在 Databricks 笔记本中开发代码
本页介绍如何在 Databricks 笔记本中开发代码,包括自动完成、Python 和 SQL 的自动格式设置、在笔记本中组合使用 Python 和 SQL,以及跟踪笔记本版本历史记录。
有关编辑器提供的高级功能(例如自动完成、变量选择、多光标支持和并列比较)的更多详细信息,请参阅浏览 Databricks 笔记本和文件编辑器。
使用笔记本或文件编辑器时,Databricks 助手可用于帮助生成、解释和调试代码。 有关详细信息,请参阅使用 Databricks 助手。
Databricks 笔记本还包括适用于 Python 笔记本的内置交互式调试程序。 请参阅调试笔记本。
将代码模块化
重要
此功能目前以公共预览版提供。
使用 Databricks Runtime 11.3 LTS 及更高版本,可以在 Azure Databricks 工作区中创建和管理源代码文件,然后根据需要将这些文件导入到笔记本中。
有关使用源代码文件的详细信息,请参阅在 Databricks 笔记本之间共享代码和使用 Python 和 R 模块。
设置代码单元格的格式
Azure Databricks 提供的工具可用于在笔记本单元格中快速且轻松地设置 Python 和 SQL 代码的格式。 这些工具减少了使代码带有格式的工作量,有助于在笔记本中强制实施相同的编码标准。
Python black 格式化程序库
重要
此功能目前以公共预览版提供。
Azure Databricks 支持在笔记本中使用 black 的 Python 代码格式设置。 笔记本必须附加到安装了 black 和 tokenize-rt Python 包的群集。
在 Databricks Runtime 11.3 LTS 及更高版本上,Azure Databricks 将预安装 black 和 tokenize-rt。 可以直接使用格式化程序,而无需安装这些库。
在 Databricks Runtime 10.4 LTS 及更低版本上,必须在笔记本或群集上通过 PyPI 安装 black==22.3.0 和 tokenize-rt==4.2.1 才能使用 Python 格式化程序。 可以在笔记本中运行以下命令:
%pip install black==22.3.0 tokenize-rt==4.2.1
或在群集上安装库。
有关安装库的更多详细信息,请参阅 Python 环境管理。
对于 Databricks Git 文件夹中的文件和笔记本,可根据 pyproject.toml 文件配置 Python 格式化程序。 若要使用此功能,请在 Git 文件夹根目录中创建一个 pyproject.toml 文件,并根据 Black 配置格式对其进行配置。 编辑文件中的 [tool.black] 部分。 当格式化该 Git 文件夹中的任何文件和笔记本时,将应用该配置。
如何设置 Python 和 SQL 单元格的格式
必须拥有笔记本“可编辑”权限,才能设置代码的格式。
Azure Databricks 使用 Gethue/sql-formatter 库来设置 SQL 格式,并使用适用于 Python 的 black 代码格式化程序。
可通过以下方式触发格式化程序:
设置单个单元格的格式
设置多个单元格的格式
选择多个单元格,然后选择“编辑”>“设置单元格格式”。 如果选择多个语言的单元格,则仅会设置 SQL 和 Python 单元格的格式。 这包括那些使用
%sql和%python的单元格。设置笔记本中所有 Python 和 SQL 单元格的格式
选择“编辑”>“设置笔记本格式”。 如果笔记本包含多种语言,则只会设置 SQL 和 Python 单元格的格式。 这包括那些使用
%sql和%python的单元格。
代码格式设置的限制
- Black 对 4 空格缩进强制执行 PEP 8 标准。 缩进不可配置。
- 不支持设置 SQL UDF 中嵌入的 Python 字符串的格式。 同样,不支持设置 Python UDF 中 SQL 字符串的格式。
笔记本中的代码语言
