你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:使用 Azure 门户将文本和图像矢量化
本快速入门帮助你使用 Azure 门户中的“导入和矢量化数据”向导开始使用集成矢量化。 该向导对内容进行分块,并调用嵌入模型,以便在索引编制期间和为查询矢量化内容。
先决条件
Azure 订阅。 免费创建一个。
与 Azure AI 位于同一区域中的 Azure AI 搜索服务。 建议使用基本层或更高层级。
示例文档:包含运行状况计划 PDF 的受支持的数据源。
熟悉向导。 有关详细信息,请参阅 Azure 门户中的导入数据向导。
支持的数据源
“导入和矢量化数据”向导支持各种 Azure 数据源,但本快速入门仅提供适用于所有文件的数据源的步骤:
适用于 Blob 和表的 Azure Blob 存储。 Azure 存储必须为标准性能(常规用途 v2)帐户。 访问层可以是热访问层、冷访问层和寒访问层。
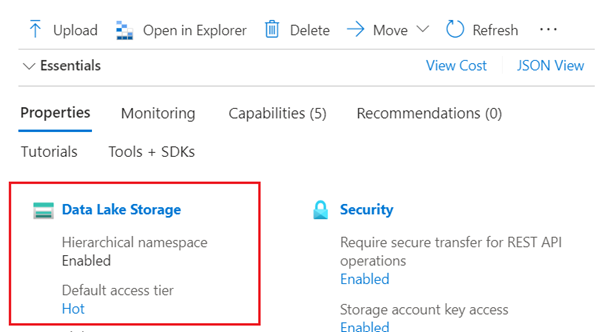
Azure Data Lake Storage (ADLS) Gen2(已启用具有分层命名空间的 Azure 存储帐户)。 可以通过在“概述”页上选中“属性”选项卡来确认 Data Lake Storage。
支持的嵌入模型
使用与 Azure AI 搜索位于同一区域的 Azure AI 平台上的嵌入模型。 本文中包含部署说明。
| 提供程序 | 支持的模型 |
|---|---|
| Azure OpenAI 服务 | text-embedding-ada-002 text-embedding-3-large text-embedding-3-small |
