发票处理预生成 AI 模型
账单处理预生成 AI 模型提取关键发票数据来帮助自动化发票处理。 发票处理模型经过优化,可以识别常见的发票元素,如发票 ID、发票日期、到期金额等。
通过发票模型,您可以通过生成自定义发票模型来增强默认行为。
在 Power Apps 中使用
要了解如何使用 Power Apps 中的发票处理预生成模型的信息,请转到使用 Power Apps 中的发票处理预生成模型。
在 Power Automate 中使用
要了解如何使用 Power Automate 中的发票处理预生成模型的信息,请转到使用 Power Automate 中的发票处理预生成模型。
支持的语言和文件
支持以下语言:阿尔巴尼亚语(阿尔巴尼亚)、捷克语(捷克共和国)、中文(简体)、中文(繁体,香港特别行政区)、中文(繁体,台湾)、丹麦语(丹麦)、克罗地亚语(波斯尼亚和黑塞哥维那)、克罗地亚语(克罗地亚)、克罗地亚语(塞尔维亚)、荷兰语(荷兰)、英语(澳大利亚)、英语(加拿大)、英语(印度)、英语(英国)、英语(美国)、爱沙尼亚语(爱沙尼亚)、芬兰语(芬兰),法语(法国)、德语(德国)、匈牙利语(匈牙利)、冰岛语(冰岛)、意大利语(意大利)、日语(日本)、韩语(韩国)、立陶宛语(立陶宛)、拉脱维亚语(拉脱维亚)、马来语(马来西亚)、挪威语(挪威)、波兰语(波兰)、葡萄牙语(葡萄牙)、罗马尼亚语(罗马尼亚)、斯洛伐克语(斯洛伐克)、斯洛文尼亚语(斯洛文尼亚)、塞尔维亚语(塞尔维亚)、西班牙语(西班牙)、瑞典语(瑞典)。
要获得最佳效果,请为每个账单提供一张清晰的照片或扫描件。
- 图像格式必须是 JPEG、PNG 或 PDF。
- 文件大小不能超过 20 MB。
- 图像尺寸必须介于 50 x 50 像素与 10,000 x 10,000 像素之间。
- PDF 尺寸必须为最大 17 x 17 英寸(等于 Legal 或 A3 纸张大小)或更小。
- 对于 PDF 文档,将仅处理前 2,000 个页面。
模型输出
如果检测到发票,发票处理模型将输出以下信息:
| 属性 | 定义 |
|---|---|
| 到期金额(文本) | 发票上写明的到期金额. |
| 到期金额(数字) | 以标准化数字格式显示的到期金额。 示例:1234.98。 |
