使用工作流的无服务器计算运行 Azure Databricks 作业
工作流的无服务器计算允许在不配置和部署基础结构的情况下运行 Azure Databricks 作业。 借助无服务器计算,可以专注于实现数据处理和分析管道,Azure Databricks 可以有效地管理计算资源,包括优化和缩放工作负载的计算。 自动缩放和 Photon 会自动为运行作业的计算资源启用。
工作流的无服务器计算会自动持续优化基础结构,例如实例类型、内存和处理引擎,以确保根据工作负荷的特定处理要求获得最佳性能。
Databricks 会自动升级 Databricks Runtime 版本,以支持平台的增强和升级,同时确保 Azure Databricks 作业的稳定性。 若要查看无服务器计算用于工作流的当前 Databricks Runtime 版本,请参阅无服务器计算发行说明。
由于不需要群集创建权限,因此所有工作区用户都可以使用无服务器计算来运行其工作流。
本文介绍如何使用 Azure Databricks 作业 UI 创建和运行使用无服务器计算的作业。 还可以通过作业 API、Databricks 资产捆绑包和 Databricks SDK for Python 自动创建和运行使用无服务器计算的作业。
- 若要了解如何使用作业 API 创建和运行使用无服务器计算的作业,请参阅 REST API 参考中的作业。
- 若要了解如何使用 Databricks 资产捆绑包创建和运行使用无服务器计算的作业,请参阅使用 Databricks 资产捆绑包在 Azure Databricks 上开发作业。
- 若要了解如何使用 Databricks SDK for Python 创建和运行使用无服务器计算的作业,请参阅 Databricks SDK for Python。
要求
Azure Databricks 工作区必须启用 Unity Catalog。
由于工作流的无服务器计算使用共享访问模式,因此工作负载必须支持此访问模式。
Databricks 工作区必须位于受支持的区域中。 请参阅区域可用性受限的功能。
Azure Databricks 帐户必须已启用无服务器计算。 请参阅启用无服务器计算。
使用无服务器计算创建作业
注意
由于针对工作流的无服务器计算可确保预配足够的资源来运行工作负载,因此在运行需要大量内存或包含许多任务的 Azure Databricks 作业时,你可能会遇到启动时间增加的问题。
无服务器计算支持笔记本、Python 脚本、dbt 和 Python wheel 任务类型。 默认情况下,创建新作业并添加其中一个受支持的任务类型时,会选择无服务器计算作为计算类型。
Databricks 建议对所有作业任务使用无服务器计算。 还可以为作业中的任务指定不同的计算类型,如果工作流的无服务器计算不支持任务类型,则可能需要这些类型。
若要管理作业的出站网络连接,请参阅什么是无服务器出口控制?
配置现有作业使用无服务器计算
编辑作业时,可以将现有作业切换为对受支持的任务类型使用无服务器计算。 若要切换到无服务器计算,请执行以下任一操作:
- 在“作业详细信息”侧面板中,单击“计算”下的“交换”,单击“新建”,输入或更新任何设置,然后单击“更新”。
- 在
 Down Caret“计算”下拉菜单中单击 ,然后选择“无服务器”。
Down Caret“计算”下拉菜单中单击 ,然后选择“无服务器”。

使用无服务器计算计划笔记本
除了使用作业 UI 创建和计划使用无服务器计算的作业之外,还可以直接从 Databricks 笔记本创建和运行使用无服务器计算的作业。 请参阅创建和管理计划的笔记本作业。
为无服务器使用情况选择预算策略
重要
此功能目前以公共预览版提供。
预算策略允许组织对无服务器使用情况应用自定义标记,以实现精细计费归因。
如果工作区使用预算策略将无服务器使用情况归咎于属性,则可以在作业详细信息 UI 中使用 预算策略设置选择作业的预算策略 。 如果仅分配给一个预算策略,则会自动为新作业选择该策略。
注意
分配预算策略后,现有作业不会自动使用策略进行标记。 如果要将策略附加到现有作业,则必须手动更新这些作业。
有关预算策略的详细信息,请参阅 具有预算策略的属性无服务器使用情况。
设置 Spark 配置参数
若要在无服务器计算中自动配置 Spark,Databricks 仅允许设置特定的 Spark 配置参数。 有关允许的参数的列表,请参阅支持的 Spark 配置参数。
只能在会话级别设置 Spark 配置参数。 为此,请在笔记本中设置它们,并将笔记本添加到使用这些参数的同一作业中包含的某个任务中。 请参阅获取和设置笔记本中的 Apache Spark 配置属性。
配置环境和依赖项
若要了解如何使用无服务器计算安装库和依赖项,请参阅 “安装笔记本依赖项”。
为笔记本任务配置高内存
重要
此功能目前以公共预览版提供。
可以将笔记本任务配置为使用更高的内存大小。 为此,请在笔记本 环境 侧面板中配置 内存 设置。 请参阅 为无服务器工作负荷配置高内存。
高内存仅适用于笔记本任务类型。
配置无服务器计算自动优化以禁止重试
工作流的无服务器计算自动优化功能会自动优化用于运行作业和重试失败任务的计算。 自动优化默认启用,Databricks 建议将其启用,以确保关键工作负载至少成功运行一次。 但是,如果工作负载必须最多执行一次,例如,不是幂等的作业,则可以在添加或编辑任务时关闭自动优化:
- 在“重试”旁边,单击“添加”(或者,如果重试策略已存在,则单击
 )。
)。 - 在“重试策略”对话框中,取消选中“启用无服务器自动优化(可能包括其他重试)”。
- 单击“确认”。
- 如要添加任务,请单击“创建任务”。 如要编辑任务,请单击“保存任务”。
监视将无服务器计算用于工作流的作业成本
可以通过查询可计费使用系统表来监控使用无服务器计算的工作流作业的成本。 此表已更新,包括有关无服务器成本的用户和工作负载属性。 请参阅计费使用情况系统表引用。
有关当前定价和任何促销的信息,请参阅 “工作流定价”页。
查看作业运行的查询详细信息
可以查看 Spark 语句的详细运行时信息,例如指标和查询计划。
若要从作业 UI 访问查询详细信息,请使用以下步骤:
单击边栏中
 “工作流”。
“工作流”。单击要查看的作业的名称。
单击要查看的特定运行。
单击 时间线以时间线 的形式查看运行,拆分为单个任务。
单击任务名称旁边的箭头以显示查询语句及其运行时。
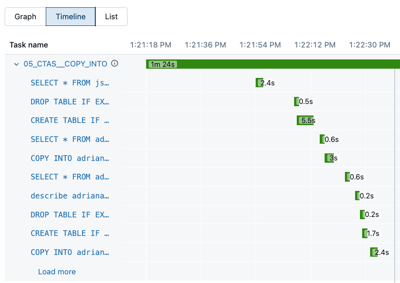
单击某个语句以打开 查询详细信息 面板。 请参阅 “查看查询详细信息 ”,详细了解此面板中提供的信息。
若要查看任务的查询历史记录,请执行以下操作:
- 在“任务运行”侧面板的“计算”部分,单击“查询历史记录”。
- 你将重定向到“查询历史记录”,其中的信息已根据你所处任务的任务运行 ID 进行预筛选。
有关使用查询历史记录的信息,请参阅 Delta Live Tables 管道 和 查询历史记录的访问查询历史记录。
限制
有关工作流限制的无服务器计算列表,请参阅无服务器计算发行说明中的无服务器计算限制。