บทช่วยสอนสําหรับ Lakehouse: เตรียมและแปลงข้อมูลในเลคเฮ้าส์
ในบทช่วยสอนนี้ คุณจะใช้โน้ตบุ๊กที่มี รันไทม์ Spark เพื่อแปลงและเตรียมข้อมูลดิบในเลคเฮ้าส์ของคุณ
ข้อกำหนดเบื้องต้น
หากคุณไม่มีเลคเฮ้าส์ที่มีข้อมูล คุณต้อง:
เตรียมข้อมูล
จากขั้นตอนการสอนก่อนหน้านี้ เรามีข้อมูลดิบนําเข้าจากแหล่งข้อมูลไปยัง ส่วนไฟล์ ของ lakehouse ในตอนนี้ คุณสามารถแปลงข้อมูลนั้นและเตรียมข้อมูลสําหรับการสร้างตาราง Delta ได้
ดาวน์โหลดสมุดบันทึกจากโฟลเดอร์โค้ดต้นฉบับของบทช่วยสอนของ Lakehouse
จากพื้นที่ทํางาน ให้เลือก นําเข้า>>สมุดบันทึกจากคอมพิวเตอร์เครื่องนี้
เลือก นําเข้าสมุดบันทึก จาก ส่วน ใหม่ ที่ด้านบนของหน้าเริ่มต้น
เลือก อัปโหลด จากบานหน้าต่าง สถานะ การนําเข้า ที่เปิดอยู่ทางด้านขวาของหน้าจอ
เลือกสมุดบันทึกทั้งหมดที่คุณดาวน์โหลดในขั้นตอนแรกของส่วนนี้
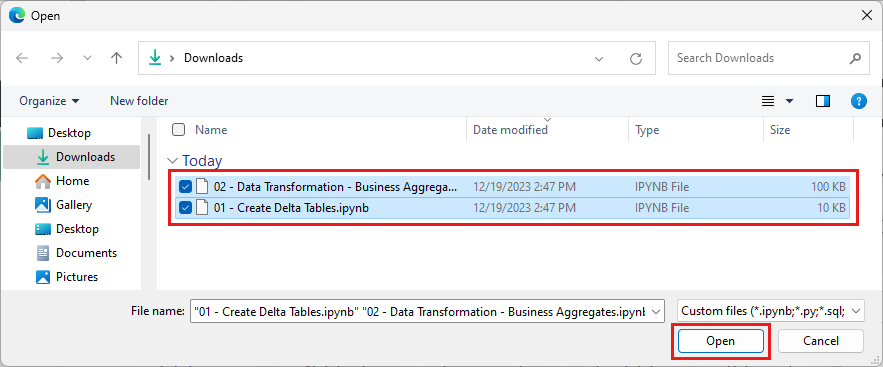
เลือก เปิด การแจ้งเตือนที่ระบุสถานะของการนําเข้าจะปรากฏที่มุมบนขวาของหน้าต่างเบราว์เซอร์
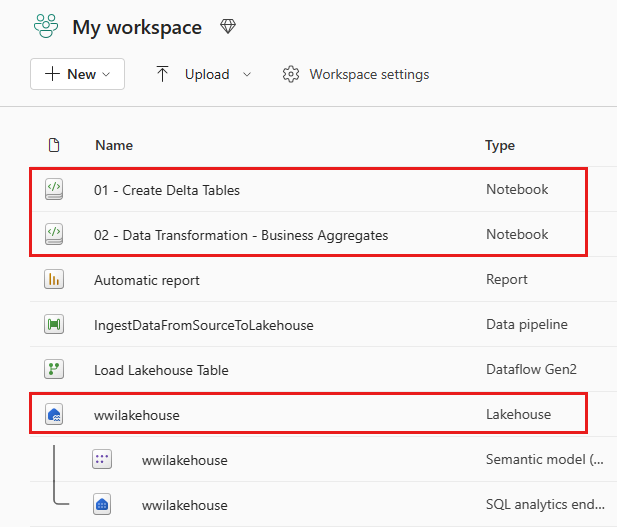
หลังจากการนําเข้าเสร็จสมบูรณ์ ให้ไปที่มุมมองรายการของพื้นที่ทํางานและดูสมุดบันทึกที่นําเข้าใหม่ เลือก wwilakehouse lakehouse เพื่อเปิดห้อง
เมื่อเปิดเลคเฮ้าส์ wwilakehouse แล้ว ให้เลือก เปิดสมุดบันทึก>ที่มีอยู่ จากเมนูการนําทางด้านบน
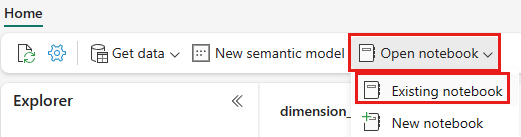
จากรายการของสมุดบันทึกที่มีอยู่ เลือก 01 - สร้างสมุดบันทึกตาราง Delta และเลือกเปิด
ในสมุดบันทึกที่เปิดอยู่ใน lakehouse Explorer คุณจะเห็นสมุดบันทึกถูกลิงก์กับเลคเฮ้าส์ที่เปิดอยู่ของคุณอยู่แล้ว
หมายเหตุ
Fabric ให้ ความสามารถในการสั่งซื้อ V ในการเขียนไฟล์ Delta lake ที่ปรับให้เหมาะสมแล้ว การสั่งซื้อ V มักจะปรับปรุงการบีบอัดโดยสามถึงสี่ครั้ง และถึง 10 ครั้ง การเร่งประสิทธิภาพการทํางานผ่านไฟล์ Delta Lake ที่ไม่ได้ปรับให้เหมาะสม Spark ใน Fabric จะปรับพาร์ติชันให้เหมาะสมในขณะที่สร้างไฟล์ที่มีขนาดเริ่มต้น 128 MB ขนาดไฟล์เป้าหมายอาจเปลี่ยนแปลงได้ตามข้อกําหนดของปริมาณงานโดยใช้การกําหนดค่า
