你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使数据分析管道可操作化
数据管道构成多个数据分析解决方案的基础 。 顾名思义,数据管道使用原始数据,对其进行清除并按需重塑,然后通常在存储处理的数据之前执行计算或聚合。 处理的数据供客户端、报表或 API 使用。 数据管道必须提供可重复的结果,无论是按计划还是由新数据触发。
本文介绍如何使用 HDInsight Hadoop 群集上运行的 Oozie 让数据管道可操作化,以实现可重复性。 示例方案演示的数据管道用于准备和处理航班时间序列数据。
以下方案中,输入数据是一个平面文件,包含一个月的一批航班数据。 此航班数据包括出发机场和目标机场、飞行英里数、起飞和到达时间等信息。 此管道的目标是汇总每日航线绩效,其中每个航线每天有一行记录,含平均起飞和到达延迟时间(分钟数)和该日的总飞行英里数。
| 年 | 月 | DAY_OF_MONTH | 承运商 | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
示例管道等待一个新时间段的航班数据到达,然后将详细航班信息存储到 Apache Hive 数据仓库,用于长期分析。 管道还创建一个较小的数据集,用于汇总每日航班数据。 此每日航班汇总数据发送到 SQL 数据库,为网站等提供报表。
下图展示了此示例管道。
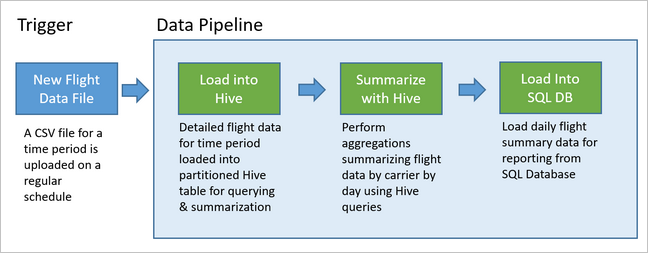
Apache Oozie 解决方案概述
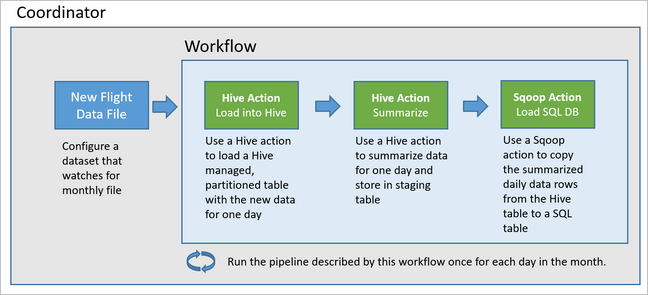
此管道使用 HDInsight Hadoop 群集上运行的 Apache Oozie。
Oozie 根据操作、工作流和协调器对管道进行描述 。 操作决定要执行的实际工作,例如运行 Hive 查询。 工作流定义操作序列。 协调器定义工作流运行的时间计划。 协调器还可依照新数据的可用性情况来启动工作流的实例。
下图展示此示例 Oozie 管道的高级设计。
预配 Azure 资源
此管道要求 Azure SQL 数据库和 HDInsight Hadoop 群集位于同一位置。 Azure SQL 数据库同时存储管道和 Oozie 元数据存储生成的汇总数据。
预配置 Azure SQL 数据库
创建 Azure SQL 数据库。 请参阅在 Azure 门户中创建 Azure SQL 数据库。
若要确保 HDInsight 群集能够访问连接的 Azure SQL 数据库,请配置 Azure SQL 数据库防火墙规则,允许 Azure 服务和资源访问服务器。 可以在 Azure 门户中启用此选项,方法是选择“设置服务器防火墙”,然后在“允许 Azure 服务和资源访问此服务器”下选择“启用”(针对 Azure SQL 数据库)。 有关详细信息,请参阅创建和管理 IP 防火墙规则。
使用查询编辑器执行以下 SQL 语句,以创建
dailyflights表用于存储每次管道运行后的汇总数据。CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Azure SQL 数据库现已准备就绪。
预配 Apache Hadoop 群集
创建使用自定义元存储的 Apache Hadoop 群集。 通过门户创建群集期间,请确保在“存储”选项卡中的“元存储设置”下选择你的 SQL 数据库。 有关选择元存储的详细信息,请参阅在群集创建期间选择自定义元存储。 有关群集创建的详细信息,请参阅 Linux 上的 HDInsight 入门。
验证 SSH 隧道设置
若要使用 Oozie Web 控制台查看协调器和工作流实例的状态,请将 SSH 隧道设为 HDInsight 群集。 有关详细信息,请参阅 SSH 隧道。
注意
还可以结合使用 Chrome 和 Foxy Proxy 扩展,跨 SSH 隧道浏览群集的 Web 资源。 将其配置为通过隧道端口 9876 上的主机 localhost 代理所有请求。 此方法与适用于 Linux 的 Windows 子系统(也称为 Windows 10 上的 Bash)兼容。