设置默认语言
笔记本的默认语言显示在笔记本名称旁边。

要更改默认语言,请单击语言按钮并从下拉菜单中选择新语言。 为确保现有命令可继续正常工作,以前的默认语言的命令会自动带有语言 magic 命令前缀。
混合语言
默认情况下,单元格使用笔记本的默认语言。 通过单击语言按钮并从下拉菜单中选择一种语言,可以替代单元格中的默认语言。

或者,可以在单元格的开头使用语言 magic 命令 %<language>。 支持的 magic 命令为:%python、%r、%scala 和 %sql。
注意
调用语言 magic 命令时,该命令会被调度到笔记本的执行上下文中的 REPL。 用一种语言定义(并且因此位于该语言的 REPL 中)的变量在其他语言的 REPL 中不可用。 REPL 只能通过外部资源(例如 DBFS 中的文件或对象存储中的对象)共享状态。
笔记本还支持几个辅助 magic 命令:
%sh:允许你在笔记本中运行 shell 代码。 若要在 shell 命令的退出状态为非零值的情况下使单元格发生失败,请添加-e选项。 此命令仅在 Apache Spark 驱动程序上运行,不在工作器上运行。 若要在所有节点上运行 shell 命令,请使用初始化脚本。%fs:允许你使用dbutils文件系统命令。 例如,如需运行dbutils.fs.ls命令以列出文件,可以改为指定%fs ls。 有关详细信息,请参阅使用 Azure Databricks 上的文件。%md:允许你包括各种类型的文档,例如文本、图像以及数学公式和等式。 请参阅下一部分。
Python 命令中的 SQL 语法突出显示和自动完成
当你在 Python 命令(例如 命令)中使用 SQL 时,可以使用语法突出显示和 SQL spark.sql。
浏览 SQL 单元格结果
在 Databricks 笔记本中,SQL 语言单元格的结果会自动作为分配给变量 _sqldf的隐式 DataFrame 提供。 然后,可以在之后运行的任何 Python 和 SQL 单元格中使用此变量,而不考虑它们在笔记本中的位置。
注意
此功能具有以下限制:
- 该
_sqldf变量在使用 SQL 仓库进行计算的笔记本中不可用。 _sqldfDatabricks Runtime 13.3 及更高版本中支持在后续 Python 单元格中使用。_sqldf仅在 Databricks Runtime 14.3 及更高版本上支持在后续 SQL 单元中使用。- 如果查询使用关键字
CACHE TABLE或UNCACHE TABLE_sqldf变量不可用。
以下屏幕截图显示了如何在 _sqldf 后续 Python 和 SQL 单元格中使用:
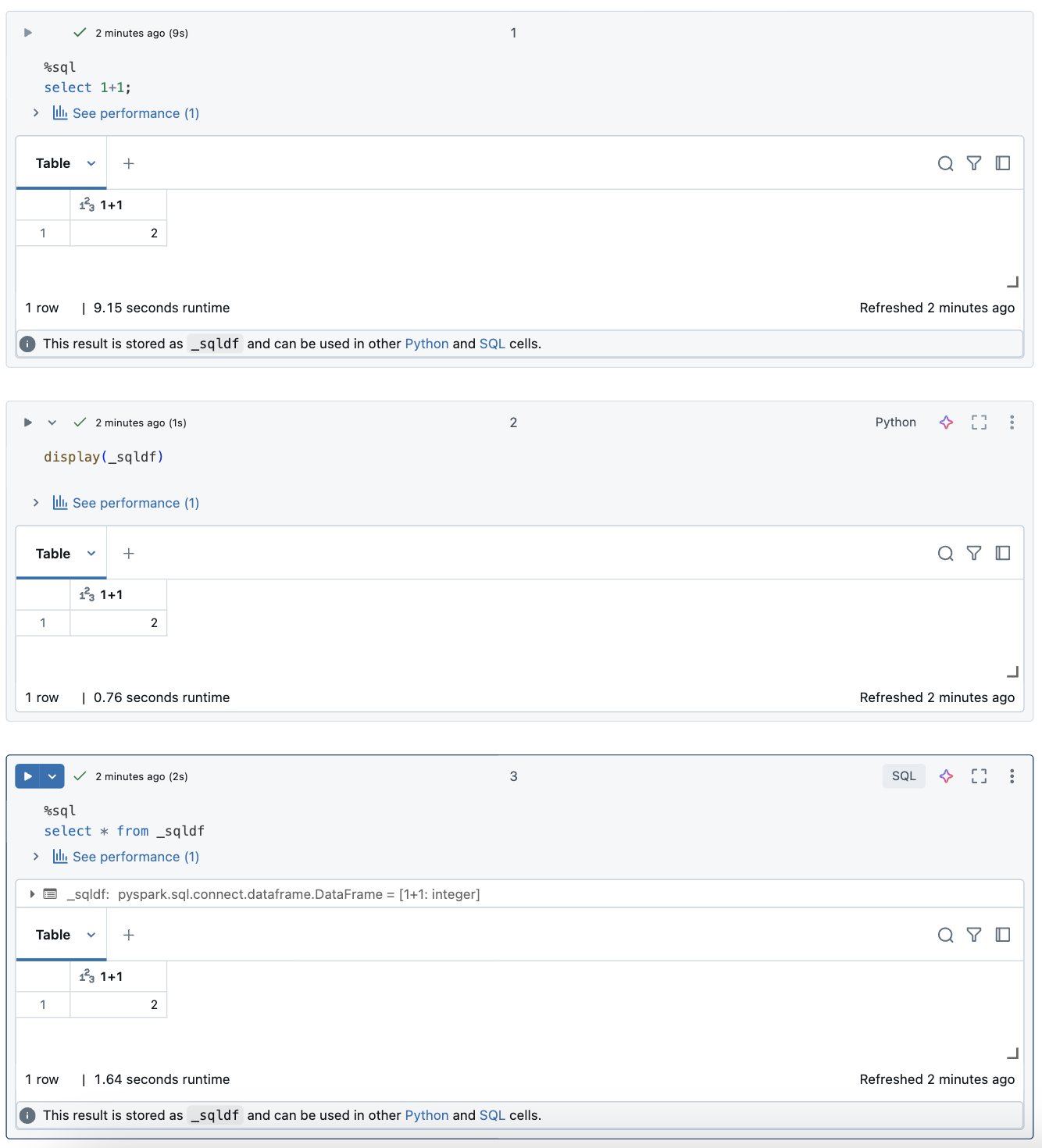
重要
每次运行 SQL 单元格时,都会重新分配变量 _sqldf 。 若要避免丢失对特定 DataFrame 结果的引用,请在运行下一个 SQL 单元格之前将其分配给新的变量名称:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
并行执行 SQL 单元格
当某个命令正在运行且你的笔记本已附加到交互式群集时,可以将 SQL 单元格与当前命令同时运行。 SQL 单元格在新的并行会话中执行。
若要并行执行某个单元格,请执行以下操作:
单击“立即运行”。 此时会立即执行该单元格。
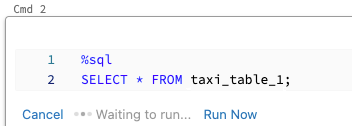
由于单元格在新会话中运行,因此并行执行的单元格不支持临时视图、UDF 和隐式 Python 数据帧 (_sqldf)。 此外,在并行执行期间将使用默认目录和数据库名称。 如果代码引用不同目录或数据库中的表,则你必须使用三级命名空间 (catalog.schema.table) 来指定表名。
在 SQL 仓库上执行 SQL 单元格
可以在 SQL 仓库上的 Databricks 笔记本中运行 SQL 命令,这是一种针对 SQL 分析优化的计算类型。 请参阅将笔记本与 SQL 仓库配合使用。