从 OneLake 获取数据
本文介绍如何将数据从 OneLake 获取到新的表或现有表。
先决条件
从 Lakehouse 复制文件路径
从工作区中,选择包含要使用的数据源的湖屋环境。
将光标置于所需文件上,然后选择 “更多”(...) 菜单,然后选择 属性。
重要
- 不支持文件夹路径。
- 不支持通配符 (*)。

在“URL”下,选择“复制到剪贴板”图标,并将其保存到某个位置,以便在后续步骤中检索。

返回到工作区并选择 KQL 数据库。


源
在 KQL 数据库的下方功能区中,选择“获取数据”。
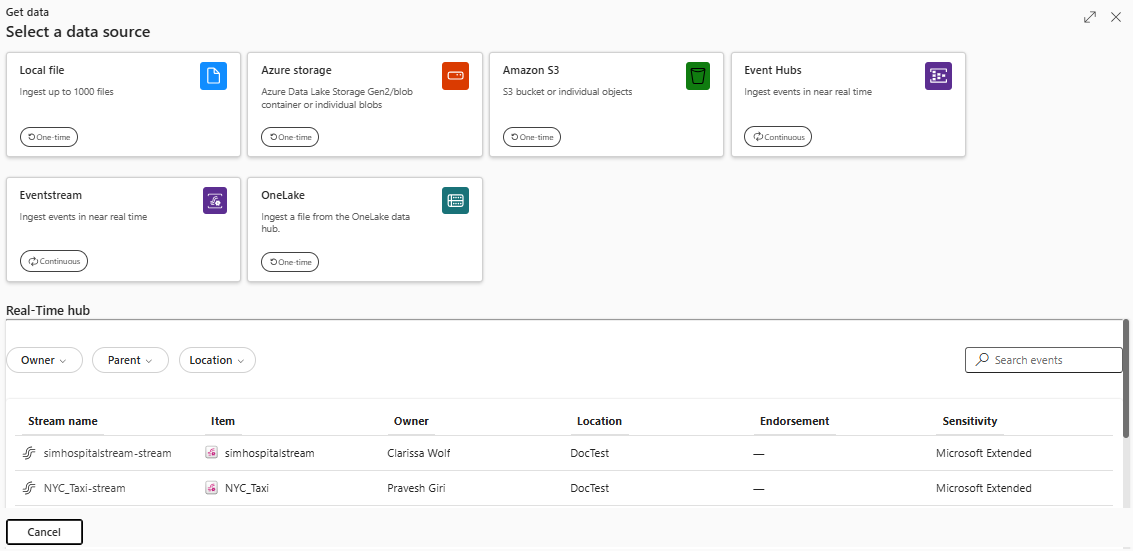
在“获取数据”窗口中,选中了“源”选项卡。
从可用列表中选择数据源。 在此示例中,你将从 OneLake 引入数据。

配置
选择目标表。 如果要将数据引入新表,请选择 +新建表 并输入表名称。
注意
表名最多可包含 1024 个字符,包括空格、字母数字、连字符和下划线。 不支持特殊字符。
在“OneLake 文件”中,粘贴在“从湖屋复制文件路径”中复制的湖屋文件路径。
注意
您最多可以添加 10 个项目,每个项目的未压缩大小高达 1 GB。
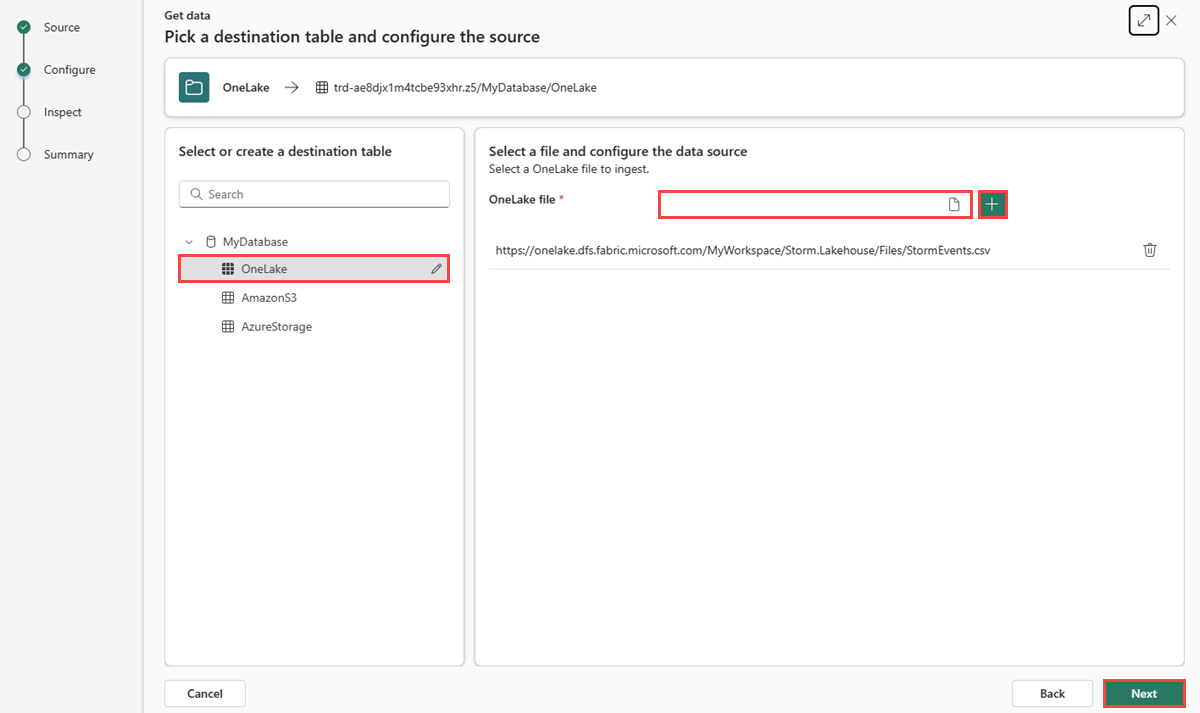
选择 下一步。

