你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
SAP 数据提取的性能和故障排除
本文是“SAP 扩展和创新数据:最佳做法”系列文章的一部分。
可通过多种方式连接到 SAP 系统进行数据集成。 以下部分介绍常规和特定于连接器的注意事项和建议。
性能
请务必为源和目标配置最佳设置,以便在数据提取和处理期间实现最佳性能。
一般注意事项
- 确保为最大并发连接数设置了正确的 SAP 参数。
- 请考虑使用 SAP 组登录类型来提高性能和负载分布。
- 确保自承载集成运行时 (SHIR) 虚拟机的大小适当且高度可用。
- 使用大型数据集时,检查所使用的连接器是否提供分区功能。 许多 SAP 连接器支持分区和并行化功能,以加快数据加载速度。 使用此方法时,数据将打包到较小的区块中,可以使用多个并行进程加载这些区块。 有关详细信息,请参阅特定于连接器的文档。
一般建议
使用 SAP 事务 RZ12 修改最大并发连接数的值。
RFC 的 SAP 参数 - RZ12:以下参数可以限制一个用户或一个应用程序允许的 RFC 调用数,因此请确保此限制不会导致瓶颈。
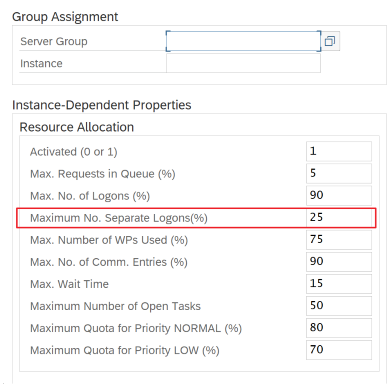
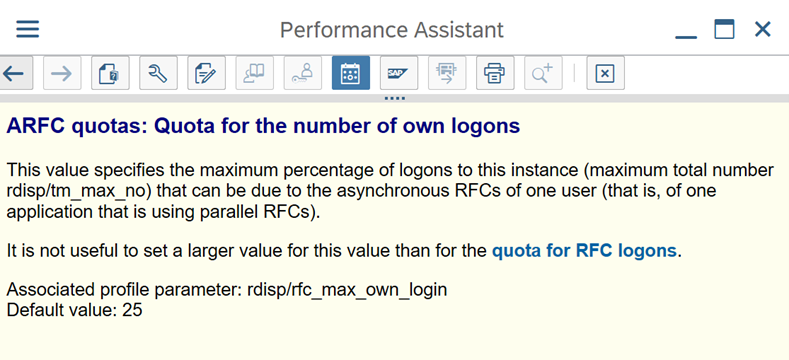
使用登录组连接到 SAP:SHIR (自承载集成运行时) 应使用 SAP 登录组 (通过消息服务器) 连接到 SAP,而不是连接到特定应用程序服务器,以确保工作负载在所有可用应用程序服务器之间分布。
注意
数据流 Spark 群集和 SHIR 非常强大。 许多内部 SAP 复制活动(例如 16)可以触发和执行。 但是,如果 SAP 服务器的并发连接数较小(例如 8),则性能将从 SAP 端读取数据。
从适用于 SHIR 的 4vCPU 和 16 GB VM 开始。 以下步骤演示了 SAP 中对话工作进程与 SHIR 的连接。
- 检查客户是否使用较差的物理计算机来设置和安装 SHIR 以运行内部 SAP 副本。