| Azure AI Foundry 模型目录 | 对于文本: Cohere-embed-v3-english Cohere-embed-v3-multilingual 对于图像: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Azure AI 服务多服务帐户 | Azure AI 视觉多模式用于图像和文本矢量化,在选定的区域中可用。 根据附加多服务资源的方式,多服务帐户可能需要与 Azure AI 搜索位于同一区域。 |
如果使用 Azure OpenAI 服务,终结点必须有关联的自定义子域。 自定义子域是包含唯一名称(例如 https://hereismyuniquename.cognitiveservices.azure.com)的终结点。 如果服务是通过 Azure 门户创建的,则会在服务设置过程中自动生成此子域。 确保在将服务与 Azure AI 搜索集成之前包含自定义子域。
不支持 Azure AI Foundry 门户中创建的 Azure OpenAI 服务资源(具有嵌入模型访问权限)。 只有 Azure 门户中创建的 Azure OpenAI 服务资源与 Azure OpenAI 嵌入技能集成兼容。
公共终结点要求
在本快速入门中,上述所有资源都必须启用公共访问权限,以便 Azure 门户节点可以访问它们。 否则,向导将失败。 运行向导后,你可以为集成组件启用防火墙和专用终结点以确保安全。 有关详细信息,请参阅导入向导中的安全连接。
如果专用终结点已存在并且你无法禁用它们,则另一种选择是在虚拟机上从脚本或程序运行相应的端到端流。 虚拟机必须与专用终结点位于同一虚拟网络上。 下面是用于集成矢量化的 Python 代码示例。 同一 GitHub 存储库中还包含其他编程语言的示例。
权限
可以使用密钥身份验证和完全访问连接字符串,或具有角色分配的 Microsoft Entra ID。 建议为搜索服务与其他资源之间的连接设置角色分配。
在 Azure AI 搜索中,启用角色。
将搜索服务配置为使用托管标识。
在数据源平台和嵌入模型提供程序中,创建允许搜索服务访问数据和模型的角色分配。 准备示例数据,为每个支持的数据源提供角色设置说明。
