入门:增强和清理数据
这篇入门文章将指导你使用 Azure Databricks 笔记本来清理和增强之前使用 Python、Scala 和 R 加载到 Unity Catalog 中的表的纽约州婴儿姓名数据。在本文中,你将更改列名称,更改大写并拼写出原始数据表中每个婴儿姓名的性别,然后将 DataFrame 保存到银牌表中。 接着,筛选数据以仅包含 2021 年的数据,在州级别进行数据分组,然后按计数对数据进行排序。 最后,将此 DataFrame 保存到金牌表中,并在条形图中可视化数据。 有关银牌表和金牌表的详细信息,请参阅奖牌体系结构。
重要
这篇入门文章基于入门:引入和插入其他数据。 必须完成该文章中的步骤才能完成本文。 有关这篇入门文章的完整笔记本,请参阅引入其他数据笔记本。
要求
要完成本文中的任务,必须满足以下要求:
- 工作区必须已启用 Unity Catalog。 有关 Unity Catalog 的入门信息,请参阅设置和管理 Unity Catalog。
- 你必须对卷具有
WRITE VOLUME特权,对父架构具有USE SCHEMA特权,以及对父目录具有USE CATALOG特权。 - 你必须有权使用现有计算资源或创建新的计算资源。 请参阅 Azure Databricks 入门,或者咨询您的 Databricks 管理员。
提示
有关本文已完成的笔记本,请参阅清理和增强数据笔记本。
步骤 1:创建新笔记本
若要在工作区中创建笔记本,请单击边栏中的“![]() 新建”,然后单击“笔记本”。 将在工作区中打开一个空白笔记本。
新建”,然后单击“笔记本”。 将在工作区中打开一个空白笔记本。
若要了解有关创建和管理笔记本的详细信息,请参阅管理笔记本。
步骤 2:定义变量
在此步骤中,定义要在本文中创建的示例笔记本中使用的变量。
将以下代码复制并粘贴到新的空笔记本单元格中: 将
<catalog-name>、<schema-name>和<volume-name>替换为 Unity 目录卷的目录、架构和卷名称。 (可选)将table_name值替换为选择的表名称。 本文稍后会将婴儿姓名数据保存到此表中。按
Shift+Enter以运行单元格并创建新的空白单元格。Python
catalog = "<catalog_name>" schema = "<schema_name>" table_name = "baby_names" silver_table_name = "baby_names_prepared" gold_table_name = "top_baby_names_2021" path_table = catalog + "." + schema print(path_table) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val tableName = "baby_names" val silverTableName = "baby_names_prepared" val goldTableName = "top_baby_names_2021" val pathTable = s"${catalog}.${schema}" print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" table_name <- "baby_names" silver_table_name <- "baby_names_prepared" gold_table_name <- "top_baby_names_2021" path_table <- paste(catalog, ".", schema, sep = "") print(path_table) # Show the complete path
步骤 3:将原始数据加载到新的 DataFrame 中
此步骤将以前保存到 Delta 表中的原始数据加载到新的 DataFrame 中,以准备清理和增强此数据来供进一步分析。
将以下代码复制并粘贴到新的空笔记本单元格中:
Python
df_raw = spark.read.table(f"{path_table}.{table_name}") display(df_raw)Scala
val dfRaw = spark.read.table(s"${pathTable}.${tableName}") display(dfRaw)R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df_raw = sql(paste0("SELECT * FROM ", path_table, ".", table_name)) display(df_raw)按
Shift+Enter以运行单元格,然后移动到下一个单元格。
步骤 4:清理和增强原始数据并保存
在此步骤中,更改 Year 列的名称,将 First_Name 列中的数据更改为初始大写,并更新 Sex 列的值以拼出性别,然后将 DataFrame 保存到新表中。
将以下代码复制并粘贴到空的笔记本单元格中。
Python
from pyspark.sql.functions import col, initcap, when # Rename "Year" column to "Year_Of_Birth" df_rename_year = df_raw.withColumnRenamed("Year", "Year_Of_Birth") # Change the case of "First_Name" column to initcap df_init_caps = df_rename_year.withColumn("First_Name", initcap(col("First_Name").cast("string"))) # Update column values from "M" to "male" and "F" to "female" df_baby_names_sex = df_init_caps.withColumn( "Sex", when(col("Sex") == "M", "Male") .when(col("Sex") == "F", "Female") ) # display display(df_baby_names_sex) # Save DataFrame to table df_baby_names_sex.write.mode("overwrite").saveAsTable(f"{path_table}.{silver_table_name}")Scala
import org.apache.spark.sql.functions.{col, initcap, when} // Rename "Year" column to "Year_Of_Birth" val dfRenameYear = dfRaw.withColumnRenamed("Year", "Year_Of_Birth") // Change the case of "First_Name" data to initial caps val dfNameInitCaps = dfRenameYear.withColumn("First_Name", initcap(col("First_Name").cast("string"))) // Update column values from "M" to "Male" and "F" to "Female" val dfBabyNamesSex = dfNameInitCaps.withColumn("Sex", when(col("Sex") equalTo "M", "Male") .when(col("Sex") equalTo "F", "Female")) // Display the data display(dfBabyNamesSex) // Save DataFrame to a table dfBabyNamesSex.write.mode("overwrite").saveAsTable(s"${pathTable}.${silverTableName}")R
# Rename "Year" column to "Year_Of_Birth" df_rename_year <- withColumnRenamed(df_raw, "Year", "Year_Of_Birth") # Change the case of "First_Name" data to initial caps df_init_caps <- withColumn(df_rename_year, "First_Name", initcap(df_rename_year$First_Name)) # Update column values from "M" to "Male" and "F" to "Female" df_baby_names_sex <- withColumn(df_init_caps, "Sex", ifelse(df_init_caps$Sex == "M", "Male", ifelse(df_init_caps$Sex == "F", "Female", df_init_caps$Sex))) # Display the data display(df_baby_names_sex) # Save DataFrame to a table saveAsTable(df_baby_names_sex, paste(path_table, ".", silver_table_name), mode = "overwrite")按
Shift+Enter以运行单元格,然后移动到下一个单元格。
步骤 5:对数据进行分组和可视化
在此步骤中,筛选数据以仅显示 2021 年的数据,按性别和姓名对数据进行分组,按计数聚合并按计数排序。 然后将 DataFrame 保存到表,接着在条形图中可视化数据。
将以下代码复制并粘贴到空的笔记本单元格中。
Python
from pyspark.sql.functions import expr, sum, desc from pyspark.sql import Window # Count of names for entire state of New York by sex df_baby_names_2021_grouped=(df_baby_names_sex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count"))) # Display data display(df_baby_names_2021_grouped) # Save DataFrame to a table df_baby_names_2021_grouped.write.mode("overwrite").saveAsTable(f"{path_table}.{gold_table_name}")Scala
import org.apache.spark.sql.functions.{expr, sum, desc} import org.apache.spark.sql.expressions.Window // Count of male and female names for entire state of New York by sex val dfBabyNames2021Grouped = dfBabyNamesSex .filter(expr("Year_Of_Birth == 2021")) .groupBy("Sex", "First_Name") .agg(sum("Count").alias("Total_Count")) .sort(desc("Total_Count")) // Display data display(dfBabyNames2021Grouped) // Save DataFrame to a table dfBabyNames2021Grouped.write.mode("overwrite").saveAsTable(s"${pathTable}.${goldTableName}")R
# Filter to only 2021 data df_baby_names_2021 <- filter(df_baby_names_sex, df_baby_names_sex$Year_Of_Birth == 2021) # Count of names for entire state of New York by sex df_baby_names_grouped <- agg( groupBy(df_baby_names_2021, df_baby_names_2021$Sex, df_baby_names_2021$First_Name), Total_Count = sum(df_baby_names_2021$Count) ) # Display data display(arrange(select(df_baby_names_grouped, df_baby_names_grouped$Sex, df_baby_names_grouped$First_Name, df_baby_names_grouped$Total_Count), desc(df_baby_names_grouped$Total_Count))) # Save DataFrame to a table saveAsTable(df_baby_names_2021_grouped, paste(path_table, ".", gold_table_name), mode = "overwrite")按
Ctrl+Enter运行该单元格。-
- 在“表”选项卡旁边,单击 +,然后单击“可视化效果”。
在可视化编辑器中,单击“可视化类型”,然后验证是否已选择“条形”。
在 X 列中选择“”。
First_Name单击 Y 列下的“添加列”,然后选择“Total_Count”。
在“分组依据”中选择“性别”。
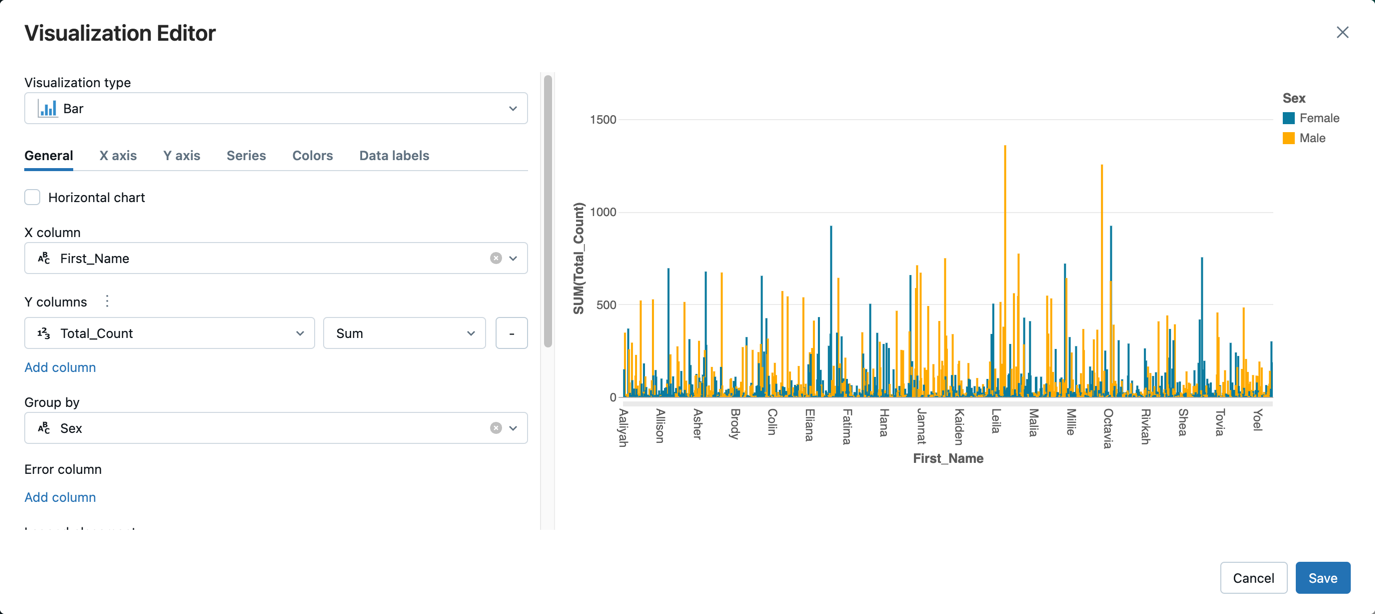
单击“ 保存”。
清理和增强数据笔记本
使用以下笔记本之一执行本文中的步骤。 将 <catalog-name>、<schema-name> 和 <volume-name> 替换为 Unity 目录卷的目录、架构和卷名称。 (可选)将 table_name 值替换为选择的表名称。