- 转到Azure 数据工厂门户,找到数据流中使用的相关 SAP CDC 链接服务。 检查引用的 SHIR 名称。
- 检查安装了 SHIR 的物理计算机的 CPU、内存、网络和磁盘设置。
- 检查 SHIR 计算机上正在运行的多少
diawp.exe个。 可以diawp.exe运行一个复制活动。 的数量diawp.exe取决于计算机的 CPU、内存、网络和磁盘设置。
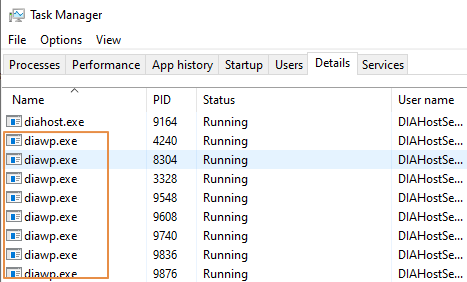
如果要同时在 SHIR 上并行运行多个分区,请使用功能强大的虚拟机来设置 SHIR。 或者使用 SHIR 高可用性和可伸缩性功能进行横向扩展,以拥有多个节点。 有关详细信息,请参阅高可用性和可伸缩性。
分区
以下部分介绍 SAP CDC 连接器的分区过程。 对于 SAP 表和 SAP BW Open Hub 连接器,此过程是相同的。

可以根据性能要求,在自承载 IR 或 Azure IR 上执行缩放。 查看 SHIR 的 CPU 消耗,查看指标,以帮助你决定缩放方法。 SHIR 可以根据需要垂直或水平缩放。 建议在较低的 SKU 上部署 Azure IR。 纵向扩展以满足通过负载测试确定的性能要求,而不是不必要地从更高端开始。
注意
如果容量达到 70%,请针对 SHIR 纵向扩展或横向扩展。

分区对于初始或大型完整加载很有用,并且通常不需要增量加载。 如果未指定分区,则默认情况下,SAP 系统中有 1 个“生成者” (通常是一个批处理) 将源数据提取到 odQ) (操作数据队列中,SHIR 从 ODQ 提取数据。 默认情况下,SHIR 使用四个线程从 ODQ 提取数据,因此当时 SAP 中可能会占用四个对话进程。
分区的思路是将大型初始数据集拆分为多个较小的不连续子集,这些子集在理想情况下大小相等,并且可以并行处理。 此方法可减少以线性方式将数据从源表生成到 ODQ 所需的时间。 此方法假定 SAP 端有足够的资源来处理负载。
注意
- 并行执行的分区数受 Azure IR 中的驱动程序核心数限制。 此限制的解决方法目前正在进行中。
- SAP 事务 ODQMON 中的每个单元或包都是暂存文件夹中的单个文件。
