Copy data from Teradata Vantage using Azure Data Factory and Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use the copy activity in Azure Data Factory and Synapse Analytics pipelines to copy data from Teradata Vantage. It builds on the copy activity overview.
Supported capabilities
This Teradata connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
For a list of data stores that are supported as sources/sinks by the copy activity, see the Supported data stores table.
Specifically, this Teradata connector supports:
- Teradata version 14.10, 15.0, 15.10, 16.0, 16.10, and 16.20.
- Copying data by using Basic, Windows, or LDAP authentication.
- Parallel copying from a Teradata source. See the Parallel copy from Teradata section for details.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allow list.
You can also use the managed virtual network integration runtime feature in Azure Data Factory to access the on-premises network without installing and configuring a self-hosted integration runtime.
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
If you use Self-hosted Integration Runtime, note it provides a built-in Teradata driver starting from version 3.18. You don't need to manually install any driver. The driver requires "Visual C++ Redistributable 2012 Update 4" on the self-hosted integration runtime machine. If you don't yet have it installed, download it from here.
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service to Teradata using UI
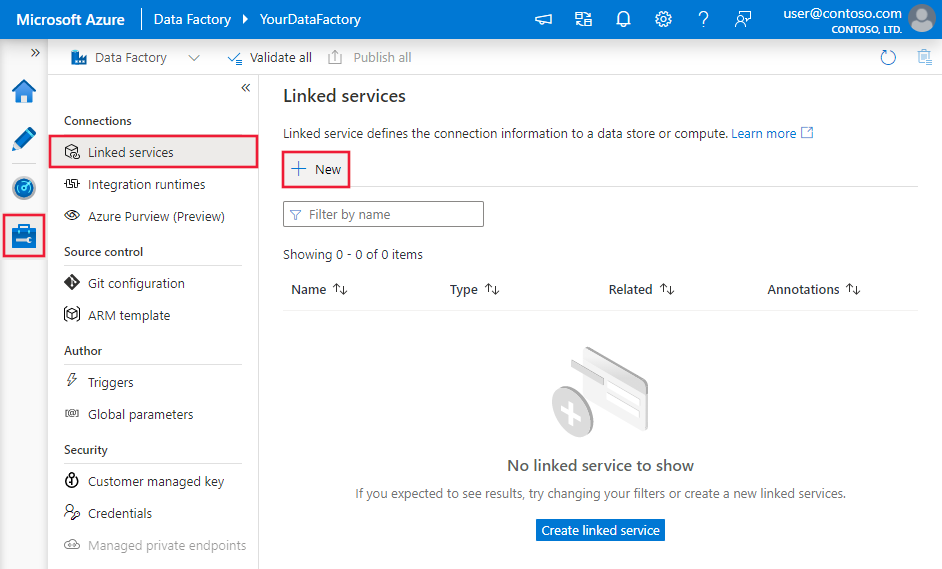
Use the following steps to create a linked service to Teradata in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for Teradata and select the Teradata connector.
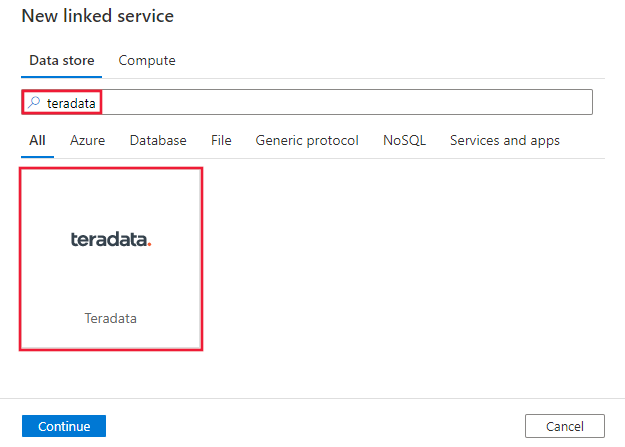
Configure the service details, test the connection, and create the new linked service.
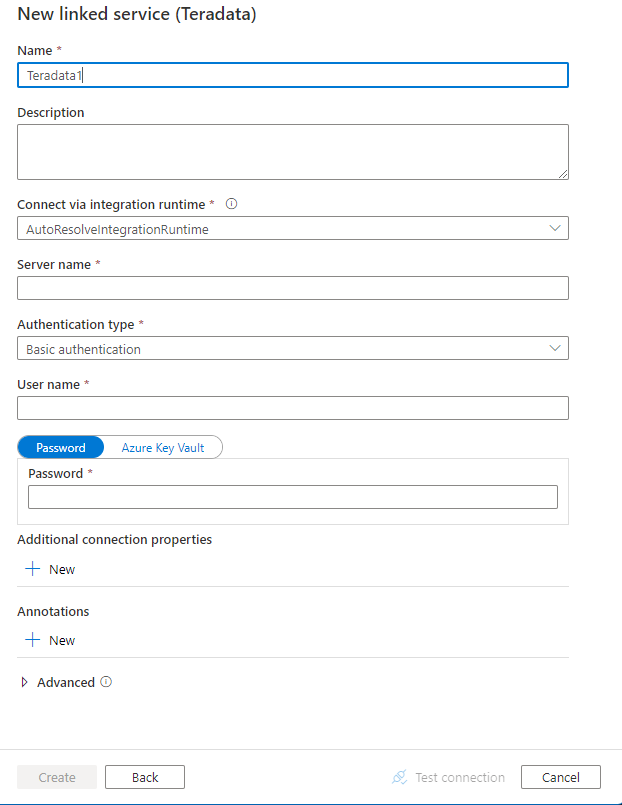
Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to the Teradata connector.