检查
此时会打开“检查”选项卡,其中包含数据的预览。
要完成引入过程,请选择“完成”。

可选:
- 选择 命令查看器 以查看和复制从输入生成的自动命令。
- 使用“架构定义文件”下拉列表更改从中推断架构的文件。
- 通过从下拉列表中选择所需格式来更改自动推断的数据格式。 有关详细信息,请参阅实时智能支持的数据格式。
- 编辑列。
- 浏览基于数据类型的高级选项。
编辑列
注意
- 对于表格格式(CSV、TSV、PSV),不能映射列两次。 若要映射到现有列,请先删除新列。
- 无法更改现有列类型。 如果尝试将数据映射到格式不同的列,则最终可能会出现空列。
可以在表中所做的更改取决于以下参数:
- 表类型为“新”或“现有”
- 映射类型为“新”或“现有”
| 表类型 | 映射类型 | 可用调整 |
|---|---|---|
| 新建表 | 新映射 | 重命名列、更改数据类型、更改数据源、映射转换、添加列、删除列 |
| 现有表 | 新映射 | 添加列(然后可以更改数据类型、重命名和更新) |
| 现有表 | 现有映射 | 没有 |

映射转换
某些数据格式映射(Parquet、JSON 和 Avro)支持简单的引入时间转换。 若要应用映射转换,请在 编辑列 窗口中创建或更新列。
可以对字符串或日期时间类型的列执行映射转换,源的数据类型为 int 或 long。 支持的映射转换为:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
基于数据类型的高级选项
表格(CSV、TSV、PSV):
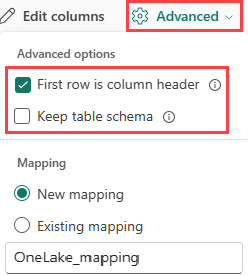
如果要在现有表中引入表格格式,可以选择“高级”>“保留表架构”。 表格数据不一定包括用于将源数据映射到现有列的列名。 选中此选项后,按顺序完成映射,表架构保持不变。 如果未选中此选项,则会为传入数据创建新列,而不考虑数据结构。
若要将第一行作为列名称,请选择 高级>第一行是列标题。
JSON:
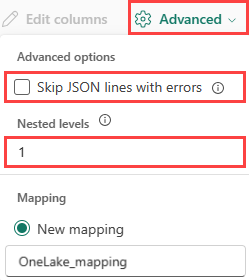
若要确定 JSON 数据的列划分,请选择 高级>嵌套级别,从 1 到 100。
如果选择 高级>跳过包含错误的 JSON 行,则数据将以 JSON 格式引入。 如果取消选中此复选框,则会以多JSON格式导入数据。
总结
在 数据准备 窗口中,当数据导入成功完成时,所有三个步骤都打有绿色勾。 可以选择要查询的卡,下拉引入的数据,也可以查看引入摘要的仪表板。