| 到期金额的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 帐单地址 | 帐单邮寄地址。 |
| 账单地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 账单地址收件人 | 帐单地址收件人。 |
| 账单地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 客户地址 | 客户地址。 |
| 客户地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 客户地址收件人 | 客户地址收件人。 |
| 客户地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 客户 ID | 客户 ID。 |
| 客户 ID 的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 客户名称 | 客户姓名。 |
| 客户名称的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 客户纳税人标识号 | 与客户关联的纳税人编号。 |
| 客户纳税人标识号置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 截止日期(文本) | 发票上写明的截止日期。 |
| 截止日期(日期) | 以标准化日期格式显示的截止日期。 示例:2019-05-31。 |
| 截止日期的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 发票日期(文本) | 发票上写明的发票日期。 |
| 发票日期(日期) | 以标准化日期格式显示的账单日期。 示例:2019-05-31。 |
| 账单日期的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 发票编码 | 发票编码。 |
| 账单 ID 的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 发票总额(文本) | 发票上写明的发票总额。 |
| 发票总额(数字) | 以标准化日期格式显示的账单总额。 示例:2019-05-31。 |
| 账单总额的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 明细项目 | 从发票中提取的明细项目。 每列都有可信度分数。
|
| 付款方式 | 发票的付款条款。 |
| 付款条款置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 采购订单 | 采购订单。 |
| 采购订单的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 先前未付余额(文本) | 发票上写明的先前未付余额。 |
| 先前未付余额(数字) | 以前未付的标准数字格式的余额。 示例:1234.98。 |
| 先前未付余额的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 汇款地址 | 汇款地址。 |
| 汇款地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 汇款地址收件人 | 汇款地址收件人。 |
| 汇款地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 服务地址 | 服务地址。 |
| 服务地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 服务地址收件人 | 服务地址收件人。 |
| 服务地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 服务开始日期(文本) | 发票上写明的服务开始日期。 |
| 服务开始日期(日期) | 采用标准化日期格式的服务开始日期。 示例:2019-05-31。 |
| 服务开始日期的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 服务结束日期(文本) | 发票上写明的服务结束日期。 |