运行以下命令(其中
CLUSTERNAME是群集的名称)与群集建立 SSH 隧道:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.net通过导航到头节点上的 Ambari 验证隧道可操作,方法是浏览到:
http://headnodehost:8080若要从 Ambari 内部访问“Oozie Web 控制台”,请导航到“Oozie”>“快速链接”>“[活动服务器]”>“Oozie Web UI”。
配置 Hive
上传数据
下载包含一个月航班数据的示例 CSV 文件。 从 HDInsight GitHub 存储库下载其 ZIP 文件
2017-01-FlightData.zip,并将其解压到 CSV 文件2017-01-FlightData.csv。将此 CSV 文件复制到附加到 HDInsight 群集的 Azure 存储帐户,并将其置于
/example/data/flights文件夹中。使用 SCP 将文件从本地计算机复制到 HDInsight 群集头节点的本地存储。
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csv使用 ssh 命令连接到群集。 编辑以下命令,将
CLUSTERNAME替换为群集的名称,然后输入该命令:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net在 SSH 会话中,使用 HDFS 命令将文件从头节点本地存储复制到 Azure 存储。
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
创建表
示例数据现在可用。 但是,管道需要两个用于处理的 Hive 表,一个用于传入数据 (rawFlights),一个用于汇总数据 (flights)。 在 Ambari 中创建这些表,如下所示。
通过导航到
http://headnodehost:8080登录 Ambari。从服务列表选择“Hive” 。
选择 Hive 视图 2.0 标签旁的“转到视图” 。
在查询文本区域中,粘贴以下语句以创建
rawFlights表。rawFlights表在 Azure 存储的/example/data/flights文件夹内为 CSV 文件提供读取时架构。CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'选择“执行”以创建表 。
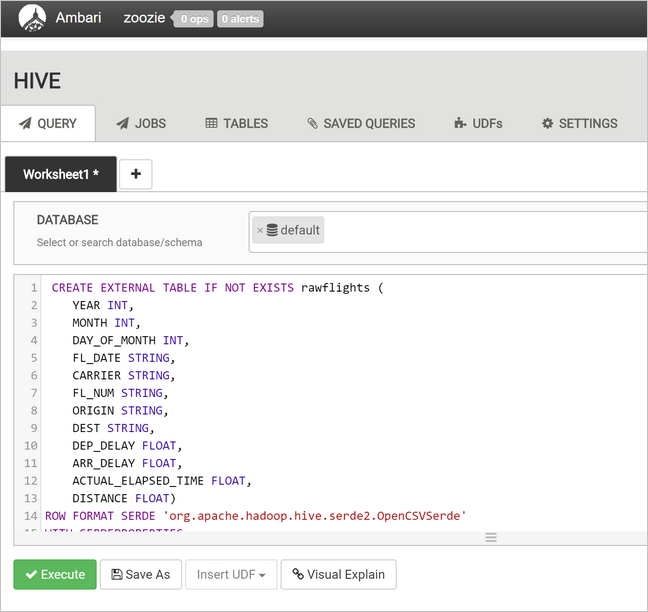
若要创建
flights表,请使用以下语句替换查询文本区域中的文本。flights表是 Hive 托管的表格,将加载到其中的数据按年、月和月份日期进行分区。 此表将包含全部历史航班数据,其中原始数据的呈现采用最小粒度,达到每个航班一行数据。SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );选择“执行”以创建表 。
创建 Oozie 工作流
管道通常按给定时间间隔对数据进行批处理。 在这种情况下,管道每天处理航班数据。 通过此方法,输入 CSV 文件可按每日、每周、每月或每年的间隔到达。
示例工作流每天通过三个主要步骤处理航班数据:
- 运行 Hive 查询,从
rawFlights表表示的源 CSV 文件中提取当日日期范围内的数据,并将数据插入flights表。 - 运行 Hive 查询在 Hive 中动态创建该日的临时表,其中包含按天和承运商汇总的航班数据的副本。
- 使用 Apache Sqoop 将所有数据从 Hive 中的每日临时表复制到 Azure SQL 数据库中的目标
dailyflights表。 Sqoop 读取驻留在 Azure 存储中的 Hive 表中数据的源行,并使用 JDBC 连接将它们加载到 SQL 数据库中。
这三个步骤由 Oozie 工作流进行协调。
在本地工作站中,创建名为