ด้วยความสามารถในการเขียนที่ดีที่สุด กลไก Apache Spark จะลดจํานวนไฟล์ที่เขียนและมีจุดมุ่งหมายเพื่อเพิ่มขนาดไฟล์ของข้อมูลที่เขียนแต่ละไฟล์
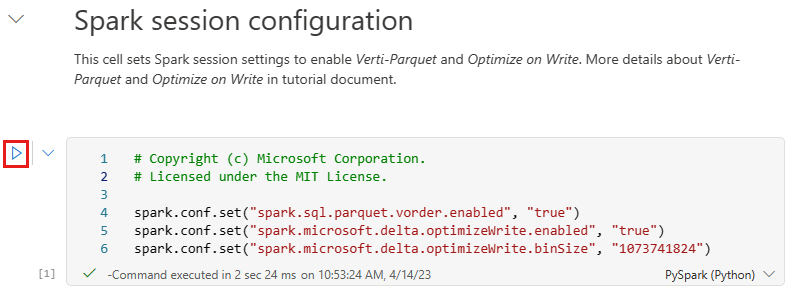
ก่อนที่คุณจะเขียนข้อมูลเป็นตารางทะเลสาบ Delta ในส่วน ตาราง ของ lakehouse คุณใช้คุณลักษณะ Fabric สองอย่าง (V-order และ Optimize Write) เพื่อการเขียนข้อมูลที่เหมาะสมที่สุดและเพื่อประสิทธิภาพการอ่านที่ดีขึ้น เมื่อต้องการเปิดใช้งานคุณลักษณะเหล่านี้ในเซสชันของคุณ ให้ตั้งค่าการกําหนดค่าเหล่านี้ในเซลล์แรกของสมุดบันทึกของคุณ
เมื่อต้องการเริ่มสมุดบันทึกและดําเนินการเซลล์ทั้งหมดตามลําดับ ให้เลือก เรียกใช้ทั้งหมด บนริบบอนด้านบนสุด (ภายใต้ หน้าแรก) หรือเมื่อต้องการเรียกใช้โค้ดจากเซลล์ที่ระบุเท่านั้น ให้เลือก ไอคอน เรียกใช้ ที่ปรากฏทางด้านซ้ายของเซลล์เมื่อวางเมาส์หรือกด SHIFT + ENTER บนแป้นพิมพ์ขณะที่ตัวควบคุมอยู่ในเซลล์
เมื่อเรียกใช้เซลล์ คุณไม่จําเป็นต้องระบุรายละเอียดของพูล Spark หรือคลัสเตอร์ต้นแบบ เนื่องจาก Fabric ให้พวกเขาผ่าน Live Pool พื้นที่ทํางาน Fabric ทุกแห่งมาพร้อมกับพูล Spark ค่าเริ่มต้นที่เรียกว่า Live Pool ซึ่งหมายความว่าเมื่อคุณสร้างสมุดบันทึก คุณไม่ต้องกังวลเกี่ยวกับการระบุรายละเอียดการกําหนดค่า Spark หรือคลัสเตอร์ใดๆ เมื่อคุณเรียกใช้คําสั่งสมุดบันทึกแรก พูลสดจะเริ่มต้น และทํางานในไม่กี่วินาที และเซสชัน Spark ถูกสร้างขึ้นและจะเริ่มดําเนินการโค้ด การดําเนินการโค้ดที่ตามมาเกือบจะเกิดขึ้นทันทีในสมุดบันทึกนี้ในขณะที่เซสชัน Spark ทํางานอยู่
ถัดไป คุณอ่านข้อมูลดิบจากส่วน ไฟล์ ของเลคเฮ้าส์ และเพิ่มคอลัมน์เพิ่มเติมสําหรับส่วนวันที่ที่แตกต่างกันซึ่งเป็นส่วนหนึ่งของการแปลงข้อมูล ในตอนท้าย คุณใช้พาร์ติชัน โดย Spark API เพื่อแบ่งพาร์ติชันข้อมูลก่อนที่จะเขียนเป็นรูปแบบตาราง Delta ตามคอลัมน์ส่วนข้อมูลที่สร้างขึ้นใหม่ (ปี และ ไตรมาส)