Linked service properties
The Teradata linked service supports the following properties:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to Teradata. | Yes |
| connectionString | Specifies the information needed to connect to the Teradata instance. Refer to the following samples. You can also put a password in Azure Key Vault, and pull the password configuration out of the connection string. Refer to Store credentials in Azure Key Vault with more details. |
Yes |
| username | Specify a user name to connect to Teradata. Applies when you are using Windows authentication. | No |
| password | Specify a password for the user account you specified for the user name. You can also choose to reference a secret stored in Azure Key Vault. Applies when you are using Windows authentication, or referencing a password in Key Vault for basic authentication. |
No |
| connectVia | The Integration Runtime to be used to connect to the data store. Learn more from Prerequisites section. If not specified, it uses the default Azure Integration Runtime. | No |
More connection properties you can set in connection string per your case:
| Property | Description | Default value |
|---|---|---|
| TdmstPortNumber | The number of the port used to access Teradata database. Do not change this value unless instructed to do so by Technical Support. |
1025 |
| UseDataEncryption | Specifies whether to encrypt all communication with the Teradata database. Allowed values are 0 or 1. - 0 (disabled, default): Encrypts authentication information only. - 1 (enabled): Encrypts all data that is passed between the driver and the database. |
0 |
| CharacterSet | The character set to use for the session. E.g., CharacterSet=UTF16.This value can be a user-defined character set, or one of the following pre-defined character sets: - ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows, DOS compatible, KANJISJIS_0S) - EUC (Unix compatible, KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | The maximum size of the response buffer for SQL requests, in kilobytes (KBs). E.g., MaxRespSize=10485760.For Teradata Database version 16.00 or later, the maximum value is 7361536. For connections that use earlier versions, the maximum value is 1048576. |
65536 |
| MechanismName | To use the LDAP protocol to authenticate the connection, specify MechanismName=LDAP. |
N/A |
Example using basic authentication
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example using Windows authentication
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example using LDAP authentication
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Note
The following payload is still supported. Going forward, however, you should use the new one.
Previous payload:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
This section provides a list of properties supported by the Teradata dataset. For a full list of sections and properties available for defining datasets, see Datasets.
To copy data from Teradata, the following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to TeradataTable. |
Yes |
| database | The name of the Teradata instance. | No (if "query" in activity source is specified) |
| table | The name of the table in the Teradata instance. | No (if "query" in activity source is specified) |
Example:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Note
RelationalTable type dataset is still supported. However, we recommend that you use the new dataset.
Previous payload:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Copy activity properties
This section provides a list of properties supported by Teradata source. For a full list of sections and properties available for defining activities, see Pipelines.
Teradata as source
Tip
To load data from Teradata efficiently by using data partitioning, learn more from Parallel copy from Teradata section.
To copy data from Teradata, the following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to TeradataSource. |
Yes |
| query | Use the custom SQL query to read data. An example is "SELECT * FROM MyTable".When you enable partitioned load, you need to hook any corresponding built-in partition parameters in your query. For examples, see the Parallel copy from Teradata section. |
No (if table in dataset is specified) |
| partitionOptions | Specifies the data partitioning options used to load data from Teradata. Allow values are: None (default), Hash and DynamicRange. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from Teradata is controlled by the parallelCopies setting on the copy activity. |
No |
| partitionSettings | Specify the group of the settings for data partitioning. Apply when partition option isn't None. |
No |
| partitionColumnName | Specify the name of the source column that will be used by range partition or Hash partition for parallel copy. If not specified, the primary index of the table is autodetected and used as the partition column. Apply when the partition option is Hash or DynamicRange. If you use a query to retrieve the source data, hook ?AdfHashPartitionCondition or ?AdfRangePartitionColumnName in WHERE clause. See example in Parallel copy from Teradata section. |
No |
| partitionUpperBound | The maximum value of the partition column to copy data out. Apply when partition option is DynamicRange. If you use query to retrieve source data, hook ?AdfRangePartitionUpbound in the WHERE clause. For an example, see the Parallel copy from Teradata section. |
No |
| partitionLowerBound | The minimum value of the partition column to copy data out. Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?AdfRangePartitionLowbound in the WHERE clause. For an example, see the Parallel copy from Teradata section. |
No |
Note
RelationalSource type copy source is still supported, but it doesn't support the new built-in parallel load from Teradata (partition options). However, we recommend that you use the new dataset.