免费搜索服务支持与 Azure AI 搜索的基于角色的连接,但它不支持在与 Azure 存储或 Azure AI 视觉的出站连接上使用托管标识。 此支持级别意味着必须在免费搜索服务与其他 Azure 服务之间的连接中使用基于密钥的身份验证。
如需更安全的连接:
- 请使用基本层或更高层级。
- 配置托管标识并使用角色进行授权访问。
注意
如果因为选项不可用(例如,不能选择数据源或嵌入模型)而无法继续完成向导操作,请重新访问角色分配。 错误消息指示模型或部署不存在,而事实上,真正的原因是搜索服务无权访问它们。
检查空间
如果从免费服务开始,则限制为 3 个索引、数据源、技能集和索引器。 基本层级的限制为 15。 在开始之前,请确保有空间存储额外的项目。 本快速入门将为每个对象创建一个。
准备示例数据
本部分介绍适用于本快速入门的内容。
使用你的 Azure 帐户登录到 Azure 门户,并转到 Azure 存储帐户。
在左侧面板中,在“数据存储”下选择“容器”。
创建新的容器,然后上传用于本快速入门的运行状况计划 PDF 文档。
在左窗格中的“访问控制”下,将存储 Blob 数据读者角色分配给搜索服务标识。 或者,从“访问密钥”页面获取到存储帐户的连接字符串。
(可选)将容器中的删除与搜索索引中的删除同步。 通过以下后续步骤,可以配置索引器以用于删除检测:
在存储帐户上启用软删除。
如果使用本机软删除,则 Azure 存储无需执行进一步的步骤。
否则,添加自定义元数据索引器可以扫描以确定哪些 Blob 标记为要删除。 为自定义属性指定描述性名称。 例如,可以将属性命名为“IsDeleted”,并将其设置为 false。 对容器中的每个 Blob 执行此操作。 稍后,如果要删除 Blob,请将属性更改为 true。 有关详细信息,请参阅从 Azure 存储编制索引时更改和删除检测
设置嵌入模型
该向导可以使用从 Azure OpenAI、Azure AI 视觉或从 Azure AI Foundry 门户的模型目录部署的嵌入模型。
