วิธีการ: เข้าถึงข้อมูล Azure Cosmos DB ที่มิเรอร์ใน Lakehouse และสมุดบันทึกจาก Microsoft Fabric (ตัวอย่าง)
ในคู่มือนี้ คุณจะได้เรียนรู้วิธีการเข้าถึงข้อมูล Azure Cosmos DB ที่มิเรอร์ใน Lakehouse และสมุดบันทึกจาก Microsoft Fabric (ตัวอย่าง)
สำคัญ
มิเรอร์สําหรับ Azure Cosmos DB ในขณะนี้อยู่ในตัวอย่าง ปริมาณงานการผลิตไม่ได้รับการสนับสนุนในระหว่างการแสดงตัวอย่าง ในปัจจุบัน รองรับเฉพาะ Azure Cosmos DB สําหรับบัญชี NoSQL เท่านั้น
ข้อกำหนดเบื้องต้น
- Azure Cosmos DB ที่มีอยู่สําหรับบัญชี NoSQL
- ถ้าคุณไม่มีการสมัครใช้งาน Azure ลองใช้ Azure Cosmos DB สําหรับ NoSQL ฟรี
- ถ้าคุณมีการสมัครใช้งาน Azure อยู่ ให้ สร้าง Azure Cosmos DB ใหม่สําหรับบัญชี NoSQL
- ความจุ Fabric ที่มีอยู่ ถ้าคุณไม่มีความจุที่มีอยู่ ให้ เริ่มการทดลองใช้ Fabric
- Azure Cosmos DB สําหรับบัญชี NoSQL ต้องได้รับการกําหนดค่าสําหรับการมิเรอร์ Fabric สําหรับข้อมูลเพิ่มเติม ดู ข้อกําหนดของบัญชี
เคล็ดลับ
ในระหว่างการแสดงตัวอย่างสาธารณะ ขอแนะนําให้ใช้สําเนาการทดสอบหรือการพัฒนาของข้อมูล Azure Cosmos DB ที่มีอยู่ของคุณที่สามารถกู้คืนได้อย่างรวดเร็วจากการสํารองข้อมูล
ตั้งค่าการมิเรอร์และสิ่งที่จําเป็นต้องมี
กําหนดค่าการมิเรอร์สําหรับ Azure Cosmos DB สําหรับฐานข้อมูล NoSQL ถ้าคุณไม่แน่ใจเกี่ยวกับวิธีการกําหนดค่ามิเรอร์ ดูที่ บทช่วยสอนกําหนดค่าฐานข้อมูลที่มิเรอร์
นําทางไปยัง พอร์ทัล Fabric
สร้างการเชื่อมต่อใหม่และฐานข้อมูลที่มิเรอร์โดยใช้ข้อมูลประจําตัวของบัญชี Azure Cosmos DB ของคุณ
รอให้การจําลองแบบเสร็จสิ้นสแนปช็อตเริ่มต้นของข้อมูล
เข้าถึงข้อมูลมิเรอร์ในเลคเฮ้าส์และสมุดบันทึก
ใช้ Lakehouse เพื่อขยายจํานวนเครื่องมือที่คุณสามารถใช้ในการวิเคราะห์ Azure Cosmos DB ของคุณสําหรับข้อมูลมิเรอร์ NoSQL ที่นี่ คุณใช้ Lakehouse เพื่อสร้างสมุดบันทึก Spark เพื่อคิวรีข้อมูลของคุณ
นําทางไปยังหน้าแรกของพอร์ทัล Fabric อีกครั้ง
ในเมนูนำทาง ให้เลือก สร้าง
เลือก สร้าง ค้นหาส่วน วิศวกรข้อมูล ing จากนั้นเลือก เลคเฮ้าส์
