Vägledning för DirectQuery-modell i Power BI Desktop
Den här artikeln riktar sig till datamodellerare som utvecklar Power BI DirectQuery-modeller som utvecklats med hjälp av antingen Power BI Desktop eller Power BI-tjänst. Den beskriver DirectQuery-användningsfall, begränsningar och vägledning. Mer specifikt är vägledningen utformad för att hjälpa dig att avgöra om DirectQuery är rätt läge för din modell och för att förbättra prestandan för dina rapporter baserat på DirectQuery-modeller. Den här artikeln gäller för DirectQuery-modeller som finns i Power BI-tjänst eller Power BI-rapportserver.
Den här artikeln är inte avsedd att ge en fullständig diskussion om DirectQuery-modelldesign. En introduktion finns i artikeln DirectQuery-modeller i Power BI Desktop . En djupare diskussion finns i white paper om DirectQuery i SQL Server 2016 Analysis Services . Tänk på att vitboken beskriver hur du använder DirectQuery i SQL Server Analysis Services. Mycket av innehållet gäller dock fortfarande för Power BI DirectQuery-modeller.
Kommentar
Överväganden när du använder DirectQuery-lagringsläge för Dataverse finns i Vägledning för Power BI-modellering för Power Platform.
Den här artikeln beskriver inte sammansatta modeller direkt. En sammansatt modell består av minst en DirectQuery-källa och eventuellt fler. Vägledningen som beskrivs i den här artikeln är fortfarande relevant– åtminstone delvis – för sammansatt modelldesign. Konsekvenserna av att kombinera importtabeller med DirectQuery-tabeller finns dock inte i omfånget för den här artikeln. Mer information finns i Använda sammansatta modeller i Power BI Desktop.
Det är viktigt att förstå att DirectQuery-modeller har en annan arbetsbelastning i Power BI-miljön (Power BI-tjänst eller Power BI-rapportserver) och även på underliggande datakällor. Om du anser att DirectQuery är rätt designmetod rekommenderar vi att du engagerar rätt personer i projektet. Vi ser ofta att en lyckad DirectQuery-modelldistribution är resultatet av ett team med IT-proffs som arbetar nära varandra. Teamet består vanligtvis av modellutvecklare och källdatabasadministratörer. Det kan också omfatta dataarkitekter, informationslager och ETL-utvecklare. Ofta måste optimeringar tillämpas direkt på datakällan för att uppnå bra prestandaresultat.
Optimera prestanda för datakällor
Relationsdatabaskällan kan optimeras på flera sätt, enligt beskrivningen i följande punktlista.
Kommentar
Vi förstår att inte alla modellerare har behörighet eller färdigheter för att optimera en relationsdatabas. Även om det är det bästa lagret för att förbereda data för en DirectQuery-modell, kan vissa optimeringar också uppnås i modelldesignen, utan att ändra källdatabasen. Bästa optimeringsresultat uppnås dock ofta genom att optimeringar tillämpas på källdatabasen.
Se till att dataintegriteten är fullständig: Det är särskilt viktigt att tabeller av dimensionstyp innehåller en kolumn med unika värden (dimensionsnyckel) som mappar till tabeller av faktatyp. Det är också viktigt att dimensionskolumner av faktatyp innehåller giltiga dimensionsnyckelvärden. De gör det möjligt att konfigurera effektivare modellrelationer som förväntar sig matchade värden på båda sidor av relationer. När källdata saknar integritet rekommenderar vi att en "okänd" dimensionspost läggs till för att effektivt reparera data. Du kan till exempel lägga till en rad i tabellen Produkt för att representera en okänd produkt och sedan tilldela den en out-of-range-nyckel, till exempel -1. Om raderna i tabellen Försäljning innehåller ett produktnyckelvärde som saknas ersätter du dem med -1. Det säkerställer att varje produktnyckelvärde för Försäljning har en motsvarande rad i tabellen Produkt .