job.properties的文件。 使用以下文本作为该文件的起始内容。 然后更新特定环境的值。 文本下面的表格汇总了每个属性并指示查找用于自己环境的值的位置。nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03properties 值源 nameNode 附加到 HDInsight 群集的 Azure 存储容器的完整路径。 jobTracker 活动群集的 YARN 头节点的内部主机名。 在 Ambari 主页上,从服务列表中选择 YARN,然后选择“活动资源管理器”。 主机名 URI 显示在页面顶部。 追加端口 8050。 queueName 计划 Hive 操作时使用的 YARN 队列的名称。 保留为默认值。 oozie.use.system.libpath 保留为 true。 appBase Azure 存储中用于部署 Oozie 工作流和支持文件的子文件夹的路径。 oozie.wf.application.path 要运行的 Oozie 工作流 workflow.xml的位置。hiveScriptLoadPartition Azure 存储中 Hive 查询文件 hive-load-flights-partition.hql的路径。hiveScriptCreateDailyTable Azure 存储中 Hive 查询文件 hive-create-daily-summary-table.hql的路径。hiveDailyTableName 动态生成的、用于临时表的名称。 hiveDataFolder Azure 存储中指向临时表包含的数据的路径。 sqlDatabaseConnectionString 指向 Azure SQL 数据库的 JDBC 语法连接字符串。 sqlDatabaseTableName Azure SQL 数据库中插入了汇总行的表的名称。 保留为 dailyflights。year 用于计算航班汇总的日期的年份部分。 原样保留。 月份 用于计算航班汇总的日期的月份部分。 原样保留。 day 用于计算航班汇总的日期的月份部分的日期。 原样保留。 在本地工作站中,创建名为
hive-load-flights-partition.hql的文件。 使用以下代码作为该文件的内容。SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Oozie 变量使用语法
${variableName}。 这些变量在job.properties文件中进行设置。 Oozie 在运行时替换实际值。在本地工作站中,创建名为
hive-create-daily-summary-table.hql的文件。 使用以下代码作为该文件的内容。DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};此查询创建一个仅将汇总数据存储一天的临时表,请注意 SELECT 语句,该语句按承运商计算每日平均延迟和总飞行距离。 插入到此表的数据存储在已知位置(路径由 hiveDataFolder 变量指示),以便用作下一步骤中 Sqoop 的源。
在本地工作站中,创建名为
workflow.xml的文件。 使用以下代码作为该文件的内容。 上述步骤在 Oozie 工作流文件中以单独的操作表示。<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
这两个 Hive 查询通过其在 Azure 存储中的路径进行访问,其余变量值由 job.properties 文件提供。 此文件将工作流配置为在 2017 年 1 月 3 日运行。
部署和运行 Oozie 工作流
从 bash 会话使用 SCP 部署 Oozie 工作流 (workflow.xml)、Hive 查询(hive-load-flights-partition.hql 和 hive-create-daily-summary-table.hql)和作业配置 (job.properties)。 在 Oozie 中,仅 job.properties 文件可位于头节点的本地存储上。 所有其他文件必须存储在 HDFS 中,在此例中为 Azure 存储。 工作流使用的 Sqoop 操作取决于用于与 SQL 数据库进行通信的 JDBC 驱动程序,必须从头节点将其复制到 HDFS。