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)หลังจากโหลดตารางข้อเท็จจริงแล้ว คุณสามารถไปยังการโหลดข้อมูลสําหรับมิติที่เหลือได้ เซลล์ต่อไปนี้สร้างฟังก์ชันเพื่ออ่านข้อมูลดิบจาก ส่วนไฟล์ ของ lakehouse สําหรับชื่อตารางแต่ละชื่อที่ส่งผ่านเป็นพารามิเตอร์ ถัดไป จะสร้างรายการของตารางมิติ สุดท้าย จะวนรอบผ่านรายการของตารางและสร้างตาราง Delta สําหรับแต่ละชื่อตารางที่อ่านจากพารามิเตอร์การป้อนข้อมูล โปรดทราบว่าสคริปต์จะปล่อยคอลัมน์ที่ชื่อว่า
Photoในตัวอย่างนี้เนื่องจากไม่ได้ใช้คอลัมน์from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)หากต้องการตรวจสอบตารางที่สร้างขึ้น ให้คลิกขวาและเลือกรีเฟรชในเลคเฮาส์ wwilakehouse ตารางจะปรากฏขึ้น
ลองไปยังมุมมองรายการของพื้นที่ทํางานอีกครั้งและเลือก โรงบึง Wwilakehouse เพื่อเปิดห้อง
ตอนนี้ เปิดสมุดบันทึกที่สอง ในมุมมอง lakehouse เลือกเปิดสมุดบันทึก>ที่มีอยู่จาก ribbon
จากรายการของสมุดบันทึกที่มีอยู่ ให้เลือก 02 - การแปลงข้อมูล - สมุดบันทึกธุรกิจ เพื่อเปิด
ในสมุดบันทึกที่เปิดอยู่ใน lakehouse Explorer คุณจะเห็นสมุดบันทึกถูกลิงก์กับเลคเฮ้าส์ที่เปิดอยู่ของคุณอยู่แล้ว
องค์กรอาจมีวิศวกรข้อมูลที่ทํางานกับ Scala/Python และวิศวกรข้อมูลอื่น ๆ ที่ทํางานกับ SQL (Spark SQL หรือ T-SQL) ทั้งหมดที่ทํางานบนสําเนาเดียวกันของข้อมูล ผ้าทําให้เป็นไปได้สําหรับกลุ่มที่แตกต่างกันเหล่านี้ด้วยประสบการณ์และความชอบที่แตกต่างกันในการทํางานและทํางานร่วมกัน สองวิธีการที่แตกต่างกันจะแปลงและสร้างผลรวมทางธุรกิจ คุณสามารถเลือกอันที่เหมาะสมสําหรับคุณหรือผสมและจับคู่วิธีการเหล่านี้ขึ้นอยู่กับการกําหนดลักษณะของคุณโดยไม่กระทบต่อประสิทธิภาพการทํางาน:
วิธีการ #1 - ใช้ PySpark เพื่อรวมและรวมข้อมูลสําหรับการสร้างผลรวมทางธุรกิจ วิธีการนี้เป็นการดีกว่าสําหรับบุคคลที่มีการเขียนโปรแกรม (Python หรือ PySpark) พื้นหลัง
วิธีการ #2 - ใช้ Spark SQL เพื่อรวมและรวมข้อมูลสําหรับการสร้างการรวมทางธุรกิจ วิธีการนี้จะดีกว่าสําหรับบุคคลที่มีพื้นหลัง SQL และเปลี่ยนเป็น Spark
วิธีการ #1 (sale_by_date_city) - ใช้ PySpark เพื่อรวมและรวมข้อมูลสําหรับการสร้างการรวมธุรกิจ ด้วยโค้ดต่อไปนี้ คุณสามารถสร้างกรอบข้อมูล Spark สามแบบ ซึ่งแต่ละกรอบอ้างอิงตาราง Delta ที่มีอยู่ จากนั้นคุณรวมตารางเหล่านี้โดยใช้ dataframes ทําจัดกลุ่มตาม เพื่อสร้างการรวม เปลี่ยนชื่อสองสามคอลัมน์ และสุดท้ายเขียนเป็นตาราง Delta ในส่วน ตาราง ของเลคเฮ้าส์เพื่อคงอยู่กับข้อมูล