该向导支持 text-embedding-ada-002、text-embedding-3-large、text-embedding-3-small。 在内部,该向导调用 AzureOpenAIEmbedding 技能以连接到 Azure OpenAI。
使用 Azure 帐户登录到 Azure 门户,并转到 Azure OpenAI 资源。
设置权限:
在左侧菜单中,选择“访问控制”。
依次选择“添加”、“添加角色分配”。
在“工作职能角色”下,选择认知服务 OpenAI 用户,然后选择“下一步”。
在“成员”下,选择“托管标识”,然后选择“成员”。
按订阅和资源类型(搜索服务)进行筛选,然后选择搜索服务的托管标识。
选择“查看 + 分配”。
在“概述”页面上,选择“单击此处查看终结点”,如果需要复制终结点或 API 密钥,则选择“单击此处管理密钥”。 如果正在通过基于密钥身份验证使用 Azure OpenAI 资源,则可以将这些值粘贴到向导中。
在“资源管理”和“模型部署”下,选择“管理部署”打开 Azure AI Foundry。
复制
text-embedding-ada-002或其他受支持的嵌入模型的部署名称。 如果没有嵌入模型,请立即部署一个。
启动向导
使用 Azure 帐户登录到 Azure 门户,然后转到 Azure AI 搜索服务。
在“概述”页上,选择“导入和矢量化数据”。

连接到数据库
下一步是连接到要用于搜索索引的数据源。
在“连接到数据”上,选择“Azure Blob 存储”。
指定 Azure 订阅。
选择提供数据的存储帐户和容器。
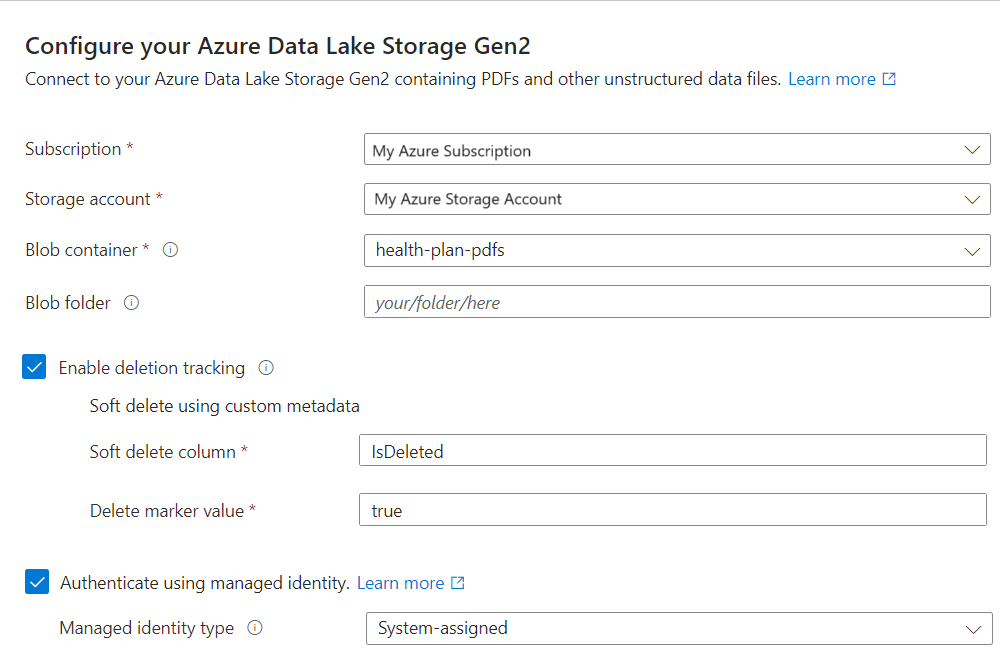
指定你是否需要删除检测支持。 在后续索引运行时,搜索索引会进行更新,以基于 Azure 存储中被软删除的 blob 移除任何搜索文档。
- Blob 支持使用本机 blob 软删除或使用自定义数据软删除。
- 以前必须在 Azure 存储上启用软删除,还可以选择添加自定义元数据以使索引可以识别为删除标志。 有关这些步骤的详细信息,请参阅准备示例数据。