在头节点本地存储的用户路径下创建
load_flights_by_day子文件夹。 在建立的 SSH 会话中执行以下命令:mkdir load_flights_by_day将当前目录中的所有文件(
workflow.xml和job.properties文件)复制到load_flights_by_day子文件夹。 在本地工作站中执行以下命令:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_day将工作流文件复制到 HDFS。 在建立的 SSH 会话中执行以下命令:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_day将
mssql-jdbc-7.0.0.jre8.jar从本地头节点复制到 HDFS 中的工作流文件夹。 如果群集包含不同的 jar 文件,请根据需要修改命令。 根据需要修改workflow.xml以反映不同的 jar 文件。 在建立的 SSH 会话中执行以下命令:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_day运行工作流。 在建立的 SSH 会话中执行以下命令:
oozie job -config job.properties -run使用 Oozie Web 控制台观察状态。 从 Ambari 内部,依次选择“Oozie”、“快速链接”和“Oozie Web 控制台” 。 在“工作流作业”选项卡下,选择“所有作业” 。
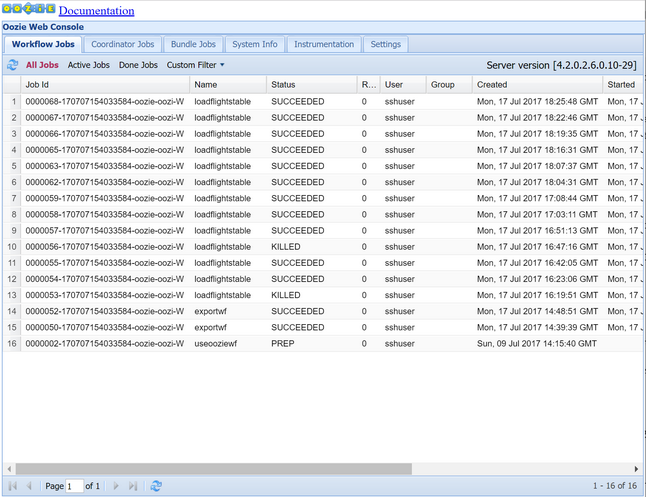
当状态为 SUCCEEDED 时,查询 SQL 数据库表以查看插入的行。 使用 Azure 端口,导航到 SQL 数据库的窗格,选择“工具”,然后打开“查询编辑器” 。
SELECT * FROM dailyflights
现在,工作流要针对单个测试日运行,可使用协调器包装此工作流,将工作流计划为每日运行。
使用协调器运行工作流
若要将此工作流计划为每日运行(或者是一段日期范围内的所有日期),可以使用协调器。 协调器由 XML 文件定义,例如 coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
可以看到,大部分协调器仅将配置信息传递到工作流实例。 但是,有几点需要强调。
第 1 点:
coordinator-app元素上的start和end属性控制协调器运行的时间间隔。<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>协调器负责按照
frequency属性指定的间隔,在start和end日期范围内计划操作。 每个计划的操作反过来按配置运行工作流。 在上面的协调器定义中,协调器被配置为从 2017 年 1 月 1 日到 2017 年 1 月 5 日运行操作。 频率通过 Oozie 表达式语言频率表达式${coord:days(1)}设置为 1 天。 通过此操作,协调器会按每天一次的频率计划一个操作(以及工作流)。 对于过去的日期范围,如本示例所示,操作将计划为无延迟运行。 操作运行计划的开始日期称为“名义时间” 。 例如,若要处理 2017 年 1 月 1 日的数据,协调器会将操作的名义时间计划为 2017-01-01T00:00:00 GMT。第 2 点:在工作流的日期范围内,
dataset元素指定 HDFS 中查找特定日期范围的数据的位置,并配置 Oozie 如何确定数据是否可进行处理。<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>HDFS 中数据的路径根据
uri-template元素中提供的表达式动态生成。 在此协调器中,一天的频率也用于数据集。 协调器元素上的开始和结束日期控制操作的计划时间(并定义它们的名义时间),而数据集上的initial-instance和frequency控制构建uri-template时使用的日期的计算。 在此例中,将初始实例设为协调器启动前一天以确保它选取第一天(2017 年 1 月 1 日)的数据。 数据集的日期计算从initial-instance(12/31/2016) 的值向后滚动,按数据集频率(1 天)递增,直到找到未超过协调器(第一次操作的 2017-01-01T00:00:00 GMT)设置的名义时间的最近日期。空