使用 CDC 运行管道时的设计注意事项
检查 SAP 以暂存持续时间。
检查接收器中的运行时性能。
请考虑使用分区功能来增强性能以提高吞吐量。
如果 SAP 到阶段持续时间较慢,请考虑将 SHIR 大小调整为更高的规范。
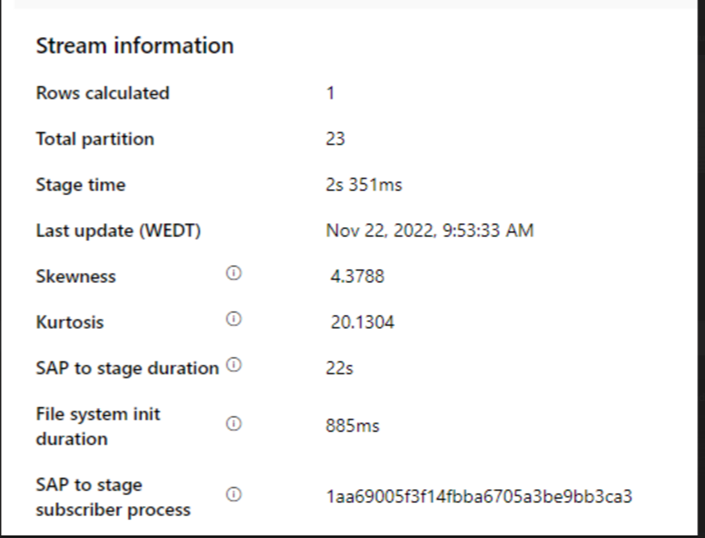
检查接收器处理时间是否太慢。
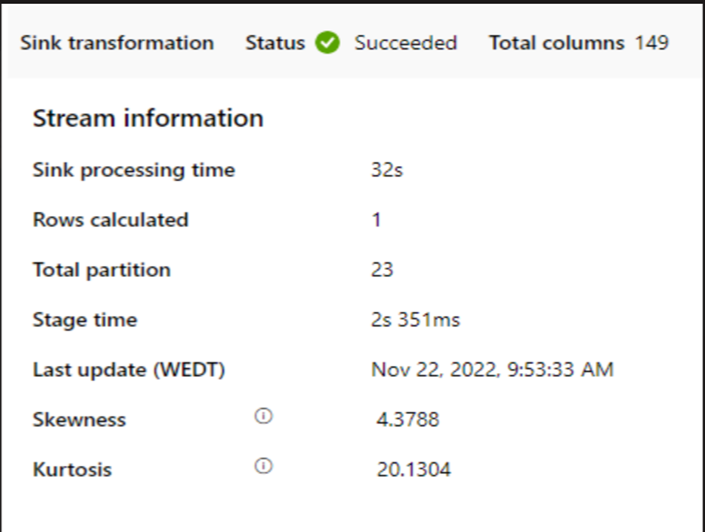
如果使用小型群集来运行映射数据流,则可能会影响接收器的性能。 使用大型群集(例如 16 + 256 个核心),以便性能从阶段读取数据并写入接收器。
对于大型数据卷,建议对负载进行分区以运行并行作业,但将分区数保留小于或等于 Azure IR 核心(也称为 Spark 群集核心)。
使用“ 优化 ”选项卡定义分区。 可以在 CDC 连接器中使用源分区。
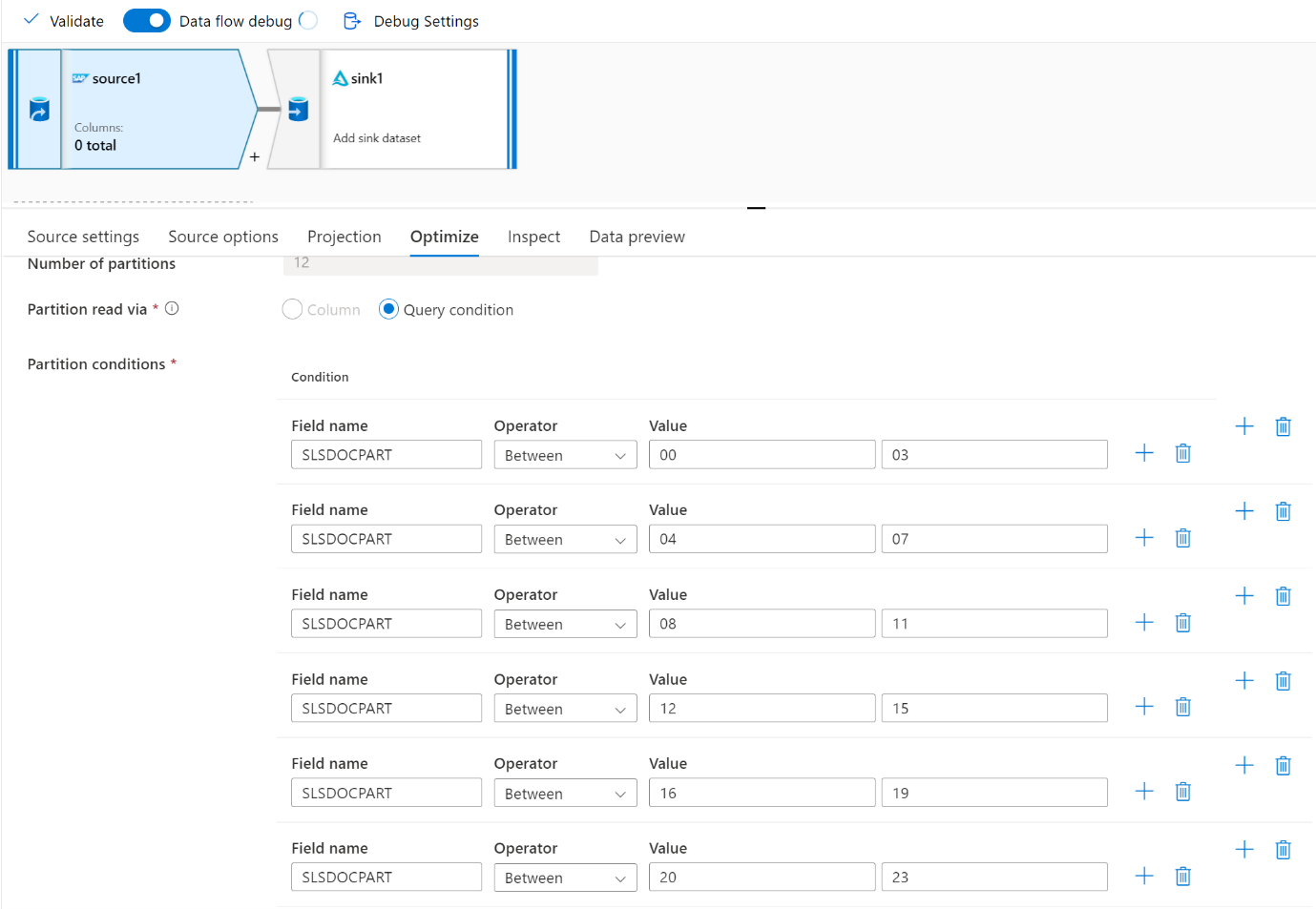
注意
- 具有 SHIR 核心的分区数与 Azure IR 节点之间存在直接关联。
- SAP CDC 连接器在 SAP 系统中的 ODQMON 下列为 Odata 订阅者类型“Odata Access for Operational Data Provisioning”。
使用表连接器时的设计注意事项
- 优化分区以提高性能。
- 考虑 SAP 表的并行度。
- 考虑目标接收器的单个文件设计。
- 使用大量数据时,对吞吐量进行基准测试。
使用表连接器时的设计建议
分区: 在 SAP 表连接器中分区时,它会使用 where 子句位于合适的字段(例如基数较高的字段)将一个基础 select 语句拆分为多个语句。 如果 SAP 表包含大量数据,请启用分区以将数据拆分为较小的分区。 尝试优化 (参数
maxPartitionsNumber) 的分区数,以便分区足够小,以避免 SAP 中的内存转储,但足够大以加快提取速度。并行: 参数
