Schema and data type mapping in copy activity
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article describes how the Azure Data Factory copy activity performs schema mapping and data type mapping from source data to sink data.
Schema mapping
Default mapping
By default, copy activity maps source data to sink by column names in case-sensitive manner. If sink doesn't exist, for example, writing to file(s), the source field names will be persisted as sink names. If the sink already exists, it must contain all columns being copied from the source. Such default mapping supports flexible schemas and schema drift from source to sink from execution to execution - all the data returned by source data store can be copied to sink.
If your source is text file without header line, explicit mapping is required as the source doesn't contain column names.
Explicit mapping
You can also specify explicit mapping to customize the column/field mapping from source to sink based on your need. With explicit mapping, you can copy only partial source data to sink, or map source data to sink with different names, or reshape tabular/hierarchical data. Copy activity:
- Reads the data from source and determine the source schema.
- Applies your defined mapping.
- Writes the data to sink.
Learn more about:
- Tabular source to tabular sink
- Hierarchical source to tabular sink
- Tabular/Hierarchical source to hierarchical sink
You can configure the mapping on the Authoring UI -> copy activity -> mapping tab, or programmatically specify the mapping in copy activity -> translator property. The following properties are supported in translator -> mappings array -> objects -> source and sink, which points to the specific column/field to map data.
| Property | Description | Required |
|---|---|---|
| name | Name of the source or sink column/field. Apply for tabular source and sink. | Yes |
| ordinal | Column index. Start from 1. Apply and required when using delimited text without header line. |
No |
| path | JSON path expression for each field to extract or map. Apply for hierarchical source and sink, for example, Azure Cosmos DB, MongoDB, or REST connectors. For fields under the root object, the JSON path starts with root $; for fields inside the array chosen by collectionReference property, JSON path starts from the array element without $. |
No |
| type | Interim data type of the source or sink column. In general, you don't need to specify or change this property. Learn more about data type mapping. | No |
| culture | Culture of the source or sink column. Apply when type is Datetime or Datetimeoffset. The default is en-us.In general, you don't need to specify or change this property. Learn more about data type mapping. |
No |
| format | Format string to be used when type is Datetime or Datetimeoffset. Refer to Custom Date and Time Format Strings on how to format datetime. In general, you don't need to specify or change this property. Learn more about data type mapping. |
No |
The following properties are supported under translator in addition to mappings:
| Property | Description | Required |
|---|---|---|
| collectionReference | Apply when copying data from a hierarchical source, such as Azure Cosmos DB, MongoDB, or REST connectors. If you want to iterate and extract data from the objects inside an array field with the same pattern and convert to per row per object, specify the JSON path of that array to do cross-apply. |
No |
Tabular source to tabular sink
For example, to copy data from Salesforce to Azure SQL Database and explicitly map three columns:
On copy activity -> mapping tab, click Import schemas button to import both source and sink schemas.
Map the needed fields and exclude/delete the rest.

The same mapping can be configured as the following in copy activity payload (see translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
To copy data from delimited text file(s) without header line, the columns are represented by ordinal instead of names.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Hierarchical source to tabular sink
When copying data from hierarchical source to tabular sink, copy activity supports the following capabilities:
- Extract data from objects and arrays.
- Cross apply multiple objects with the same pattern from an array, in which case to convert one JSON object into multiple records in tabular result.
For more advanced hierarchical-to-tabular transformation, you can use Data Flow.
For example, if you have source MongoDB document with the following content:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
And you want to copy it into a text file in the following format with header line, by flattening the data inside the array (order_pd and order_price) and cross join with the common root info (number, date, and city):
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
You can define such mapping on Data Factory authoring UI:
On copy activity -> mapping tab, click Import schemas button to import both source and sink schemas. As the service samples the top few objects when importing schema, if any field doesn't show up, you can add it to the correct layer in the hierarchy - hover on an existing field name and choose to add a node, an object, or an array.
Select the array from which you want to iterate and extract data. It will be auto populated as Collection reference. Note only single array is supported for such operation.
Map the needed fields to sink. The service automatically determines the corresponding JSON paths for the hierarchical side.
Note
For records where the array marked as collection reference is empty and the check box is selected, the entire record is skipped.