done-flag元素指示当 Oozie 在指定时间检查输入数据是否存在时,Oozie 通过目录或文件的存在情况确定数据是否可用。 在此例中指 csv 文件的存在情况。 如果存在 csv 文件,则 Oozie 假设数据已准备就绪并启动工作流实例以处理文件。 如果不存在 csv 文件,Oozie 假定数据尚未就绪,并且工作流的运行将进入等待状态。第 3 点:
data-in元素指定在uri-template中替换关联数据集的值时,要用作名义时间的特定时间戳。<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>在此例中,将实例设为表达式
${coord:current(0)},这会转换为协调器最初计划的操作的名义时间。 换言之,当协调器将操作运行的名义时间计划为 01/01/2017 时,则用 01/01/2017 来替换 URI 模板中的年份 (2017) 和月份 (01) 变量。 为此实例计算了 URI 模板后,Oozie 会立即检查预期目录或文件是否可用并相应计划工作流的下一次运行。
结合上述三点的结果是:协调器按照逐日的方式计划源数据的处理。
第 1 点:协调器从名义时间 2017-01-01 开始。
第 2 点:Oozie 在
sourceDataFolder/2017-01-FlightData.csv中查找可用数据。第 3 点:Oozie 找到该文件后,会计划一个工作流实例,该实例会处理 2017 年 1 月 1 日的数据。 Oozie 接着继续处理 2017-01-02 的数据。 此计算反复执行至 2017-01-05(不含)。
与工作流一样,协调器的配置也在 job.properties 文件中定义,其中具有工作流使用的设置的超集。
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
在此 job.properties 文件中引入的新属性为:
| properties | 值源 |
|---|---|
| oozie.coord.application.path | 指示 coordinator.xml 文件的位置,其中包含要运行的 Oozie 协调器。 |
| hiveDailyTableNamePrefix | 动态创建临时表表名时使用的前缀。 |
| hiveDataFolderPrefix | 用于存储所有临时表的路径的前缀。 |
部署和运行 Oozie 协调器
若要使用协调器运行管道,请使用与工作流相似的方式执行操作,有一点除外,就是所使用的文件夹的级别比包含工作流的文件夹高一级。 此文件夹约定将协调器与磁盘上的工作流相分离,所以可将一个协调器与不同的子工作流关联起来。
从本地计算机使用 SCP 将协调器文件复制到群集头节点的本地存储。
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH 到头节点内。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net将协调器文件复制到 HDFS。
hdfs dfs -put ./* /oozie/运行协调器。
oozie job -config job.properties -run使用 Oozie Web 控制台验证状态,这一次选择“协调器作业”选项卡,然后选择“全部作业”。
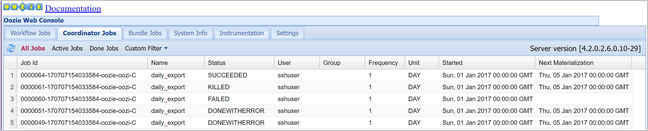
选择一个协调器实例显示计划操作的列表。 在此例中,应该会显示四个名义时间在 2017 年 1 月 1 日至 2017 年 1 月 4 日范围内的操作。
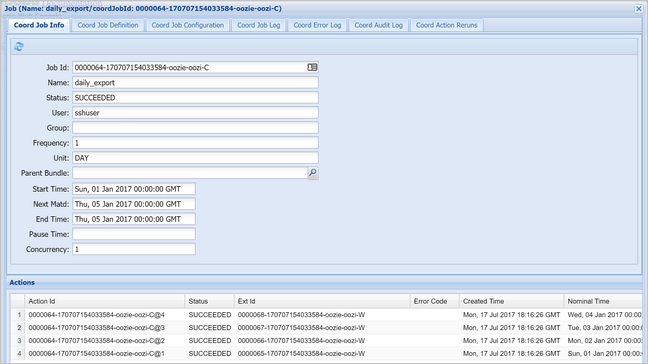
此列表中的每个操作对应于工作流的一个实例,用于处理一天的数据量,其中该天的开始时间由名义时间指示。