parallelCopies) (复制并行度与分区协同工作,并指示 SHIR 对 SAP 系统进行并行 RFC 调用。 例如,如果将此参数设置为 4,则服务会根据指定的分区选项和设置同时生成并运行四个查询。 每个查询从 SAP 表中检索一部分数据。为了获得最佳结果,分区数应是复制并行度数的倍数。
将数据从 SAP 表复制到二进制接收器时,将根据 SHIR 中可用的内存量自动调整实际并行计数。 记录每个测试周期的 SHIR VM 大小、复制并行度和分区数。 观察 SHIR VM 的性能、源 SAP 系统的性能,以及所需的并行度与实际并行度。 使用迭代过程来确定 SHIR VM 的最佳设置和理想大小。 考虑同时从一个或多个 SAP 系统加载数据的所有引入管道。
请注意观察到针对配置的并行度对 SAP 的 RFC 调用数。 如果对 SAP 的 RFC 调用次数小于并行度,请验证 SHIR VM 是否有足够的可用内存和 CPU 资源。 如有必要,请选择更大的虚拟机。 源 SAP 系统配置为限制并行连接数。 有关详细信息,请参阅本文中的 常规建议 部分。
文件数: 将数据复制到基于文件的数据存储中并且目标接收器配置为文件夹时,默认情况下会生成多个文件。 如果在接收器中设置
fileName属性,则数据将写入单个文件。 建议以多个文件的形式写入文件夹,因为与写入单个文件相比,该文件夹的写入吞吐量更高。性能基准: 建议使用性能基准测试练习来引入大量数据。 此方法会改变参数,例如分区、并行度和文件数,以确定给定体系结构、卷和数据类型的最佳设置。 使用以下格式从测试收集数据。


疑难解答
对于从 SAP 系统提取速度缓慢或失败的问题,请使用 SM37 中的 SAP 日志,并将其与数据工厂中的读数匹配。
如果只触发了一个批处理作业,请将 SAP 源分区设置为提高数据工厂中映射数据流的性能。 有关详细信息,请参阅 映射数据流属性中的步骤 6。
如果在 SAP 系统中触发了多个批处理作业 ,并且每个批处理作业的开始时间之间存在显著差异,请更改 Azure IR 的大小。 增加 Azure IR 中的驱动程序节点数时,SAP 端批处理作业的并行度会增加。
注意
Azure IR 的最大驱动程序节点数为 16。 每个驱动程序节点只能触发一个批处理。