Lägg till index: Definiera lämpliga index – i tabeller eller vyer – för att stödja effektiv hämtning av data för förväntad visuell filtrering och gruppering av rapportobjekt. För SQL Server-, Azure SQL Database- eller Azure Synapse Analytics-källor (tidigare SQL Data Warehouse) kan du läsa arkitektur- och designguiden för SQL Server-index för användbar information om vägledning för indexdesign. Information om flyktiga SQL Server- eller Azure SQL Database-källor finns i Kom igång med Columnstore för driftanalys i realtid.
Designa distribuerade tabeller: För Azure Synapse Analytics-källor (tidigare SQL Data Warehouse), som använder MPP-arkitektur (Massively Parallel Processing), bör du överväga att konfigurera stora tabeller av faktatyp som hash-distribuerade och dimensionstypstabeller som ska replikeras över alla beräkningsnoder. Mer information finns i Vägledning för att utforma distribuerade tabeller i Azure Synapse Analytics (tidigare SQL Data Warehouse).
Se till att nödvändiga datatransformeringar materialiseras: För relationsdatabaskällor i SQL Server (och andra relationsdatabaskällor) kan beräknade kolumner läggas till i tabeller. Dessa kolumner baseras på ett uttryck, till exempel Kvantitet multiplicerat med UnitPrice. Beräknade kolumner kan bevaras (materialiseras) och, som vanliga kolumner, kan de ibland indexeras. Mer information finns i Index för beräknade kolumner.
Överväg även indexerade vyer som kan aggregera faktatabelldata i ett högre intervall. Om tabellen Försäljning till exempel lagrar data på orderradsnivå kan du skapa en vy för att sammanfatta dessa data. Vyn kan baseras på en SELECT-instruktion som grupperar försäljningstabelldata efter datum (på månadsnivå), kund, produkt och sammanfattar måttvärden som försäljning, kvantitet osv. Vyn kan sedan indexeras. Information om SQL Server- eller Azure SQL Database-källor finns i Skapa indexerade vyer.
Materialisera en datumtabell: Ett vanligt modelleringskrav innebär att lägga till en datumtabell för att stödja tidsbaserad filtrering. För att stödja kända tidsbaserade filter i din organisation skapar du en tabell i källdatabasen och ser till att den läses in med ett datumintervall som omfattar faktatabelldatumen. Se också till att den innehåller kolumner för användbara tidsperioder, till exempel år, kvartal, månad, vecka osv.
Optimera modelldesign
En DirectQuery-modell kan optimeras på många sätt, enligt beskrivningen i följande punktlista.
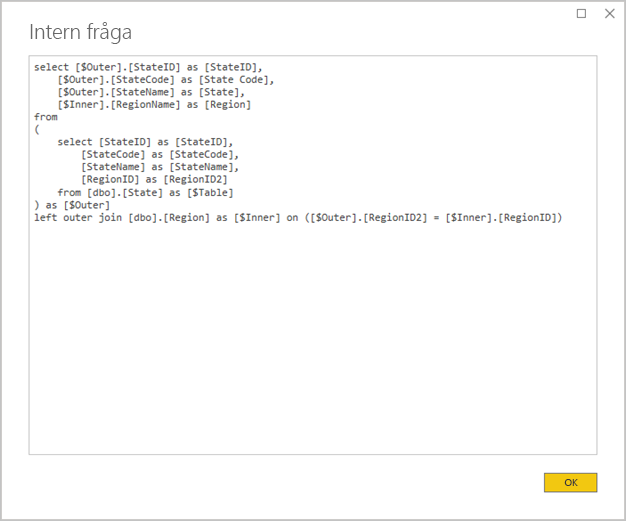
Undvik komplexa Power Query-frågor: En effektiv modelldesign kan uppnås genom att ta bort behovet av att Power Query-frågorna tillämpar transformeringar. Det innebär att varje fråga mappar till en enda relationsdatabass källtabell eller vy. Du kan förhandsgranska en representation av den faktiska SQL-frågesatsen för ett Power Query-tillämpat steg genom att välja alternativet Visa intern fråga .