- 如果使用自定义数据为 blob 配置了软删除,请在此步骤中提供元数据属性名称/值对。 建议使用“IsDeleted”。 如果 Blob 上的“IsDeleted”设置为 true,索引器将删除下一个索引器运行的相应搜索文档。
该向导不会检查 Azure 存储中的有效设置,如果未满足要求,则会引发错误。 相反,删除检测不起作用,随着时间的推移,搜索索引可能会收集孤立文档。
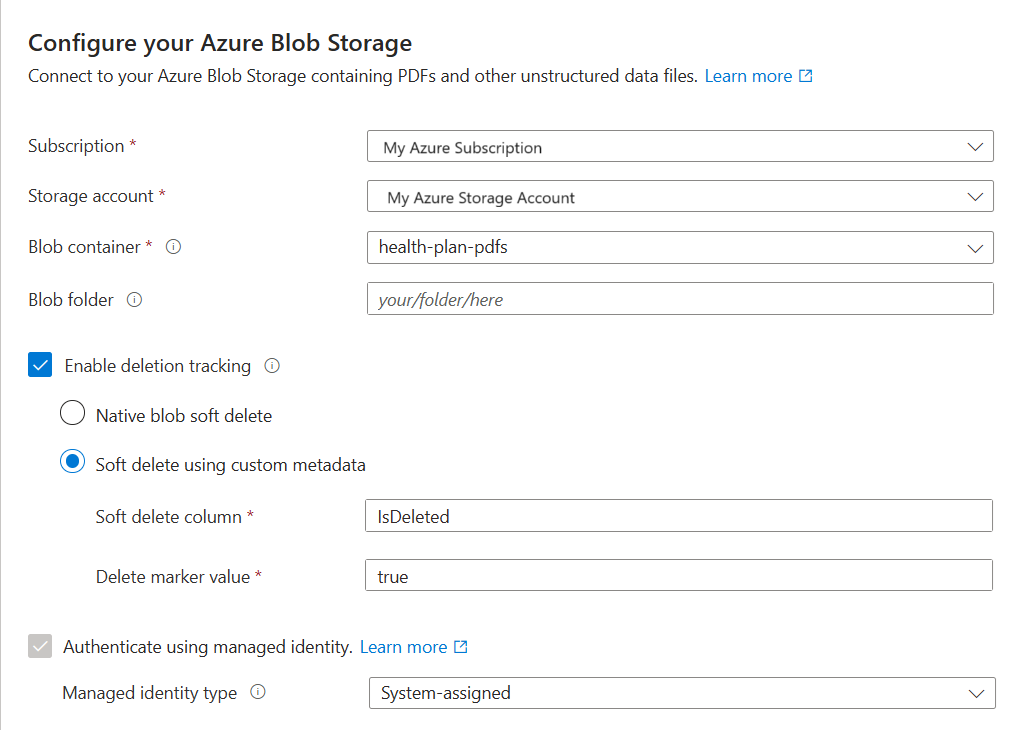
指定你是否希望搜索服务使用其托管标识连接到 Azure 存储。
- 系统会提示你选择系统托管的标识或用户管理的标识。
- 该标识应在 Azure 存储中具有存储 Blob 数据读者角色。
- 请勿跳过此步骤。 如果向导无法连接到 Azure 存储,则会发生连接错误。
选择下一步。
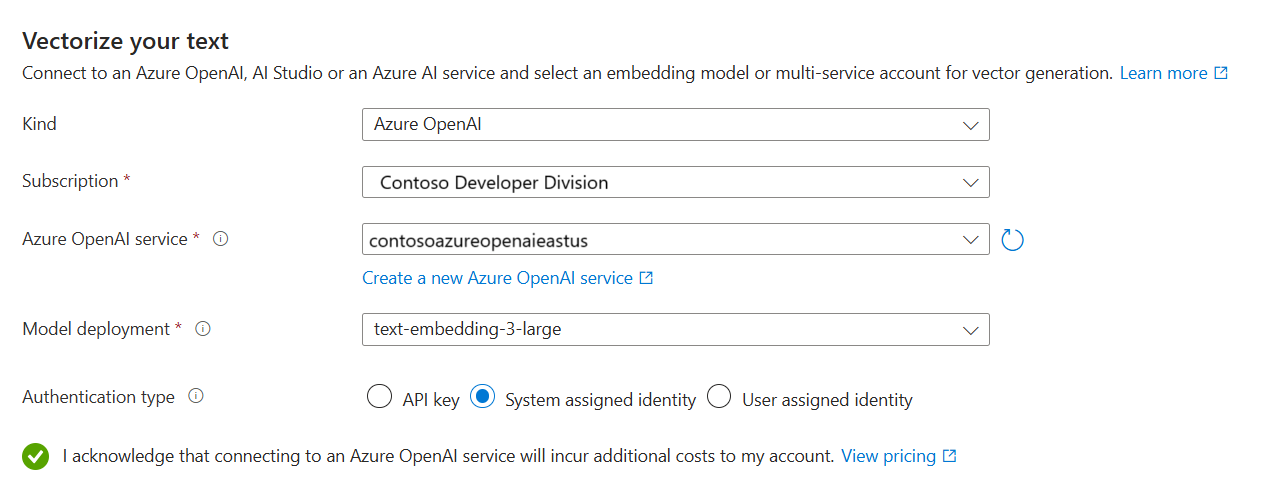
矢量化文本
在此步骤中,指定用于矢量化分块数据的嵌入模型。
分块是内置且不可配置的。 有效设置包括:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
在“矢量化文本”页上,选择嵌入模型的源:
- Azure OpenAI
- Azure AI Foundry 模型目录
- 与 Azure AI 搜索位于同一区域中的现有 Azure AI 视觉多模态资源。 如果同一区域中没有 Azure AI 服务多服务帐户,则此选项不可用。
选择 Azure 订阅。
根据资源进行选择:
对于 Azure OpenAI,请选择 text-embedding-ada-002、text-embedding-3-large 或 text-embedding-3-small 的现有部署。
对于 Azure AI Foundry 目录,请选择 Azure 或 Cohere 嵌入模型的现有部署。
对于 AI 视觉多模态嵌入,请选择该帐户。