| 服务结束日期(日期) | 采用标准化日期格式的服务结束日期。 示例:2019-05-31。 |
| 服务结束日期的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 送货地址 | 送货地址。 |
| 送货地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 送货地址收件人 | 送货地址收件人。 |
| 送货地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 小计(文本) | 发票上写明的小计。 |
| 小计(数字) | 以标准化数字格式显示的小计。 示例:1234.98。 |
| 小计置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 总税款(文本) | 发票上写明的总税款。 |
| 总税款(数字) | 以标准化数字格式显示的总税款。 示例:1234.98。 |
| 总税款的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 供应商地址 | 供应商地址。 |
| 供应商地址的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 供应商地址收件人 | 供应商地址收件人。 |
| 供应商地址收件人的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 供应商名称 | 供应商名称。 |
| 供应商名称的置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 供应商纳税人标识号 | 与供应商关联的纳税人编号。 |
| 供应商纳税人标识号置信度 | 模型对其预测的置信度。 分数在 0(低置信度)到 1(高置信度)之间。 |
| 检测到的文本 | 来自发票上运行的 OCR 的识别的文本行。 作为文本列表的一部分返回。 |
| 检测到的键 | 键值对是所有标识的标签或键及其关联的响应或值。 您可以使用这些值提取不属于预定义字段列表的其他值。 |
