在 Microsoft Fabric 中管理 Apache Spark 库
库是预先编写的代码的集合,开发人员可以导入这些代码以提供额外的功能。 使用库时,无需从头开始编写代码即可完成常见的任务, 只需导入库并使用其函数和类来实现所需的功能,从而节省时间和精力。 Microsoft Fabric 提供了多种机制来帮助管理和使用库。
- 内置库:每个 Fabric Spark 运行时都提供了一组丰富的常用预安装库。 可以在 Fabric Spark 运行时中找到完整的内置库列表。
- 公共库:公用库源自当前受支持的 PyPI 和 Conda 等存储库。
- 自定义库:自定义库是你或你的组织构建的代码。 Fabric 支持 .whl、.jar 和 .tar.gz 等格式。 对于 R 语言,Fabric 仅支持 .tar.gz。 对于 Python 自定义库,请使用 .whl 格式。
库管理最佳做法摘要
以下方案描述了在 Microsoft Fabric 中使用库时的最佳做法。
场景 1:管理员为工作区设置默认库
要设置默认库,你必须是工作区的管理员。 管理员可以执行以下任务:
工作区中的笔记本和 Spark 作业定义附加到工作区设置时,它们将启动与工作区默认环境中安装的库的会话。
场景 2:暂留一个或多个代码项的库规范
如果具有不同代码项的通用库,并且不需要频繁更新,在环境中安装库并将其附加到代码项是一个不错的选择。
发布时,使环境中的库生效需要一些时间。 它通常需要 5-15 分钟,具体取决于库的复杂性。 在此过程中,系统将帮助解决潜在的冲突并下载所需的依赖项。
此方法的一个好处是,在附加了环境的情况下启动 Spark 会话时,可以保证成功安装的库可用。它可节省为项目维护常见库的工作。
强烈建议将其稳定性用于管道方案。
场景 3:交互式运行中的内联安装
如果使用笔记本以交互方式编写代码,使用内联安装添加新的 PyPI/conda 库或验证自定义库进行一次性使用是最佳做法。 借助 Fabric 中的内联命令,你可以使库在当前笔记本 Spark 会话中生效, 它允许快速安装,但已安装的库不会在不同的会话中保留。
由于 %pip install 不时会生成不同的依赖项树,这可能会导致库冲突,因此在管道运行中默认关闭内联命令,不建议在管道中使用。
支持的库类型摘要
| 库类型 | 环境库管理 | 内联安装 |
|---|---|---|
| Python Public(PyPI 和 Conda) | 支持 | 支持 |
| Python Custom (.whl) | 支持 | 支持 |
| R Public (CRAN) | 不支持 | 支持 |
| R 自定义 (.tar.gz) | 支持作为自定义库 | 支持 |
| Jar | 支持作为自定义库 | 支持 |
内联安装
内联命令支持管理每个笔记本会话中的库。
Python 内联安装
系统会重启 Python 解释器以应用库的更改。 任何运行命令单元之前定义的变量将丢失。 强烈建议在笔记本的开头放置用于添加、删除或更新 Python 包的所有命令。
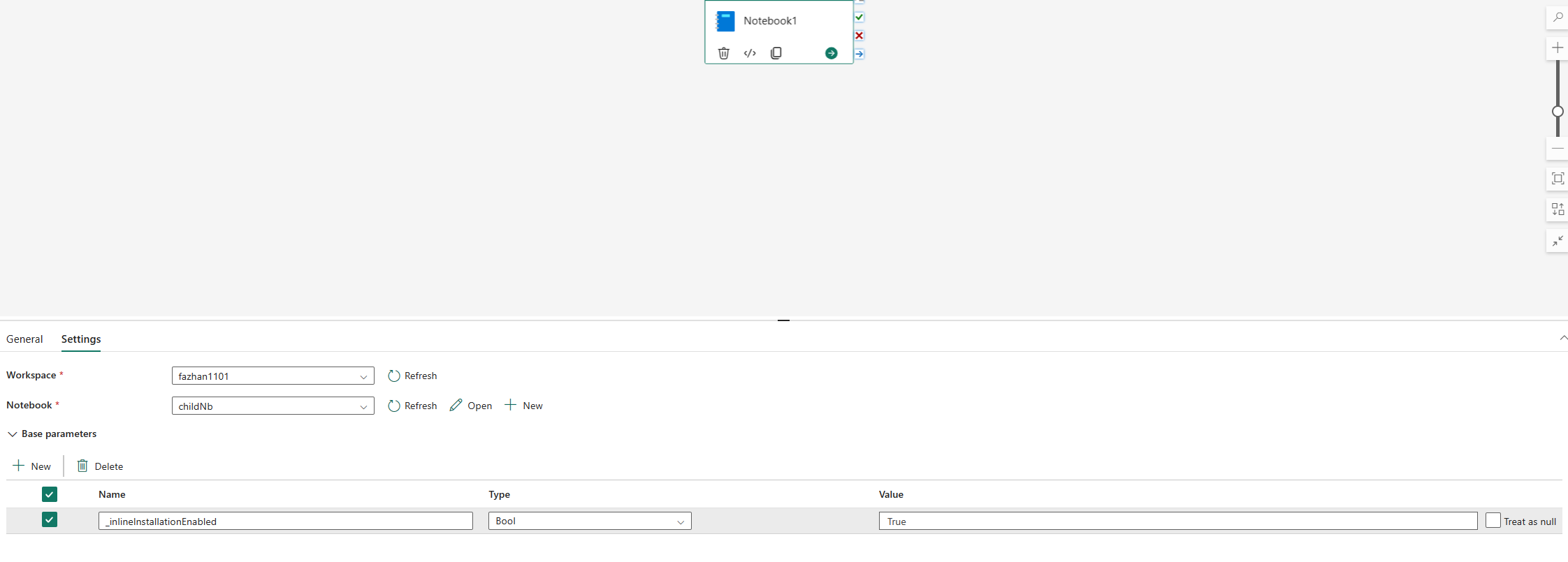
默认情况下,用于管理 Python 库的内联命令在笔记本管道运行中被禁用。 如果要为管道启用 %pip install,请在笔记本活动参数中添加“_inlineInstallationEnabled”布尔参数,其等于 True。
注意
%pip install 可能不时导致不一致的结果。 建议在环境中安装库,并在管道中使用它。
在笔记本引用运行中,用于管理 Python 库的内联命令不受支持。 为了确保正确执行,建议从引用的笔记本中删除这些内联命令。