检查 SHIR 中的日志。 若要查看日志,请转到 SHIR VM。 打开事件查看器 > 应用程序和服务日志 > 连接器 > 集成运行时。
若要将日志发送到支持人员,请转到 SHIR VM。 打开Integration Runtime配置管理器>诊断>发送日志。 此操作发送过去七天的日志,并提供报告 ID。 需要此运行的报告 ID 和 RunId。 记录报表 ID 以供将来参考。
在 SLT 方案中使用 SAP CDC 连接器时:
确保满足先决条件。 SAP 横向转换 (SLT) 用户需要角色,例如 OLTP 系统中的 ADFSLTUSER 或 ECC 才能使 SLT 复制正常工作。 有关详细信息,请参阅 需要哪些授权和角色。
如果 SLT 方案中发生错误,请参阅分析建议。 首先在 SAP 解决方案中隔离并测试方案。 例如,通过在 SE38 中运行 SAP
RODPS_REPL_TEST提供的测试程序,在数据工厂外部对其进行测试。 如果问题出在 SAP 端,则使用报表时会出现相同的错误。 可以使用事务代码ODQMON在 SAP 中分析数据提取。如果使用此测试报告时复制有效,但不适用于数据工厂,请联系 Azure 或数据工厂支持人员。
以下示例显示了 SE38 中的 报表
RODPS_REPL_TEST: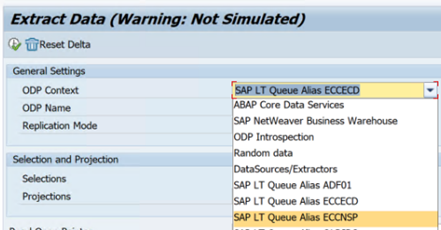
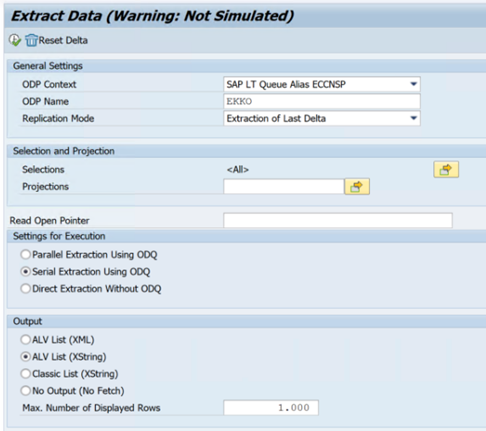

以下示例显示了事务代码
ODQMON: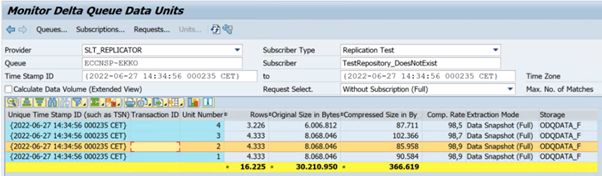
当数据工厂链接服务连接到 SLT 系统时,刷新 上下文 字段时不会显示 SLT 大容量传输 ID。
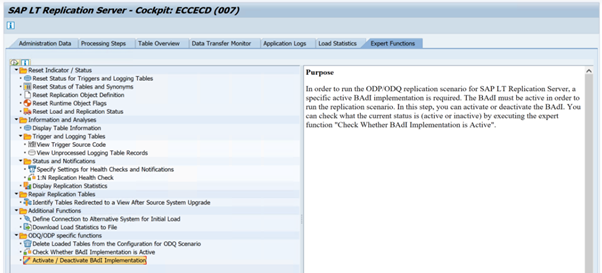
若要为 SAP LT 复制服务器运行 ODP/ODQ 复制方案,请激活以下业务外接程序 (BAdI) 实现。
BAdI:
BADI_ODQ_QUEUE_MODEL增强实现:
ODQ_ENH_SLT_REPLICATION在事务 LTRC 中,转到“ 专家函数 ”选项卡,然后选择 “激活/停用 BAdI 实现 ”以激活实现。