ในเซลล์นี้ คุณสร้างกรอบข้อมูล Spark สามรายการ โดยแต่ละกรอบอ้างอิงตาราง Delta ที่มีอยู่
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")เพิ่มโค้ดต่อไปนี้ไปยังเซลล์เดียวกันเพื่อรวมตารางเหล่านี้โดยใช้ dataframes ที่สร้างขึ้นก่อนหน้านี้ จัดกลุ่มตาม เพื่อสร้างการรวม เปลี่ยนชื่อสองสามคอลัมน์ และเขียนเป็นตาราง Delta ในส่วน ตาราง ของเลคเฮ้าส์
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")วิธีการ #2 (sale_by_date_employee) - ใช้ Spark SQL เพื่อรวมและรวมข้อมูลสําหรับการสร้างการรวมทางธุรกิจ ด้วยโค้ดต่อไปนี้ คุณสามารถสร้างมุมมอง Spark ชั่วคราวโดยการรวมตารางสามตาราง ทํากลุ่มตาม เพื่อสร้างการรวม และเปลี่ยนชื่อสองสามคอลัมน์ สุดท้าย คุณอ่านจากมุมมอง Spark ชั่วคราวและเขียนเป็นตาราง Delta ในส่วน ตาราง ของ lakehouse เพื่อคงอยู่กับข้อมูล
ในเซลล์นี้ คุณจะสร้างมุมมอง Spark ชั่วคราวโดยการรวมสามตาราง ทําจัดกลุ่มตาม เพื่อสร้างการรวม และเปลี่ยนชื่อคอลัมน์สองถึงสามคอลัมน์
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCในเซลล์นี้ คุณอ่านจากมุมมอง Spark ชั่วคราวที่สร้างขึ้นในเซลล์ก่อนหน้า และเขียนเป็นตาราง Delta ในส่วน ตาราง ของเลคเฮ้าส์
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")หากต้องการตรวจสอบตารางที่สร้างขึ้น ให้คลิกขวาและเลือก รีเฟรช ในเลคเฮ้าส์ wwilakehouse ตารางรวมปรากฏขึ้น
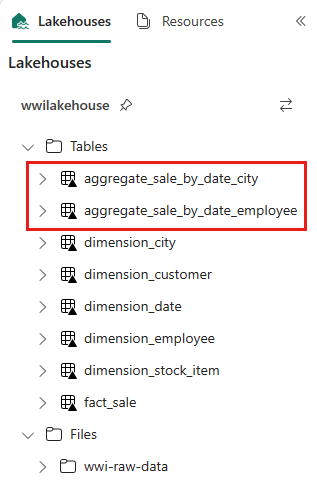
ทั้งสองวิธีสร้างผลลัพธ์ที่คล้ายกัน เพื่อลดความจําเป็นสําหรับคุณในการเรียนรู้เทคโนโลยีใหม่หรือลดประสิทธิภาพการทํางาน ให้เลือกวิธีการที่เหมาะสมกับพื้นหลังและความชอบของคุณมากที่สุด
คุณอาจสังเกตเห็นว่า คุณกําลังเขียนข้อมูลเป็นไฟล์ Delta lake การค้นพบตารางอัตโนมัติและคุณสมบัติการลงทะเบียนของ Fabric รับและลงทะเบียนในเมตาสโตร์ คุณไม่จําเป็นต้องเรียก CREATE TABLE คําสั่งอย่างชัดเจนเพื่อสร้างตารางเพื่อใช้กับ SQL