Example: copy data by using a basic query without partition
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Parallel copy from Teradata
The Teradata connector provides built-in data partitioning to copy data from Teradata in parallel. You can find data partitioning options on the Source table of the copy activity.

When you enable partitioned copy, the service runs parallel queries against your Teradata source to load data by partitions. The parallel degree is controlled by the parallelCopies setting on the copy activity. For example, if you set parallelCopies to four, the service concurrently generates and runs four queries based on your specified partition option and settings, and each query retrieves a portion of data from your Teradata.
You are suggested to enable parallel copy with data partitioning especially when you load large amount of data from your Teradata. The following are suggested configurations for different scenarios. When copying data into file-based data store, it's recommended to write to a folder as multiple files (only specify folder name), in which case the performance is better than writing to a single file.
| Scenario | Suggested settings |
|---|---|
| Full load from large table. | Partition option: Hash. During execution, the service automatically detects the primary index column, applies a hash against it, and copies data by partitions. |
| Load large amount of data by using a custom query. | Partition option: Hash. Query: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Partition column: Specify the column used for apply hash partition. If not specified, the service automatically detects the PK column of the table you specified in the Teradata dataset. During execution, the service replaces ?AdfHashPartitionCondition with the hash partition logic, and sends to Teradata. |
| Load large amount of data by using a custom query, having an integer column with evenly distributed value for range partitioning. | Partition options: Dynamic range partition. Query: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partition column: Specify the column used to partition data. You can partition against the column with integer data type. Partition upper bound and partition lower bound: Specify if you want to filter against the partition column to retrieve data only between the lower and upper range. During execution, the service replaces ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound, and ?AdfRangePartitionLowbound with the actual column name and value ranges for each partition, and sends to Teradata. For example, if your partition column "ID" set with the lower bound as 1 and the upper bound as 80, with parallel copy set as 4, the service retrieves data by 4 partitions. Their IDs are between [1,20], [21, 40], [41, 60], and [61, 80], respectively. |
Example: query with hash partition
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Example: query with dynamic range partition
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Data type mapping for Teradata
When you copy data from Teradata, the following mappings apply from Teradata's data types to the internal data types used by the service. To learn about how the copy activity maps the source schema and data type to the sink, see Schema and data type mappings.
| Teradata data type | Interim service data type |
|---|---|
| BigInt | Int64 |
| Blob | Byte[] |
| Byte | Byte[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | DateTime |
| Decimal | Decimal |
| Double | Double |
| Graphic | Not supported. Apply explicit cast in source query. |
| Integer | Int32 |
| Interval Day | Not supported. Apply explicit cast in source query. |
| Interval Day To Hour | Not supported. Apply explicit cast in source query. |
| Interval Day To Minute | Not supported. Apply explicit cast in source query. |
| Interval Day To Second | Not supported. Apply explicit cast in source query. |
| Interval Hour | Not supported. Apply explicit cast in source query. |
| Interval Hour To Minute | Not supported. Apply explicit cast in source query. |
| Interval Hour To Second | Not supported. Apply explicit cast in source query. |
| Interval Minute | Not supported. Apply explicit cast in source query. |
| Interval Minute To Second | Not supported. Apply explicit cast in source query. |
| Interval Month | Not supported. Apply explicit cast in source query. |
| Interval Second | Not supported. Apply explicit cast in source query. |
| Interval Year | Not supported. Apply explicit cast in source query. |
| Interval Year To Month | Not supported. Apply explicit cast in source query. |
| Number | Double |
| Period (Date) | Not supported. Apply explicit cast in source query. |
| Period (Time) | Not supported. Apply explicit cast in source query. |
| Period (Time With Time Zone) | Not supported. Apply explicit cast in source query. |
| Period (Timestamp) | Not supported. Apply explicit cast in source query. |
| Period (Timestamp With Time Zone) | Not supported. Apply explicit cast in source query. |
| SmallInt | Int16 |
| Time | TimeSpan |
| Time With Time Zone | TimeSpan |
| Timestamp | DateTime |
| Timestamp With Time Zone | DateTime |
| VarByte | Byte[] |
| VarChar | String |
| VarGraphic | Not supported. Apply explicit cast in source query. |
| Xml | Not supported. Apply explicit cast in source query. |
Lookup activity properties
To learn details about the properties, check Lookup activity.
Related content
For a list of data stores supported as sources and sinks by the copy activity, see Supported data stores.