Granska användningen av beräknade kolumner och datatypsändringar: DirectQuery-modeller har stöd för att lägga till beräkningar och Power Query-steg för att konvertera datatyper. Bättre prestanda uppnås dock ofta genom materialisering av transformeringsresultat i relationsdatabaskällan när det är möjligt.
Använd inte relativ datumfiltrering för Power Query: Det går att definiera relativ datumfiltrering i en Power Query-fråga. Om du till exempel vill hämta till de försäljningsorder som skapades under det senaste året (i förhållande till dagens datum). Den här typen av filter översätts till en ineffektiv intern fråga enligt följande:
… from [dbo].[Sales] as [_] where [_].[OrderDate] >= convert(datetime2, '2018-01-01 00:00:00') and [_].[OrderDate] < convert(datetime2, '2019-01-01 00:00:00'))En bättre designmetod är att inkludera relativa tidskolumner i datumtabellen. Dessa kolumner lagrar förskjutningsvärden i förhållande till det aktuella datumet. I en RelativÅr-kolumn representerar till exempel värdet noll aktuellt år, -1 representerar föregående år osv. Helst materialiseras kolumnen RelativeYear i datumtabellen. Även om det är mindre effektivt kan det också läggas till som en modell beräknad kolumn, baserat på uttrycket med dax-funktionerna TODAY och DATE .
Håll måtten enkla: Åtminstone från början rekommenderar vi att du begränsar måtten till enkla aggregeringar. Aggregerade funktioner är SUM, COUNT, MIN, MAX och AVERAGE. Om måtten sedan är tillräckligt dynamiska kan du experimentera med mer komplexa mått, men vara uppmärksam på prestandan för var och en. Dax-funktionen CALCULATE kan användas för att skapa avancerade måttuttryck som manipulerar filterkontexten, men de kan generera dyra interna frågor som inte fungerar bra.
Undvik relationer med beräknade kolumner: Modellrelationer kan bara relatera en enskild kolumn i en tabell till en enda kolumn i en annan tabell. Ibland är det dock nödvändigt att relatera tabeller med hjälp av flera kolumner. Tabellerna Försäljning och Geografi är till exempel relaterade till två kolumner: CountryRegion och City. För att skapa en relation mellan tabellerna krävs en enda kolumn, och i tabellen Geografi måste kolumnen innehålla unika värden. Att sammanfoga landet/regionen och staden med bindestrecksavgränsare kan uppnå detta resultat.
Den kombinerade kolumnen kan skapas med antingen en anpassad Power Query-kolumn eller i modellen som en beräknad kolumn. Det bör dock undvikas eftersom beräkningsuttrycket bäddas in i källfrågorna. Det är inte bara ineffektivt, det förhindrar ofta användning av index. Lägg i stället till materialiserade kolumner i relationsdatabaskällan och överväg att indexera dem. Du kan också överväga att lägga till surrogatnyckelkolumner i tabeller av dimensionstyp, vilket är vanligt i relationsdatalagerdesign.
Det finns ett undantag till den här vägledningen och det gäller användningen av DAX-funktionen COMBINEVALUES . Syftet med den här funktionen är att stödja modellrelationer med flera kolumner. I stället för att generera ett uttryck som relationen använder genereras ett SQL-kopplingspredikat med flera kolumner.
Undvik relationer i kolumnerna "Unik identifierare": Power BI stöder inte inbyggt datatypen unik identifierare (GUID). När du definierar en relation mellan kolumner av den här typen genererar Power BI en källfråga med en koppling som involverar en rollbesättning. Den här datakonverteringen av frågetid resulterar ofta i dåliga prestanda. Tills det här fallet har optimerats är den enda lösningen att materialisera kolumner av en alternativ datatyp i den underliggande databasen.