指定你是希望搜索服务使用 API 密钥还是托管标识进行身份验证。
- 该标识应在 Azure AI 多服务帐户上具有“认知服务用户”角色。
选中相应复选框以确认使用这些资源的计费影响。
选择下一步。
矢量化并扩充图像
运行状况计划 PDF 包含公司徽标,但除此以外便再无图像。 如果使用示例文档,则可以跳过此步骤。
但是,如果你使用包含实用图像的内容,可以通过两种方式应用 AI:
使用目录中受支持的图像嵌入模型,或选择 Azure AI 视觉多模式嵌入 API 来矢量化图像。
使用光学字符识别 (OCR) 识别图像中的文本。 此选项会调用 OCR 技能从图像中读取文本。
Azure AI 搜索和 Azure AI 资源必须位于同一区域或配置为无密钥计费连接。
在“矢量化图像”页上,指定向导应建立的连接类型。 对于图像矢量化,向导可以连接到 Azure AI Foundry 门户或 Azure AI 视觉中的嵌入模型。
指定订阅。
对于 Azure AI Foundry 模型目录,请指定项目和部署。 有关详细信息,请参阅本文上文中的“设置嵌入模型”。
或者,可以破解二进制图像(例如扫描的文档文件),并使用 OCR 来识别文本。
选中相应复选框以确认使用这些资源的计费影响。
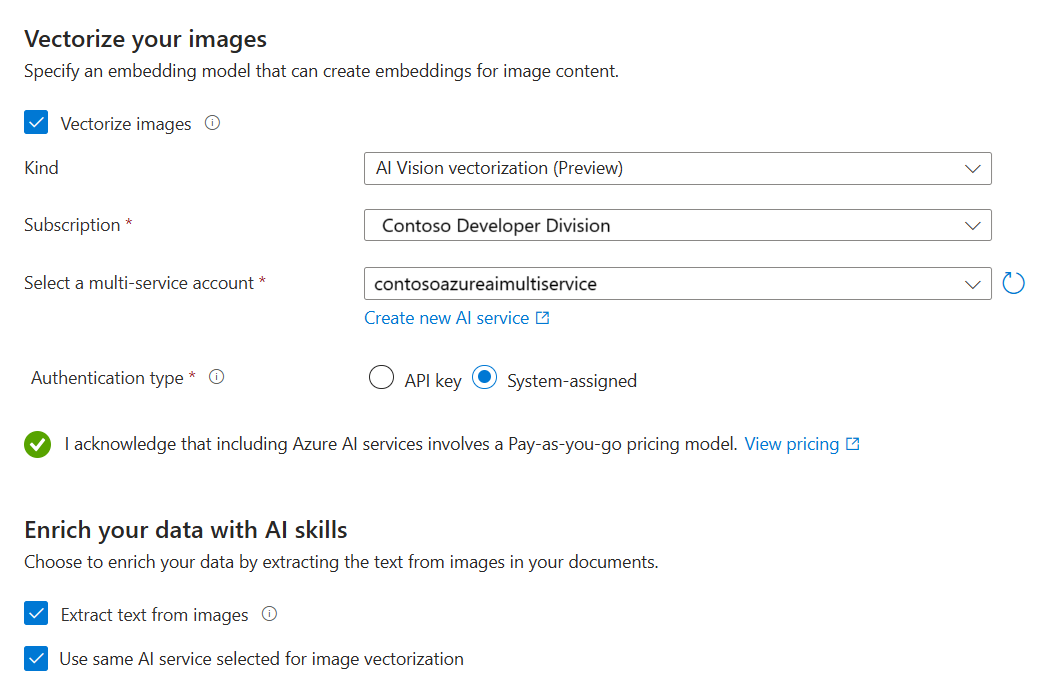
选择下一步。
添加语义排名
在“高级设置”页上,可以选择添加语义排名,以在查询执行结束时将结果重新排名。 重新排名会将在语义方面最相关的匹配项提升到顶部。
映射新字段
该步骤的要点:
- 索引模式为分块数据提供矢量和非矢量字段。
- 可以添加字段,但不能删除或修改生成的字段。
- 文档分析模式会创建区块(每个区块一个搜索文档)。
在“高级设置”页上,你可以选择添加新字段,并假设数据源提供了在第一次扫描时未被识别的元数据或字段。 默认情况下,向导使用这些属性生成以下字段:
| 字段 | 适用于 | 说明 |
|---|---|---|
| chunk_id | 文本和图像矢量 | 生成的字符串字段。 可搜索、可检索、可排序。 这是索引的文档键。 |
