回退。 - 不支持从使用专用终结点的存储解决方案进行扫描(尚不支持,我们正在积极推进)。
- 该引擎不支持 ANSI 模式,因此它会进行搜索,ANSI 模式启用后,它会自动回退到 vanilla Spark。
在查询中使用日期筛选器时,必须确保两边的比较数据类型一致以避免性能问题。 不匹配的数据类型可能无法提升查询执行,并可能需要显式强制转换。 始终确保比较左侧 (LHS) 和右侧 (RHS) 的数据类型相同,因为不匹配的类型并非总能自动强制转换。 如果无法避免类型不匹配,请使用显式强制转换来匹配数据类型,例如 CAST(order_date AS DATE) = '2024-05-20'。 原生执行引擎不会加速有不匹配数据类型(需要强制转换)的查询,因此确保类型一致性对于维持性能至关重要。 例如,不适用 order_date = '2024-05-20' 为 order_date 且字符串为 DATETIME 的 DATE,而是将 order_date 显式强制转换为 DATE,以确保一致的数据类型并提高性能。