ใส่ชื่อสําหรับเลคเฮ้าส์ จากนั้นเลือก สร้าง
ตอนนี้เลือก รับข้อมูล แล้วเลือก ทางลัดใหม่ จากรายการของตัวเลือกทางลัด ให้เลือก Microsoft OneLake
เลือก Azure Cosmos DB สําหรับฐานข้อมูล NoSQL จากรายการของฐานข้อมูลที่มิเรอร์ในพื้นที่ทํางาน Fabric ของคุณ เลือกตารางเพื่อใช้กับเลคเฮ้าส์ เลือก ถัดไป จากนั้นเลือก สร้าง
เปิดเมนูบริบทสําหรับตารางใน Lakehouse แล้วเลือก ใหม่หรือสมุดบันทึกที่มีอยู่
สมุดบันทึกใหม่เปิดขึ้นโดยอัตโนมัติและโหลดกรอบข้อมูลโดยใช้
SELECT LIMIT 1000เรียกใช้คิวรี เช่น
SELECT *การใช้ Sparkdf = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)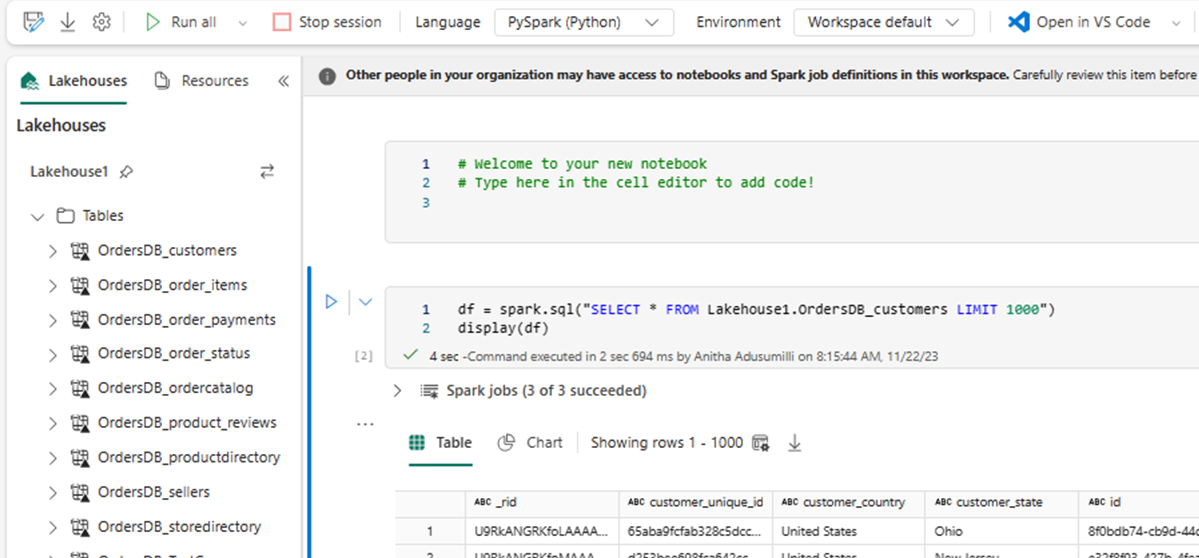
หมายเหตุ
ตัวอย่างนี้ถือว่าชื่อของตารางของคุณ ใช้ตารางของคุณเองเมื่อเขียนคิวรี Spark ของคุณ

เขียนกลับโดยใช้ Spark
ในตอนท้าย คุณสามารถใช้รหัส Spark และ Python เพื่อเขียนข้อมูลกลับไปยังแหล่งที่มาของบัญชี Azure Cosmos DB จากสมุดบันทึกใน Fabric ได้ คุณอาจต้องการทําสิ่งนี้เพื่อเขียนผลลัพธ์การวิเคราะห์กลับไปยัง Cosmos DB ซึ่งสามารถใช้เป็นการให้บริการเครื่องบินสําหรับแอปพลิเคชัน OLTP
สร้างเซลล์รหัสสี่เซลล์ภายในสมุดบันทึกของคุณ
ก่อนอื่น คิวรีข้อมูลแบบมิเรอร์ของคุณ
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")เคล็ดลับ
ชื่อตารางในบล็อกโค้ดตัวอย่างเหล่านี้ถือว่าเป็นเค้าร่างข้อมูลบางอย่าง คุณสามารถแทนที่สิ่งนี้ด้วยชื่อตารางและคอลัมน์ของคุณเองได้
ในตอนนี้ แปลงและรวมข้อมูล
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))ถัดไป กําหนดค่า Spark เพื่อเขียนกลับไปยัง Azure Cosmos DB ของคุณสําหรับบัญชี NoSQL โดยใช้ข้อมูลประจําตัว ชื่อฐานข้อมูล และชื่อคอนเทนเนอร์ของคุณ
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }สุดท้าย ให้ใช้ Spark เพื่อเขียนกลับไปยังฐานข้อมูลต้นฉบับ
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()เรียกใช้เซลล์โค้ดทั้งหมด
สำคัญ
เขียนการดําเนินการกับ Azure Cosmos DB จะใช้หน่วยคําขอ (RUs)