你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 HDInsight 中的 Apache Hadoop 上将 C# 与 MapReduce 流式处理配合使用
了解如何在 HDInsight 上使用 C# 创建 MapReduce 解决方案。
Apache Hadoop 流式处理使你能够使用脚本或可执行文件运行 MapReduce 作业。 此处,.NET 用于为单词计数解决方案实现映射器和化简器。
HDInsight 上的 .NET
HDInsight 群集使用 Mono (https://mono-project.com) 运行 .NET 应用程序。 HDInsight 版本 3.6 附带了 Mono 版本 4.2.1。 有关 HDInsight 随附的 Mono 版本的详细信息,请参阅 HDInsight 版本随附的 Apache Hadoop 组件。
有关 Mono 与 .NET Framework 版本的兼容性的详细信息,请参阅 Mono 兼容性。
Hadoop 流式处理的工作原理
在本文档中用于流式处理的基本流程如下所示:
- Hadoop 在 STDIN 上将数据传递到映射器(在本示例中为 mapper.exe)。
- 映射器处理数据,并向 STDOUT 发出制表符分隔的键/值对。
- 该输出由 Hadoop 读取,随后将传递到 STDIN 上的化简器(在本示例中为 reducer.exe)。
- 化简器将读取制表符分隔的键/值对、处理数据,并将结果作为制表符分隔的键/值对在 STDOUT 上发出。
- 该输出由 Hadoop 读取,并写入输出目录。
有关流式处理的详细信息,请参阅 Hadoop 流式处理。
先决条件
Visual Studio。
熟悉编写和生成面向 .NET Framework 4.5 的 C# 代码。
将 .exe 文件上传到群集的方法。 本文档中的各个步骤都使用针对 Visual Studio 的 Data Lake 工具将文件上传到群集的主要存储。
如果使用 PowerShell,需要安装 Az 模块。
HDInsight 中的 Apache Hadoop 群集。 请参阅 Linux 上的 HDInsight 入门。
群集主存储的 URI 方案。 对于 Azure 存储,此架构为
wasb://;对于Azure Data Lake Storage Gen2,此架构为abfs://;对于 Azure Data Lake Storage Gen1,此架构为adl://。 如果为 Azure 存储或 Data Lake Storage Gen2 启用了安全传输,则 URI 分别是wasbs://或abfss://。
创建映射器
在 Visual Studio 中,创建名为 mapper 的新 .NET Framework 控制台应用程序。 针对该应用程序使用以下代码:
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
创建该应用程序后,生成它以在项目目录中生成 /bin/Debug/mapper.exe 文件。
创建化简器
在 Visual Studio 中,创建名为 reducer 的新 .NET Framework 控制台应用程序。 针对该应用程序使用以下代码:
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
创建该应用程序后,生成它以在项目目录中生成 /bin/Debug/reducer.exe 文件。
上传到存储
接下来,需要将 mapper 和 reducer 应用程序上传到 HDInsight 存储。
在 Visual Studio 中,选择“视图”>“服务器资源管理器”。
右键单击“Azure”并选择“连接到 Microsoft Azure 订阅...”,然后完成登录过程。
展开要将此应用程序部署到的 HDInsight 群集。 列出带有文本“(默认存储帐户)” 的条目。
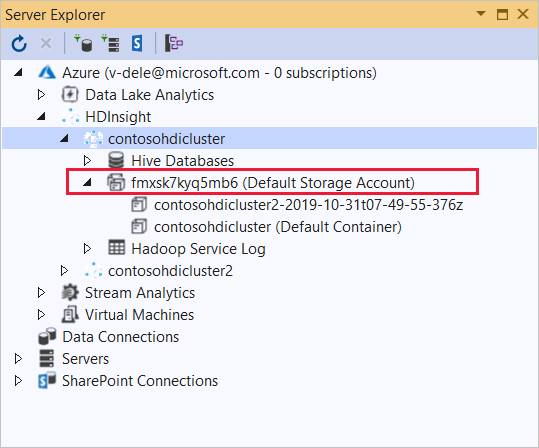
如果可以展开“(默认存储帐户)”项,则表示你正在使用 Azure 存储帐户作为群集的默认存储。 若要查看群集的默认存储中的文件,请展开该项,然后双击“(默认容器)”。
如果无法展开“(默认存储帐户)”项,则表示你正在使用 Azure Data Lake Storage 作为群集的默认存储。 若要查看该群集的默认存储上的文件,请双击“(默认存储帐户)”条目。
若要上传 .exe 文件,请使用以下方法之一:
如果使用的是 Azure 存储帐户,请选择“上传 Blob”图标。

在“上传新文件”对话框中的“文件名”下,选择“浏览”。 在“上传 Blob”对话框中,转到“mapper”项目的“bin\debug”文件夹,然后选择“mapper.exe”文件。 最后,依次选择“打开”、“确定”完成上传。
对于“Azure Data Lake Storage”,请右键单击文件列表中的空白区域,然后选择“上传”。 最后,依次选择“mapper.exe”文件、“打开”。
上传“mapper.exe”完成后,请为“reducer.exe”文件重复该上传过程。
运行作业:使用 SSH 会话
以下过程说明如何使用 SSH 会话运行 MapReduce 作业:
使用 ssh 命令连接到群集。 编辑以下命令(将 CLUSTERNAME 替换为群集的名称),然后输入该命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net使用以下命令之一启动 MapReduce 作业:
如果默认存储为 Azure 存储:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout如果默认存储为 Data Lake Storage Gen1:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout如果默认存储为 Data Lake Storage Gen2:
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
以下列表描述了每个参数和选项的含义:
参数 说明 hadoop-streaming.jar 指定包含流式处理 MapReduce 功能的 jar 文件。 -files 为此作业指定 mapper.exe 和 reducer.exe 文件。 每个文件前的 wasbs:///、adl:///或abfs:///协议声明是群集默认存储的根目录的路径。-mapper 指定实现映射器的文件。 -reducer 指定实现化简器的文件。 -input 指定输入数据。 -output 指定输出目录。 完成 MapReduce 作业后,使用以下命令查看结果:
hdfs dfs -text /example/wordcountout/part-00000以下文本是此命令返回的数据的示例:
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
运行作业:使用 PowerShell
使用以下 PowerShell 脚本运行 MapReduce 作业,并下载结果。
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
此脚本会提示用户提供群集登录的帐户名和密码,以及 HDInsight 群集名称。 作业完成后,输出会下载到名为 output.txt 的文件中。 以下文本是 output.txt 文件中数据的示例:
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17