我们建议使用 %pip,而不是 !pip。 !pip 是 IPython 内置 shell 命令,存在以下限制:
!pip仅在驱动程序节点上安装包,而不是在执行程序节点上安装。- 通过
!pip安装的包不会影响与内置包的冲突,也不影响是否已将包导入笔记本。
但是,%pip 会处理这些场景。 通过 %pip 安装的库在驱动程序和执行程序节点上都可用,即使已经导入,库仍将有效。
提示
%conda install 命令安装新 Python 库所需的时间通常比 %pip install 命令更长。 它会检查完整的依赖项并解决冲突。
使用 %conda install 可以 提高可靠性和稳定性。 如果确定要安装的库与运行时环境中预安装的库不冲突,则可以使用 %pip install。
有关所有可用的 Python 内联命令及其说明,请参阅 %pip 命令和 %conda 命令。
通过内联安装管理 Python 公共库
此示例将演示如何使用内联命令来管理库。 假设你想要使用 altair(一个强大的 Python 可视化库)进行一次性数据浏览。 假设工作区中未安装库。 以下示例使用 conda 命令来演示这些步骤。
可以使用内联命令在笔记本会话上启用 altair,而不会影响笔记本的其他会话或其他项目。
在笔记本代码单元中运行以下命令: 第一个命令会安装 altair 库。 此外还将安装 vega_datasets,其中包含可用于可视化的语义模型。
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda command该单元的输出指示安装结果。
通过在另一个笔记本单元中运行以下代码来导入包和语义模型:
import altair as alt from vega_datasets import data现在,可以使用会话范围的 altair 库:
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
通过内联安装管理 Python 自定义库
可以将 Python 自定义库上传到笔记本或附加环境的资源文件夹。 资源文件夹是每个笔记本和环境提供的内置文件系统。 有关详细信息,请参阅笔记本资源。 上传后,可以将自定义库拖放到代码单元中,自动生成用于安装库的内联命令。 或者可以使用以下命令安装。
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R 内联安装
Fabric 支持使用 install.packages()、remove.packages() 和 devtools:: 命令来管理 R 库。 有关所有可用的 R 内联命令及其说明,请参阅 install.packages 命令和 remove.package 命令。
通过内联安装管理 R 公共库
此示例将演示安装 R 公共库的步骤。
若要安装 R 源库:
在笔记本功能区中将工作语言切换到 SparkR (R)。
在笔记本单元中运行以下命令以安装 caesar 库。
install.packages("caesar")现在,可以使用 Spark 作业与会话范围的 caesar 库进行交互。
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
通过内联安装管理 Jar 库
通过以下命令在笔记本会话中为 .jar 文件提供支持。
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
代码单元使用 Lakehouse 存储作为示例。 在笔记本资源管理器中,可以复制完整的文件 ABFS 路径并在代码中替换。
