你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是 Azure HDInsight 中的 Apache Hadoop?
Apache Hadoop 是原始的开源框架,适用于对群集上的大数据集进行分布式处理和分析。 Hadoop 生态系统包括相关的软件和实用程序,例如 Apache Hive、Apache HBase、Spark、Kafka 等等。
Azure HDInsight 是云中适用于企业的分析服务,具有完全托管、全面且开源的特点。 借助 Azure HDInsight 中的 Apache Hadoop 群集类型,可使用 Apache Hadoop 分布式文件系统 (HDFS)、Apache Hadoop YARN 资源管理和简单的 MapReduce 编程模型来并行处理和分析批数据。 HDInsight 中的 Hadoop 群集与 Azure Data Lake Storage Gen2 兼容。
若要查看 HDInsight 上的可用 Hadoop 技术堆栈组件,请参阅可以与 HDInsight 配合使用的组件和版本。 若要详细了解 HDInsight 中的 Hadoop,请参阅 HDInsight 的 Azure 功能页。
什么是 MapReduce
Apache Hadoop MapReduce 是一个软件框架,用于编写处理海量数据的作业。 输入的数据将拆分为独立的区块。 每个区块跨群集中的节点并行进行处理。 MapReduce 作业包括两个函数:
映射器:使用输入数据,对数据进行分析(通常使用筛选器和排序操作),并发出元组(键/值对)
化简器:使用映射器发出的元组并执行汇总运算,以基于映射器数据创建更小的合并结果
下图演示了一个基本的单词计数 MapReduce 作业示例:
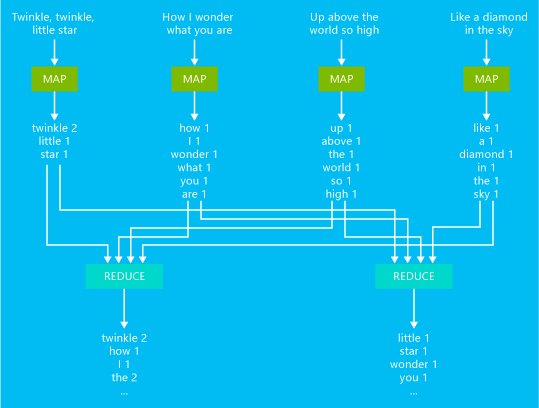
此作业的输出是文本中每个单词出现次数的计数。
- 映射器将输入文本中的每行用作一个输入并将其拆分为多个单词。 每当文本中的单词后跟一个 1 时,映射器将发出一个键/值对。 输出在发送到化简器之前经过排序。
- 随后,化简器会计算每个单词的计数的和并发出一个键/值对(包含单词,后跟该单词的总出现次数)。
MapReduce 可使用多种语言实现。 Java 是最常见的实现,本文档中使用该语言进行演示。
开发语言
基于 Java 和 Java 虚拟机的语言或框架可作为 MapReduce job 作业直接运行。 在本文档中使用的示例是 Java MapReduce 应用程序。 C#、Python 等非 Java 语言或独立可执行文件必须使用 Hadoop 流式处理。
Hadoop 流式处理通过 STDIN 和 STDOUT 与映射器和化简器通信。 映射器和化简器从 STDIN 中一次读取一行数据,并将输出写入 STDOUT。 映射器和化简器读取或发出的每行必须采用制表符分隔的键/值对格式:
[key]\t[value]
有关详细信息,请参阅 Hadoop Streaming(Hadoop 流式处理)。
有关将 Hadoop 流式处理与 HDInsight 配合使用的示例,请参阅以下文档:
从哪里开始
- 快速入门:使用 Azure 门户在 Azure HDInsight 中创建 Apache Hadoop 群集
- 教程:在 HDInsight 中提交 Apache Hadoop 作业
- 为 Apache Hadoop on HDInsight 开发 Java MapReduce 程序
- 将 Apache Hive 用作提取、转换和加载 (ETL) 工具
- 大规模提取、转换和加载 (ETL)
- 使数据分析管道可操作化