请选择“是”。
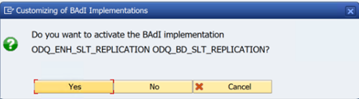
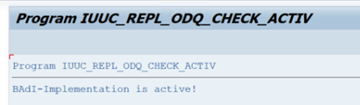
在 ODQ/ODP 特定函数 文件夹中,选择“ 检查 BAdI 实现是否处于活动状态”。

对话框显示程序活动。
重置订阅。 若要从全新提取或停止复制数据开始,请删除 ODQMON 中的订阅。 此操作还会从 LTRC 中删除条目。 重置订阅后,可能需要几分钟才能在 LTRC 中看到效果。 计划操作数据预配 (ODP) 维护作业,以保持增量队列的清洁,例如
ODQ_CLEANUP_CLIENT_004CDS_VIEW (DHCDCMON 事务) 。 从 S/4HANA 1909 开始,SAP 从使用基于数据的触发器而不是日期列的 CDS 视图中复制数据。 该概念类似于 SLT,但不是使用 LTRC 事务来监视它,而是使用 DHCDCMON 事务。
SLT 故障排除
SLT 复制服务器提供从 SAP 源和/或非 SAP 源到 SAP 目标和/或非 SAP 目标的实时数据复制。 有三种类型的工具集用于监视从 SLT 到 Azure 的提取。
- ODQMON 是用于数据提取的整体监视工具。 使用 ODQMON 开始分析,以跟踪数据不一致、初始性能分析以及打开的订阅和提取请求。
- LTRC 是用于检查性能分析的事务。 如果存在从源系统到 ODP 的数据复制问题,这非常有用,因为可以监视数据流并发现不一致之处。
- SM37 提供每个 SLT 提取步骤的详细监视。
正常内务处理应使用 ODQMON 完成,你可以在其中直接管理订阅,并且不应将 LTRC 用于相同操作。
从 SLT 提取数据时可能会遇到问题,例如:
提取不会运行。 检查 SAP CDC 连接是否在 ODQMON 中创建了连接,并检查订阅是否存在。
数据不一致。 检查 ODQMON 以查看单个数据请求,并确认可以在其中查看数据。 如果可以在 ODQMON 中看到数据,但在 Azure Synapse 或数据工厂中看不到,则调查应在 Azure 端进行。 如果在 ODQMON 中看不到数据,请使用 LTRC 对 SLT 框架执行分析。
