适用于笔记本的无服务器计算
本文介绍如何使用适用于笔记本的无服务器计算。 有关使用适用于作业的无服务器计算的信息,请参阅使用适用于工作流的无服务器计算运行 Azure Databricks 作业。
有关定价信息,请参阅 Databricks 定价。
要求
- 必须为 Unity Catalog 启用你的工作区。
- 工作区必须位于受支持的区域。 请参阅 Azure Databricks 区域。
- 你的帐户必须启用无服务器计算。 请参阅启用无服务器计算。
将笔记本附加到无服务器计算
如果为工作区启用了无服务器交互式计算,则工作区中的所有用户都可以访问适用于笔记本的无服务器计算。 不需要其他权限。
若要附加到无服务器计算,请单击笔记本中的“连接”下拉菜单,然后选择“无服务器”。 对于新笔记本,如果未选择其他资源,则在执行代码时,附加计算将自动默认设置为无服务器。
为无服务器使用情况选择预算策略
重要
此功能目前以公共预览版提供。
预算策略允许组织对无服务器使用情况应用自定义标记,以实现精细计费归因。
如果工作区使用预算策略将无服务器使用情况属性化,则可以选择要应用于笔记本的预算策略。 如果用户仅分配到一个预算策略,则默认情况下会选择该策略。
使用“环境”端面板将笔记本连接到无服务器计算后,可以选择预算策略:
- 在笔记本 UI 中,单击“ 环境 ”侧面板
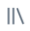 。
。 - 在“预算”策略下,选择要应用于笔记本的预算策略。
- 单击“应用”。
从此开始,笔记本中的所有使用情况都将继承预算策略的自定义标记。
注意
如果笔记本源自 Git 存储库或没有分配 的预算策略,则下次附加到无服务器计算时,它默认为上次选择的预算策略。
为无服务器工作负荷配置高内存
重要
此功能目前以公共预览版提供。
如果需要更多内存来运行无服务器工作负荷,可以将笔记本配置为使用更高的内存大小。 内存较高的无服务器使用的DBU排放率高于标准内存。
- 在笔记本 UI 中,单击“ 环境 ”侧面板 。
- 在 内存下,选择 高内存。
- 单击“应用”。
此设置也适用于使用笔记本的内存首选项运行的笔记本作业任务。 更新笔记本中的内存首选项会影响下一个作业运行。
查看查询见解
适用于笔记本和作业的无服务器计算使用查询见解来评估 Spark 执行性能。 运行笔记本中的单元格后,可以通过单击“查看性能”链接来查看与 SQL 和 Python 查询相关的见解。
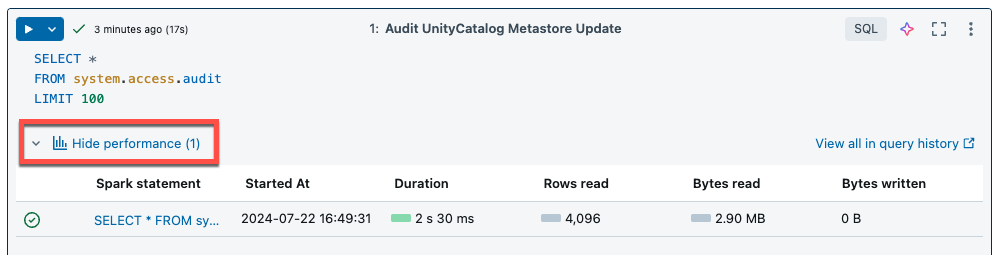
可以单击任一 Spark 语句来查看查询指标。 在此处,可以单击“查看查询配置文件”来查看查询执行的可视化效果。 有关查询配置文件的详细信息,请参阅查询配置文件。
注意
若要查看作业运行的性能见解,请参阅查看作业运行查询见解。
查询历史记录
在无服务器计算上运行的所有查询也会记录到工作区的查询历史记录页上。 有关查询历史记录的信息,请参阅查询历史记录。
查询见解限制
- 查询配置文件仅在查询执行终止后才可用。
- 尽管在执行期间不会显示查询配置文件,但指标会实时更新。
- 仅涵盖以下查询状态:RUNNING、CANCELED、FAILED、FINISHED。
- 无法从查询历史记录页取消正在运行的查询。 可以在笔记本或作业中取消此类查询。
- 不提供详细指标。
- 无法下载查询配置文件。
- 无法访问 Spark UI。
- 语句文本仅包含运行的最后一行。 但是,在此行的前面,可能有几行是作为同一语句的一部分运行的。