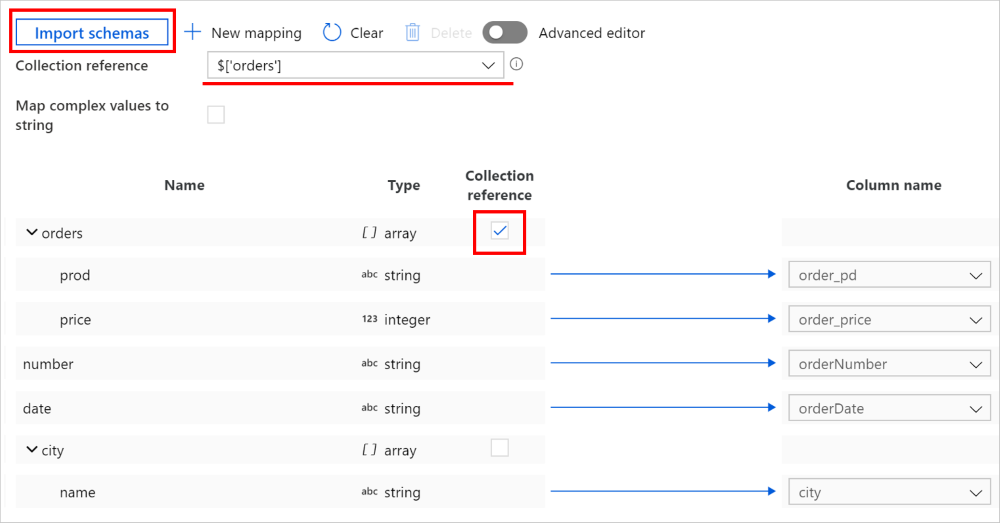
You can also switch to Advanced editor, in which case you can directly see and edit the fields' JSON paths. If you choose to add new mapping in this view, specify the JSON path.
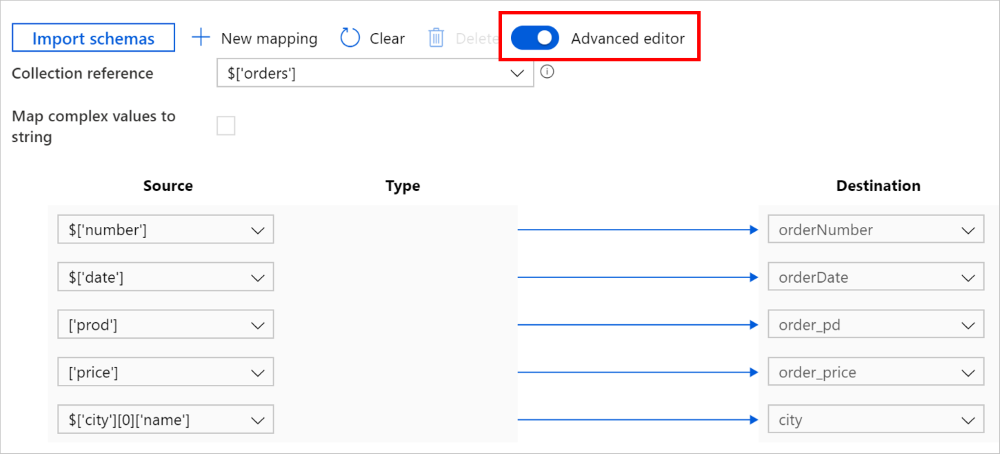
The same mapping can be configured as the following in copy activity payload (see translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Tabular/Hierarchical source to hierarchical sink
The user experience flow is similar to Hierarchical source to tabular sink.
When copying data from tabular source to hierarchical sink, writing to array inside object is not supported.
When copying data from hierarchical source to hierarchical sink, you can additionally preserve entire layer's hierarchy, by selecting the object/array and map to sink without touching the inner fields.
For more advanced data reshape transformation, you can use Data Flow.
Parameterize mapping
If you want to create a templatized pipeline to copy large number of objects dynamically, determine whether you can leverage the default mapping or you need to define explicit mapping for respective objects.
If explicit mapping is needed, you can:
Define a parameter with object type at the pipeline level, for example,
mapping.Parameterize the mapping: on copy activity -> mapping tab, choose to add dynamic content and select the above parameter. The activity payload would be as the following:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Construct the value to pass into the mapping parameter. It should be the entire object of
translatordefinition, refer to the samples in explicit mapping section. For example, for tabular source to tabular sink copy, the value should be{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Data type mapping
Copy activity performs source types to sink types mapping with the following flow:
- Convert from source native data types to interim data types used by Azure Data Factory and Synapse pipelines.
- Automatically convert interim data type as needed to match corresponding sink types, applicable for both default mapping and explicit mapping.
- Convert from interim data types to sink native data types.
Copy activity currently supports the following interim data types: Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32, and UInt64.
The following data type conversions are supported between the interim types from source to sink.
| Source\Sink | Boolean | Byte array | Date/Time | Decimal | Float-point | GUID | Integer | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Byte array | ✓ | ✓ | |||||||
| Date/Time | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Float-point | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Date/Time includes DateTime and DateTimeOffset.