| 检测到的值 | 键值对是所有标识的标签或键及其关联的响应或值。 您可以使用这些值提取不属于预定义字段列表的其他值。 |
键值对
键值对是所有标识的标签或键及其关联的响应或值。 您可以使用这些值提取不属于预定义字段列表的其他值。
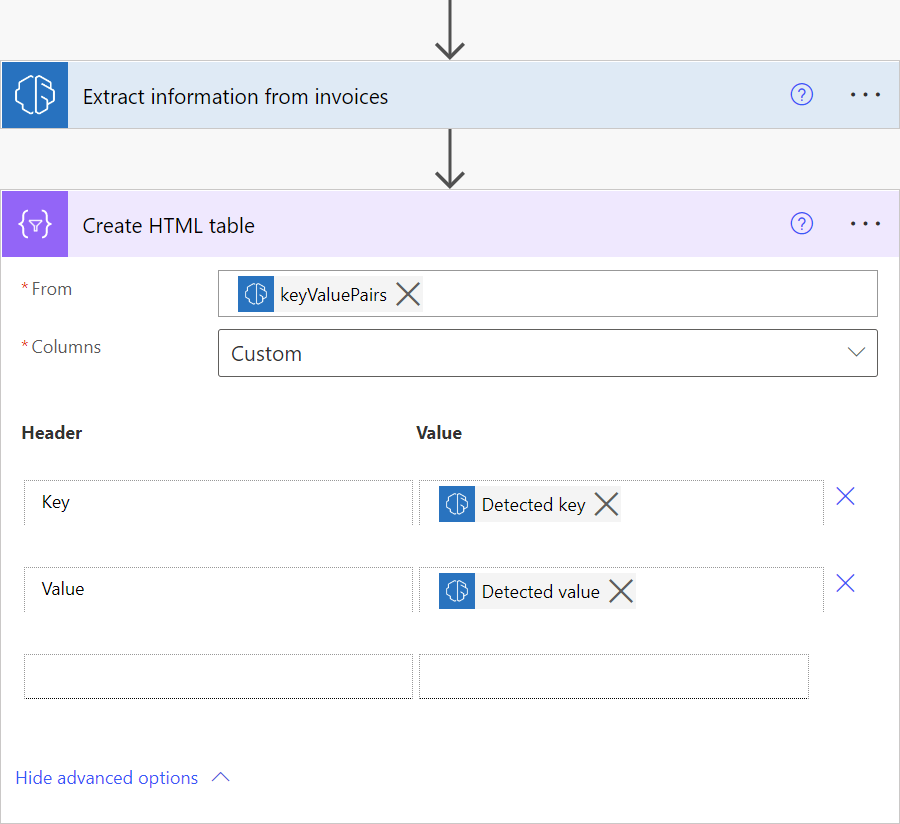
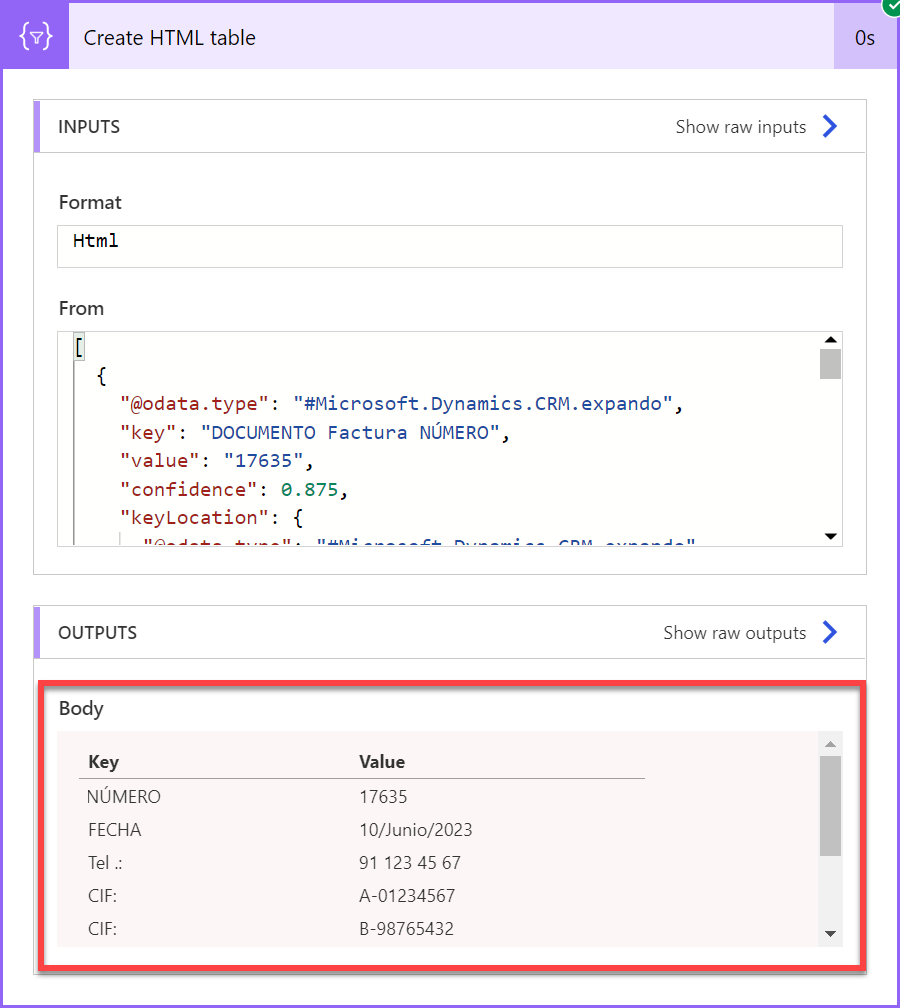
要可视化发票处理模型检测到的所有键值对,可以在流中添加创建 HTML 表操作(如屏幕截图所示),然后运行流。
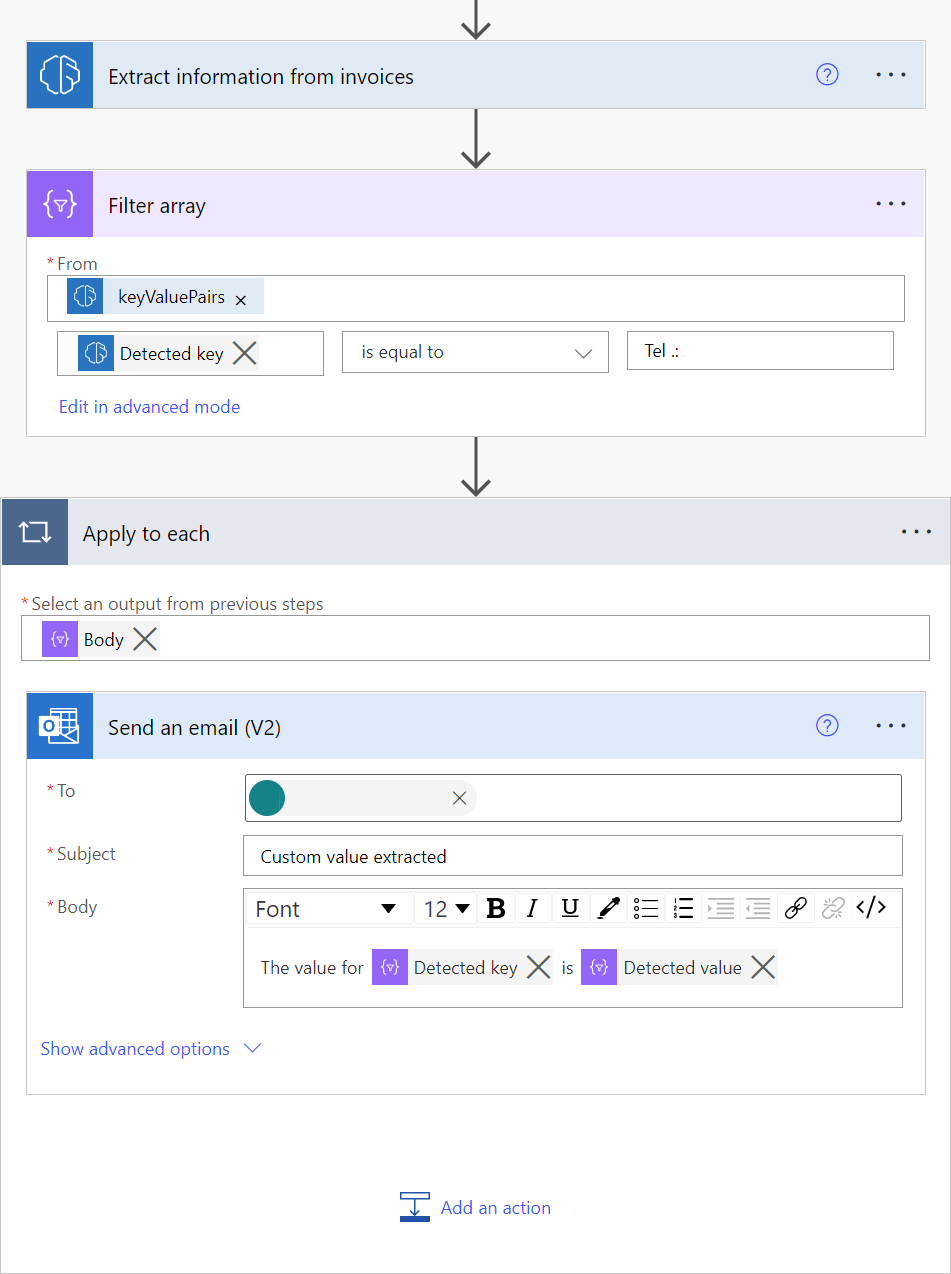
要提取您知道其值的特定键,可以使用筛选数组操作,如下面的屏幕截图所示。 在屏幕截图的示例中,我们要提取键 Tel 的值:
限额
以下限制适用于跨文档处理模型(包括预生成模型)对各个环境发起的调用:收据处理和发票处理。
| 操作 | 限制 | 续订期 |
|---|---|---|
| 调用(每个环境) | 360 | 60 秒 |
创建自定义账单处理解决方案
账单处理预生成 AI 模型用于提取账单中的通用字段。 因为每个业务都是唯一的,所以您可能要提取除此预生成模型中包含的字段以外的字段。 对于您使用的特定类型的发票,某些标准字段也可能无法很好地提取。 要解决这个问题,有两个选项:
使用自定义发票处理模型:通过添加在默认情况下没有提取的新字段或无法正确提取的文档示例来增强预生成发票处理模型的行为。 要了解如何增强预生成发票处理模型,请转到选择文档类型。
查看原始 OCR 结果:每当账单处理预生成 AI 模型处理您提供的文件时,它还会执行 OCR 操作来提取文件上所写的每个字词。 您可以在检测到的模型提供的文本输出上访问原始 OCR 结果。 对检测到的文本返回的内容进行简单搜索可能足以获取所需的数据。
使用文档处理:使用 AI Builder,您还可以生成自己的自定义 AI 模型,来提取您处理的文档所需的特定字段和表。 只需创建一个文档处理模型,然后训练它从发票中提取所有不能从发票提取模型提取的信息。
训练自定义文档处理模型后,您可以将其与 Power Automate 流中的发票处理预生成模型结合使用。
以下是一些示例:
使用自定义文档处理模型提取发票处理预生成模型未返回的其他字段