| text_parent_id | 文本向量 | 生成的字符串字段。 可检索、可筛选。 标识区块来源的父文档。 |
| chunk | 文本和图像矢量 | 字符串字段。 数据区块的易于阅读版本。 可搜索和可检索,但不可筛选、不可查找、不可排序。 |
| title | 文本和图像矢量 | 字符串字段。 易于阅读的文档标题、页标题或页码。 可搜索和可检索,但不可筛选、不可查找、不可排序。 |
| text_vector | 文本向量 | Collection(Edm.single). 区块的矢量表示。 可搜索和可检索,但不可筛选、不可查找、不可排序。 |
无法修改生成的字段或它们的属性,但如果数据源提供了新字段,则可以添加新字段。 例如,Azure Blob 存储提供元数据字段的集合。
选择“添加新订阅”。
从可用字段列表中选择源字段,提供索引的字段名称,并根据需要使用默认数据类型或重写。
元数据字段可搜索,但不可检索、筛选、查找或排序。
如果要将架构还原到其原始版本,请选择“重置”。
计划索引编制
- 在“高级设置”页面完成操作后,选择“下一步”。
完成该向导
在“查看配置”页面上,为向导创建的对象指定前缀。 通用的前缀有助于保持有序。
选择创建。
当向导完成配置时,它会创建以下对象:
数据源连接。
使用矢量字段、矢量器、矢量配置文件和矢量算法编制索引。 无法在执行向导工作流期间设计或修改默认索引。 索引遵循 2024-05-01-preview REST API。
包含用于分块的文本拆分技能和用于矢量化的嵌入技能的技能组。 嵌入技能是用于 Azure OpenAI 的 AzureOpenAIEmbeddingModel 技能,或者是用于 Azure AI Foundry 模型目录的 AML 技能。 该技能组还采用索引投影配置,允许将数据从数据源中的一个文档映射到“子”索引中的相应块。
具有字段映射和输出字段映射的索引器(如适用)。
检查结果