(2) Float-point includes Single and Double.
(3) Integer includes SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, and UInt64.
Note
- Currently such data type conversion is supported when copying between tabular data. Hierarchical sources/sinks are not supported, which means there is no system-defined data type conversion between source and sink interim types.
- This feature works with the latest dataset model. If you don't see this option from the UI, try creating a new dataset.
The following properties are supported in copy activity for data type conversion (under translator section for programmatical authoring):
| Property | Description | Required |
|---|---|---|
| typeConversion | Enable the new data type conversion experience. Default value is false due to backward compatibility. For new copy activities created via Data Factory authoring UI since late June 2020, this data type conversion is enabled by default for the best experience, and you can see the following type conversion settings on copy activity -> mapping tab for applicable scenarios. To create pipeline programmatically, you need to explicitly set typeConversion property to true to enable it.For existing copy activities created before this feature is released, you won't see type conversion options on the authoring UI for backward compatibility. |
No |
| typeConversionSettings | A group of type conversion settings. Apply when typeConversion is set to true. The following properties are all under this group. |
No |
Under typeConversionSettings |
||
| allowDataTruncation | Allow data truncation when converting source data to sink with different type during copy, for example, from decimal to integer, from DatetimeOffset to Datetime. Default value is true. |
No |
| treatBooleanAsNumber | Treat booleans as numbers, for example, true as 1. Default value is false. |
No |
| dateTimeFormat | Format string when converting between dates without time zone offset and strings, for example, yyyy-MM-dd HH:mm:ss.fff. Refer to Custom Date and Time Format Strings for detailed information. |
No |
| dateTimeOffsetFormat | Format string when converting between dates with time zone offset and strings, for example, yyyy-MM-dd HH:mm:ss.fff zzz. Refer to Custom Date and Time Format Strings for detailed information. |
No |
| timeSpanFormat | Format string when converting between time periods and strings, for example, dd\.hh\:mm. Refer to Custom TimeSpan Format Strings for detailed information. |
No |
| culture | Culture information to be used when convert types, for example, en-us or fr-fr. |
No |
Example:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Legacy models
Note
The following models to map source columns/fields to sink are still supported as is for backward compatibility. We suggest that you use the new model mentioned in schema mapping. The authoring UI has switched to generating the new model.
Alternative column-mapping (legacy model)
You can specify copy activity -> translator -> columnMappings to map between tabular-shaped data. In this case, the "structure" section is required for both input and output datasets. Column mapping supports mapping all or subset of columns in the source dataset "structure" to all columns in the sink dataset "structure". The following are error conditions that result in an exception:
- Source data store query result does not have a column name that is specified in the input dataset "structure" section.
- Sink data store (if with pre-defined schema) does not have a column name that is specified in the output dataset "structure" section.
- Either fewer columns or more columns in the "structure" of sink dataset than specified in the mapping.
- Duplicate mapping.
In the following example, the input dataset has a structure, and it points to a table in an on-premises Oracle database.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
In this sample, the output dataset has a structure and it points to a table in Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
The following JSON defines a copy activity in a pipeline. The columns from source mapped to columns in sink by using the translator -> columnMappings property.
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
If you are using the syntax of "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" to specify column mapping, it is still supported as-is.
Alternative schema-mapping (legacy model)
You can specify copy activity -> translator -> schemaMapping to map between hierarchical-shaped data and tabular-shaped data, for example, copy from MongoDB/REST to text file and copy from Oracle to Azure Cosmos DB for MongoDB. The following properties are supported in copy activity translator section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity translator must be set to: TabularTranslator | Yes |
| schemaMapping | A collection of key-value pairs, which represents the mapping relation from source side to sink side. - Key: represents source. For tabular source, specify the column name as defined in dataset structure; for hierarchical source, specify the JSON path expression for each field to extract and map. - Value: represents sink. For tabular sink, specify the column name as defined in dataset structure; for hierarchical sink, specify the JSON path expression for each field to extract and map. In the case of hierarchical data, for fields under root object, JSON path starts with root $; for fields inside the array chosen by collectionReference property, JSON path starts from the array element. |
Yes |
| collectionReference | If you want to iterate and extract data from the objects inside an array field with the same pattern and convert to per row per object, specify the JSON path of that array to do cross-apply. This property is supported only when hierarchical data is source. | No |
Example: copy from MongoDB to Oracle:
For example, if you have MongoDB document with the following content:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
and you want to copy it into an Azure SQL table in the following format, by flattening the data inside the array (order_pd and order_price) and cross join with the common root info (number, date, and city):
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Configure the schema-mapping rule as the following copy activity JSON sample:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Related content
See the other Copy Activity articles: