笔记本计算资源
本文介绍乐笔记本计算资源的选项。 可在 Databricks 群集、无服务器计算上运行笔记本;对于 SQL 命令,可使用 SQL 仓库(一种针对 SQL 分析进行计算优化的类型)。
笔记本的无服务器计算
无服务器计算使你能够快速将笔记本连接到按需计算资源。
若要附加到无服务器计算,请单击笔记本中的“连接”下拉菜单,然后选择“无服务器”。
有关详细信息,请参阅笔记本的无服务器计算。
将笔记本附加到群集
若要将笔记本附加到群集,需要“可附加到群集级别”权限。
重要
只要笔记本附加到群集,对笔记本具有“可运行”权限的任何用户就具有访问群集的隐式权限。
若要将笔记本附加到群集,请单击笔记本工具栏中的计算选择器,然后从下拉菜单中选择一个群集。
该菜单显示最近使用过或当前正在运行的群集选择。
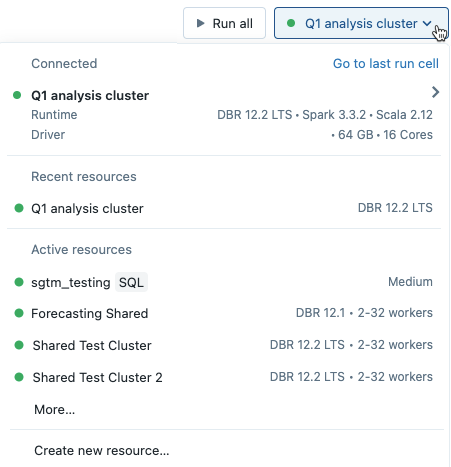
若要从所有可用群集中进行选择,请单击“更多...”。 单击群集名称以显示下拉菜单,然后选择现有群集。
还可以通过从下拉菜单中选择“新建资源...”来创建新群集。
重要
附加的笔记本定义了以下 Apache Spark 变量。
| 类 | 变量名称 |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
请勿创建 SparkSession、SparkContext 或 SQLContext。 这样做会导致行为不一致。
将笔记本与 SQL 仓库配合使用
将笔记本附加到 SQL 仓库时,可以运行 SQL 和 Markdown 单元。 以任何其他语言(如 Python 或 R)运行单元格都会引发错误。 在 SQL 仓库上执行的 SQL 单元格会显示在 SQL 仓库的查询历史记录中。 运行查询的用户可以通过单击输出底部的运行时间从笔记本查看查询配置文件。
运行笔记本需要专业版或无服务器版 SQL 仓库。 你必须有权访问工作区和 SQL 仓库。
若要将笔记本附加到 SQL 仓库,请执行以下操作:
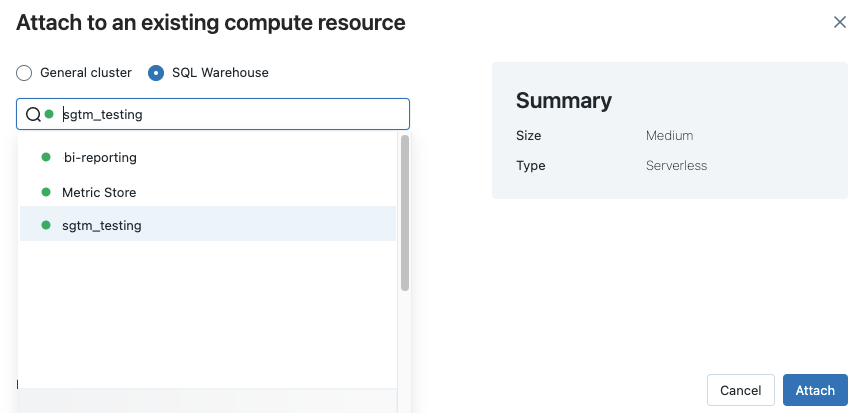
单击笔记本工具栏中的计算选择器。 下拉菜单会显示当前正在运行的或最近使用的计算资源。 SQL 仓库带有
 。
。从菜单中选择一个 SQL 仓库。
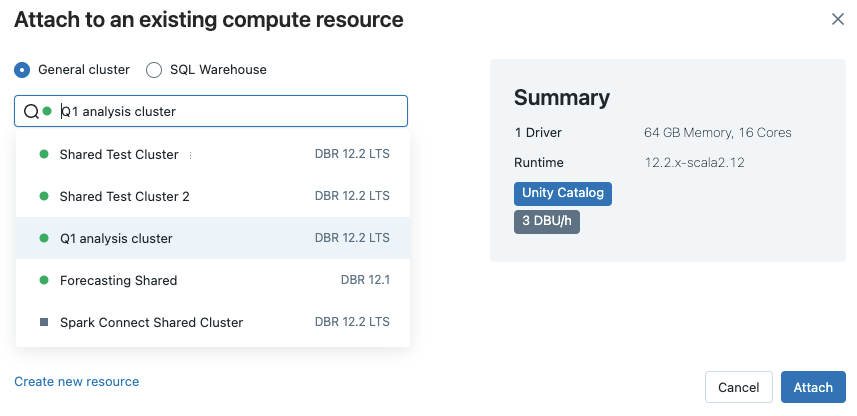
若要查看所有可用的 SQL 仓库,请从下拉菜单中选择“更多...”。 此时会出现一个对话框,其中显示了笔记本可用的计算资源。 选择“SQL 仓库”,选择要使用的仓库,然后单击“附加”。
创建工作流或计划作业时,还可以选择 SQL 仓库作为 SQL 笔记本的计算资源。
SQL 仓库限制
有关详细信息,请参阅 Databricks 笔记本的已知限制。
分离笔记本
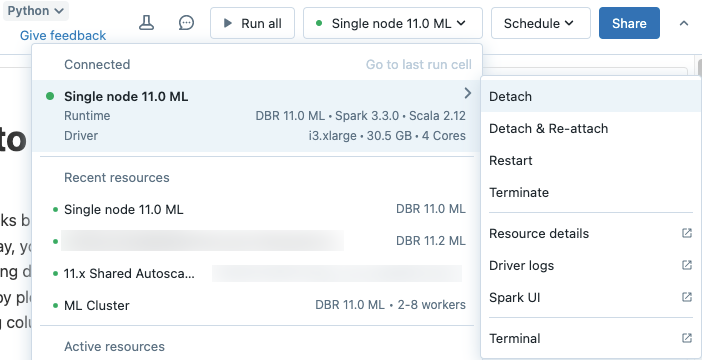
若要将笔记本与计算资源分离,请单击笔记本工具栏中的计算选择器,然后将鼠标悬停在列表中已附加的群集或 SQL 仓库上,以显示边侧菜单。 在侧菜单中,选择“拆离”。
也可使用群集详细信息页上的“笔记本”选项卡将笔记本从群集中拆离。
提示
Azure Databricks 建议从群集中分离未使用的笔记本。 这将释放驱动程序占用的内存空间。