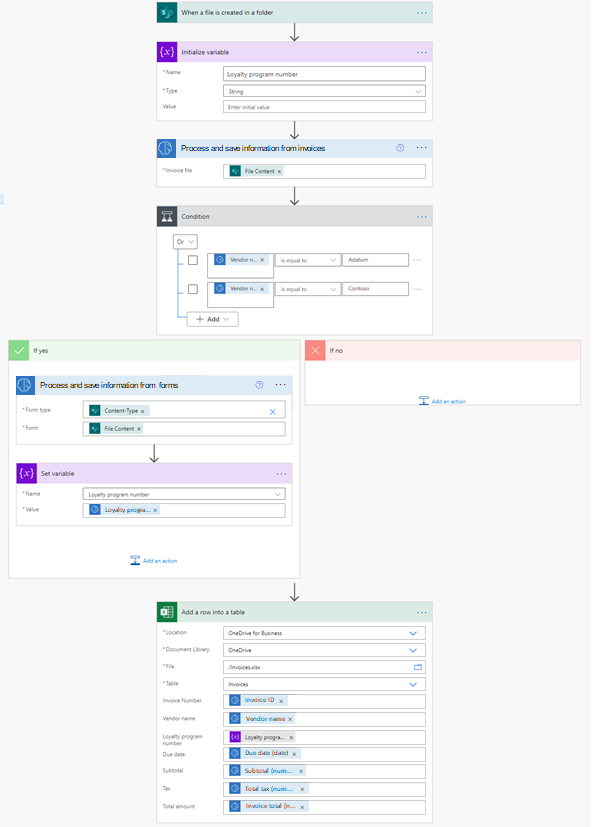
在此示例中,我们训练了一个自定义文档处理模型来提取会员计划编号,该编号仅出现在来自 Adatum 和 Contoso 提供商的发票中。
流在新账单被添加到 SharePoint 文件夹时触发。 然后,它调用账单处理预生成 AI 模型来提取数据。 接下来,我们检查已处理发票的供应商是否来自 Adatum 或 Contoso。 如果是这种情况,我们则会调用一个我们训练过的自定义文档处理模型来获取该会员编号。 最后,我们将从账单提取的数据保存在 Excel 文件中。
如果发票处理预生成模型返回的字段的置信度分数较低,请使用自定义文档处理模型
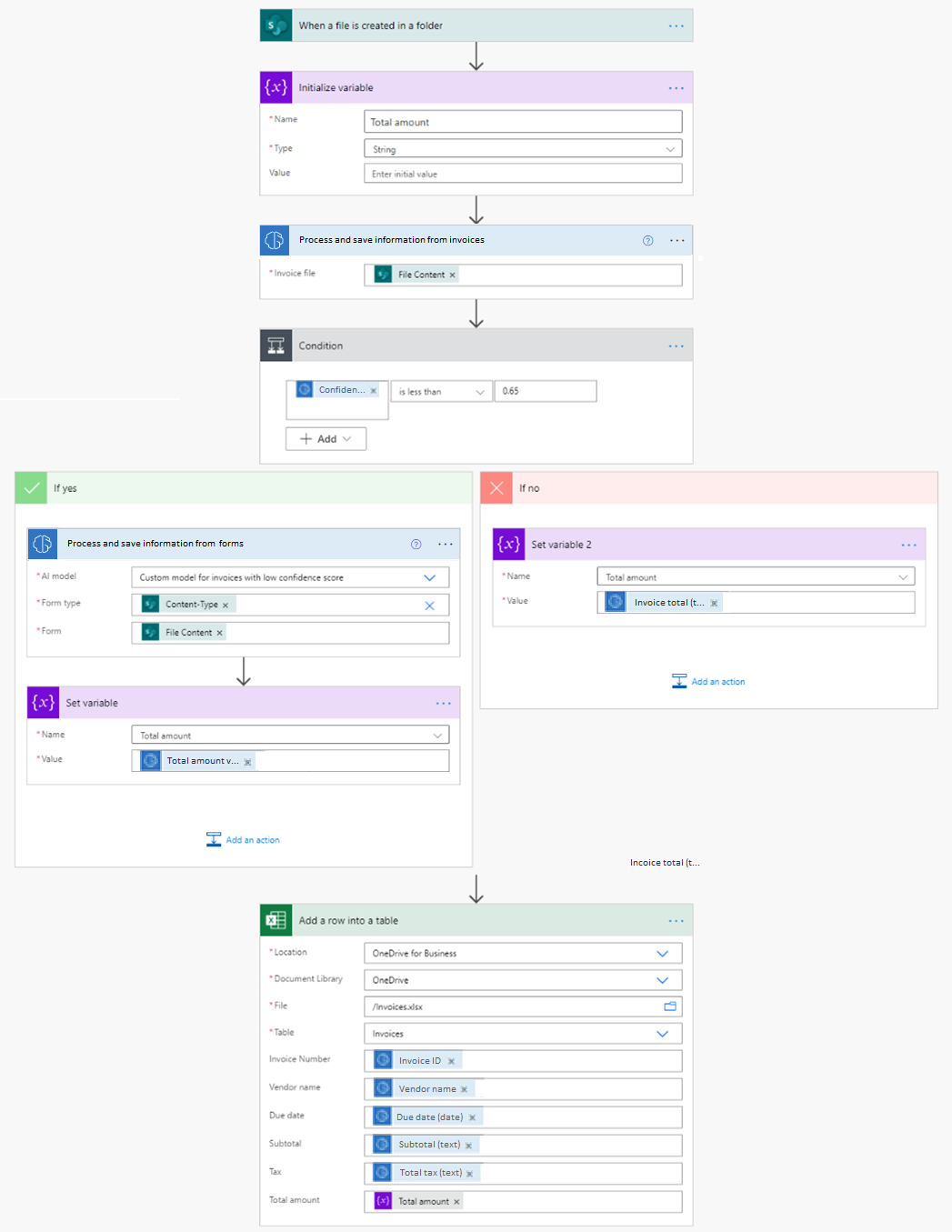
在此示例中,我们训练了一个自定义文档处理模型,来从使用发票处理预生成模型时通常会得到低置信度分数的发票中提取总金额。
流在新账单被添加到 SharePoint 文件夹时触发。 然后,它调用账单处理预生成 AI 模型来提取数据。 接下来,我们检查发票总值属性的置信度分数是否小于 0.65。 如果是这种情况,当整个字段通常会获得较低的置信度分数时,我们会调用一个已经使用发票训练过的自定义文档处理模型。 最后,我们将从账单提取的数据保存到 Excel 文件中。
使用发票处理预生成模型来处理尚未培训自定义文档处理模型进行处理的发票
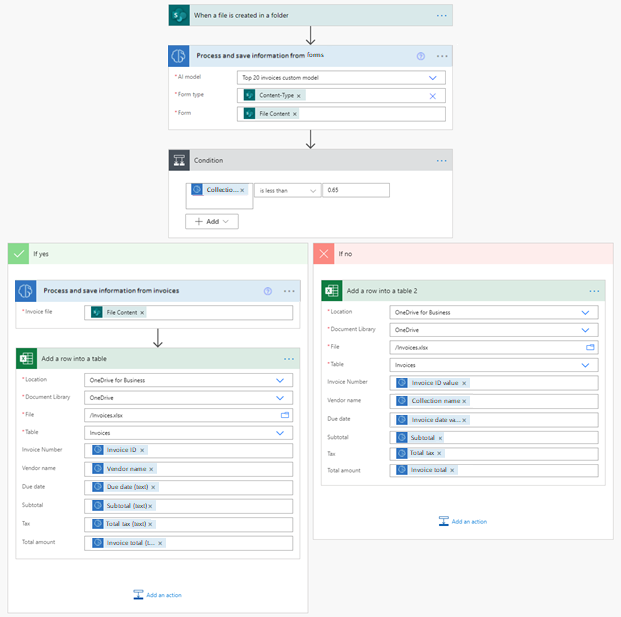
使用发票处理预生成模型的一种方法是将其用作备用模型来处理您尚未在自定义文档处理模型中训练的发票。 例如,假设您构建了一个文档处理模型,并对其进行了训练来从您的前 20 个发票提供商中提取数据。 然后,您可以使用账单处理预生成模型来处理所有新账单或小批量账单。 以下是您如何处理的示例:
此流在新账单被添加到 SharePoint 文件夹时触发。 然后,它将调用自定义文档处理模型来提取其数据。 接下来,我们检查检测到的集合的置信度分数是否小于 0.65。 如果是,可能意味着提供的发票与自定义模型不太匹配。 然后我们调用预生成的发票处理模型。 最后,我们将从账单提取的数据保存在 Excel 文件中。