性能问题。 数据提取是一种两步方法。 首先,SLT 从源系统读取数据并将其传输到 ODP。 其次,SAP CDC 连接器从 ODP 提取数据并将其传输到所选数据存储。 LTRC 事务允许分析提取过程的第一部分。 若要分析从 ODP 到 Azure 的数据提取,请使用 ODQMON 和数据工厂或 Synapse 监视工具。
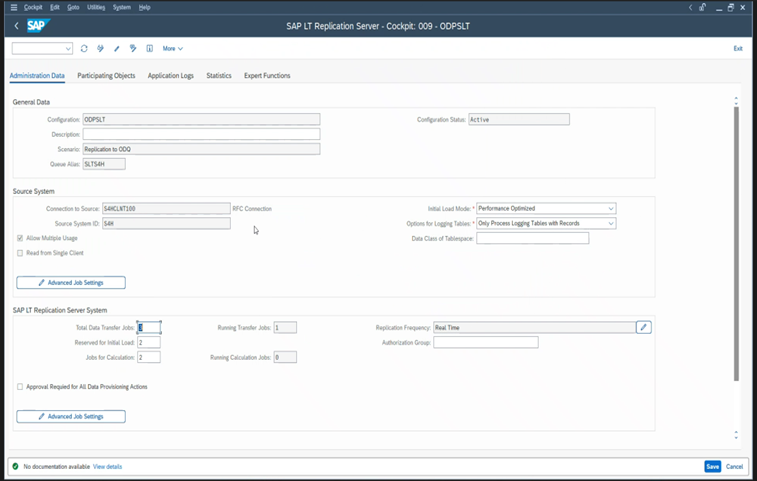
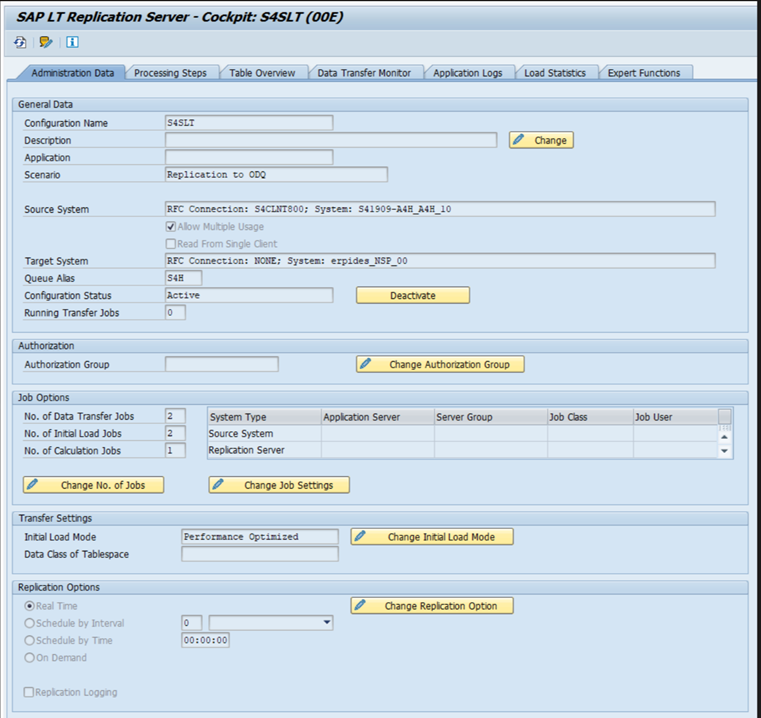
SLT 性能
在初始加载模式下, (ODPSLT) ,需要执行三个步骤将数据从 SLT 提取到 ODP:
- 创建迁移对象。 此过程只需几秒钟。
- 访问将源表拆分为较小区块的计划计算。 此步骤取决于在 SLT 配置期间选择的初始加载模式和表的大小。 建议使用资源优化选项。
- 数据负载将数据从源系统传输到 ODP。
每个步骤都由后台作业控制。 可以使用 SM37 和 LTRC 事务来监视持续时间。 如果系统过度使用,后台作业可能会稍后启动,因为没有足够的可用批处理工作进程。 当任务处于空闲状态时,性能会受到影响。
如果访问计划计算需要很长时间,并且初始加载模式设置为“性能优化”,请将其更改为“资源优化”,然后重新运行提取。 如果数据加载需要很长时间,请增加配置中的并行线程数。
如果将 SLT 复制的独立体系结构 (专用 SLT 复制服务器) ,则源系统和复制服务器之间的网络吞吐量可能会影响提取性能。
对于复制:
- 确保有足够的数据传输作业未为初始负载保留。
- 检查负载统计信息中是否没有未处理的日志记录表记录。
- 确保复制选项设置为实时。
LTRS 中提供了高级复制设置。 有关详细信息,请参阅 SLT 故障排除指南。
不同的 SAP 版本具有不同的 LTRC 用户界面。 以下屏幕截图显示了两个不同版本的同一页面。
SAP S/4HANA:
SAP ECC:


监视
有关监视 SAP 数据提取的信息,请参阅以下资源: