入门:通过笔记本查询和可视化数据
本入门文章将指导你使用 Azure Databricks 笔记本通过 SQL、Python、Scala 和 R 查询 Unity Catalog 中存储的示例数据,然后在笔记本中可视化查询结果。
要求
要完成本文中的任务,必须满足以下要求:
- 工作区必须已启用 Unity Catalog。 有关 Unity Catalog 的入门信息,请参阅设置和管理 Unity Catalog。
- 你必须有权使用现有计算资源或创建新的计算资源。 请参阅 Azure Databricks 入门指南,或联系您的 Databricks 管理员。
步骤 1:创建新笔记本
若要在工作区中创建笔记本,请单击边栏中的“![]() 新建”,然后单击“笔记本”。 将在工作区中打开一个空白笔记本。
新建”,然后单击“笔记本”。 将在工作区中打开一个空白笔记本。
若要了解有关创建和管理笔记本的详细信息,请参阅管理笔记本。
步骤 2:查询表
使用所选语言查询 Unity Catalog 中的 samples.nyctaxi.trips 表。
将以下代码复制并粘贴到新的空笔记本单元格中: 此代码显示了对 Unity Catalog 中
samples.nyctaxi.trips表的查询结果。SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))按
Shift+Enter以运行单元格,然后移动到下一个单元格。查询结果显示在笔记本中。
步骤 3:显示数据
按行程距离显示平均车费金额,数据按上车地点邮政编码分组。
在“表”选项卡旁边,单击 +,然后单击“可视化效果”。
这会显示可视化效果编辑器。
在“可视化效果类型”下拉列表中,确认是否已选择“条形图”。
为“X 列”选择
fare_amount。为“Y 列”选择
trip_distance。选择
Average作为聚合类型。选择
pickup_zip作为“分组依据”列。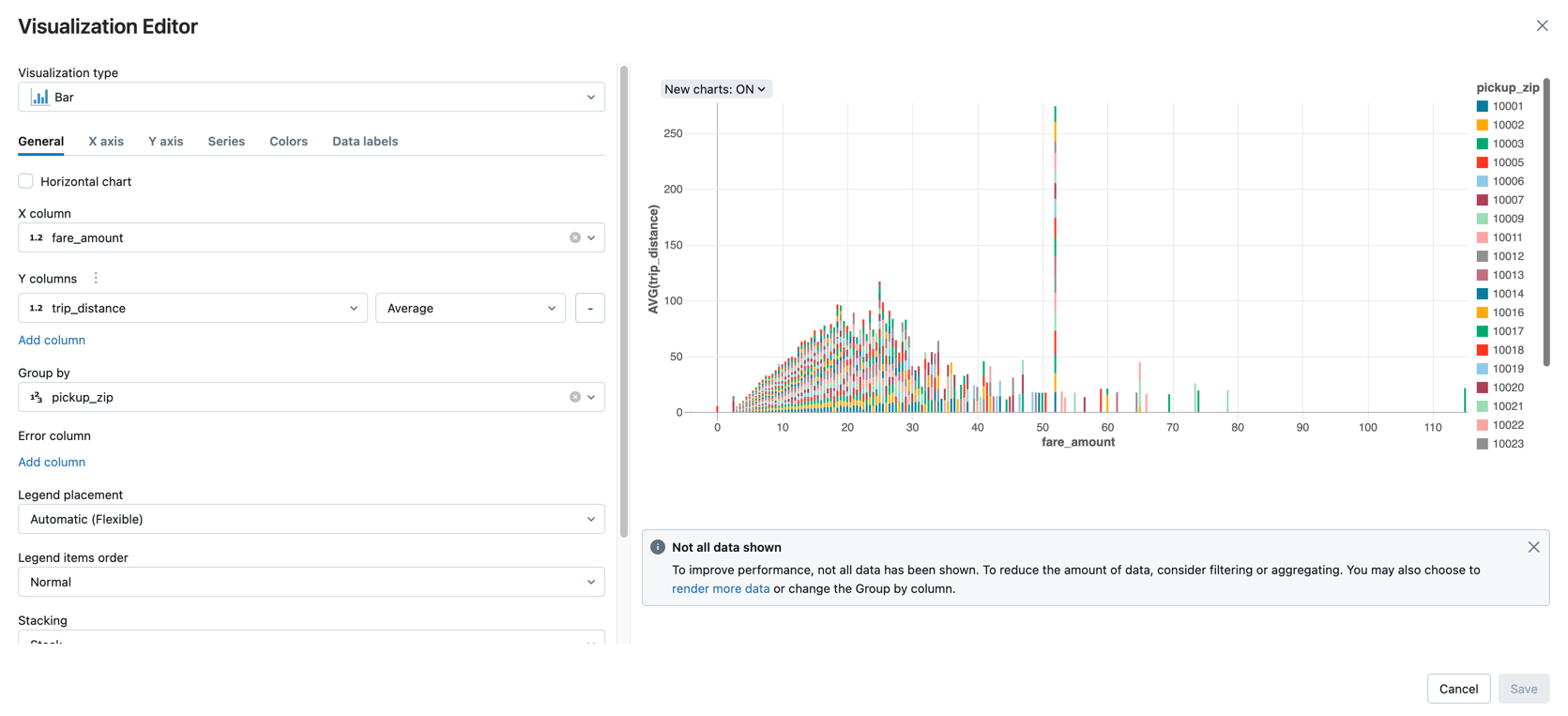
单击“ 保存”。
后续步骤
- 要了解如何将数据从 CSV 文件添加到 Unity Catalog 并进行可视化,请参阅入门:从笔记本导入 CSV 数据并可视化。
- 若要了解如何使用 Apache Spark 将数据加载到 Databricks 中,请参阅教程:使用 Apache Spark 数据帧加载和转换数据。
- 若要详细了解如何将数据引入 Databricks,请参阅将数据引入 Databricks Lakehouse。
- 若要详细了解如何使用 Databricks 查询数据,请参阅查询数据。
- 若要详细了解可视化效果,请参阅 Databricks 笔记本中的可视化效果。