搜索资源管理器接受文本字符串作为输入,然后矢量化矢量器查询执行文本。
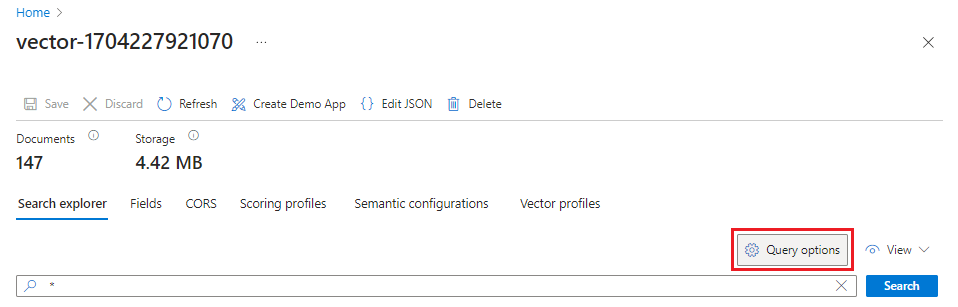
在 Azure 门户中,转到“搜索管理”>“索引”,然后选择你创建的索引。
选择“查询选项”并在搜索结果中隐藏矢量值。 此步骤使你的搜索结果更易于阅读。
在“视图”菜单上,选择“JSON 视图”,以便在
text矢量查询参数中输入用于矢量查询的文本。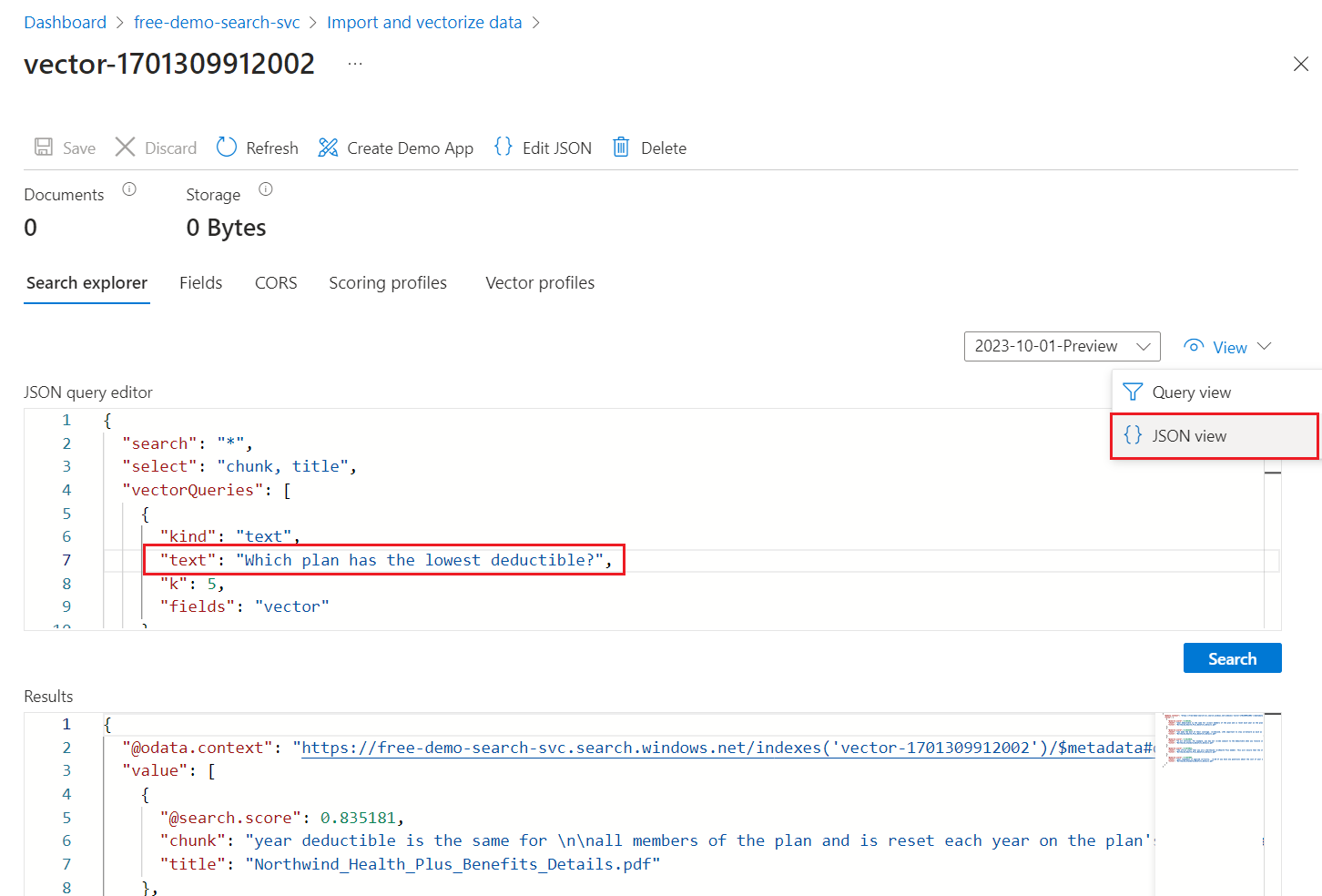
默认查询为空搜索 (
"*"),但包含返回数字匹配项的参数。 这是一种并行运行文本和矢量查询的混合查询。 它包括语义排名。 它会通过select语句指定结果中返回的字段。{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }将这两个星号 (
*) 占位符替换为与运行状况计划相关的问题,例如Which plan has the lowest deductible?。{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }选择“搜索”以运行查询。
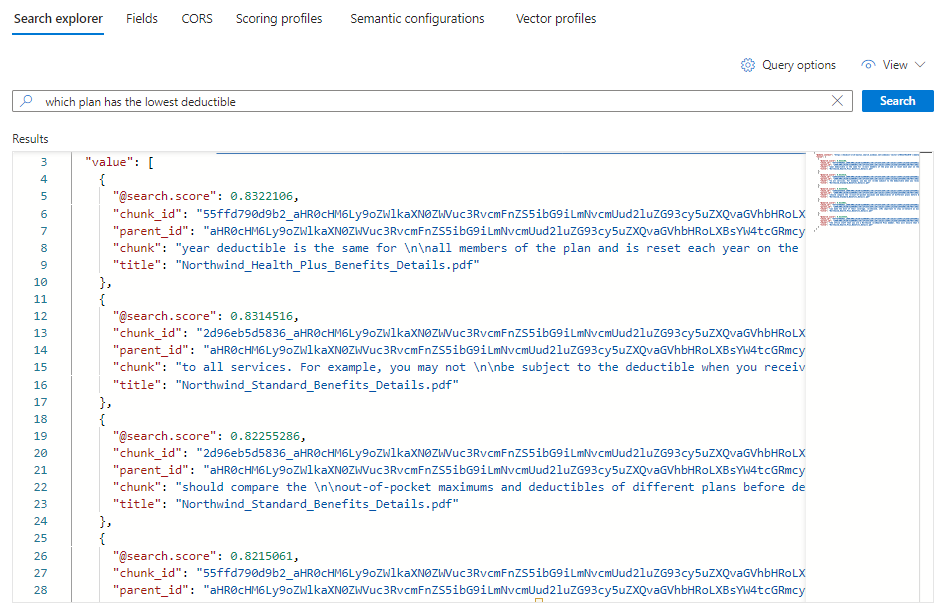
每个文档都是原始 PDF 的一个区块。
title字段显示区块来自哪个 PDF。 每个chunk都相当长。 你可以将其中一个复制并粘贴到文本编辑器中,以读取整个值。若要查看特定文档中的所有区块,请为特定 PDF 的
title_parent_id字段添加筛选器。 你可以检查索引的“字段”选项卡,确认此字段可筛选。{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
清理
Azure AI 搜索是一项计费资源。 如果不再需要它,请将其从订阅中删除以免产生费用。
下一步
本快速入门介绍了“导入和矢量化数据”向导,该向导创建集成矢量化所需的所有对象。 若要详细探索每个步骤,请尝试使用一个集成矢量化示例。