Dölj den ensidiga kolumnen med relationer: Kolumnen på ena sidan i en relation ska vara dold. (Det är vanligtvis primärnyckelkolumnen i tabeller av dimensionstyp.) När den är dold är den inte tillgänglig i fönstret Fält och kan därför inte användas för att konfigurera ett visuellt objekt. Kolumnen på många sidor kan förbli synlig om det är användbart att gruppera eller filtrera rapporter efter kolumnvärdena. Tänk dig till exempel en modell där det finns en relation mellan tabellerna Försäljning och Produkt . Relationskolumnerna innehåller produkt-SKU-värden (lagerhållningsenhet). Om produkt-SKU:n måste läggas till i visuella objekt bör den endast visas i tabellen Försäljning . När den här kolumnen används för att filtrera eller gruppera i ett visuellt objekt genererar Power BI en fråga som inte behöver ansluta till tabellerna Försäljning och Produkt .
Ange relationer för att framtvinga integritet: Egenskapen Anta referensintegritet för DirectQuery-relationer avgör om Power BI genererar källfrågor med hjälp av en inre koppling i stället för en yttre koppling. Det förbättrar vanligtvis frågeprestanda, även om det beror på relationsdatabaskällans specifika egenskaper. Mer information finns i Anta inställningar för referensintegritet i Power BI Desktop.
Undvik användning av dubbelriktad relationsfiltrering: Användning av dubbelriktad relationsfiltrering kan leda till frågeinstruktioner som inte fungerar bra. Använd endast den här relationsfunktionen när det behövs, och det är vanligtvis fallet när du implementerar en många-till-många-relation i en bryggningstabell. Mer information finns i Relationer med kardinaliteten många-många i Power BI Desktop.
Begränsa parallella frågor: Du kan ange det maximala antalet anslutningar som DirectQuery öppnar för varje underliggande datakälla. Den styr antalet frågor som skickas samtidigt till datakällan.
- Inställningen aktiveras bara när det finns minst en DirectQuery-källa i modellen. Värdet gäller för alla DirectQuery-källor och för alla nya DirectQuery-källor som läggs till i modellen.
- Om du ökar värdet Maximalt antal anslutningar per datakälla kan fler frågor (upp till det högsta antal som anges) skickas till den underliggande datakällan, vilket är användbart när många visuella objekt finns på en enda sida eller många användare får åtkomst till en rapport samtidigt. När det maximala antalet anslutningar har nåtts placeras ytterligare frågor i kö tills en anslutning blir tillgänglig. Om du ökar den här gränsen ökar belastningen på den underliggande datakällan, så inställningen är inte garanterad för att förbättra den övergripande prestandan.
- När modellen publiceras till Power BI beror det maximala antalet samtidiga frågor som skickas till den underliggande datakällan också på miljön. Olika miljöer (till exempel Power BI, Power BI Premium eller Power BI-rapportserver) kan var och en införa olika dataflödesbegränsningar. Mer information om kapacitetsresursbegränsningar finns i Microsoft Fabric-kapacitetslicenser och Konfigurera och hantera kapaciteter i Power BI Premium.
Viktigt!
Ibland refererar den här artikeln till Power BI Premium eller dess kapacitetsprenumerationer (P SKU:er). Tänk på att Microsoft för närvarande konsoliderar köpalternativ och drar tillbaka Power BI Premium per kapacitets-SKU:er. Nya och befintliga kunder bör överväga att köpa kapacitetsprenumerationer för Infrastrukturresurser (F SKU:er) i stället.
Mer information finns i Viktig uppdatering som kommer till Power BI Premium-licensiering och Vanliga frågor och svar om Power BI Premium.
Optimera rapportdesign
Rapporter baserade på en DirectQuery-semantisk modell kan optimeras på många sätt, enligt beskrivningen i följande punktlista.
- Aktivera tekniker för frågeminskning: Power BI Desktop-alternativ och -inställningar innehåller en sida för frågereduktion. Den här sidan har tre användbara alternativ. Det går att inaktivera korsmarkering och korsfiltrering som standard, även om det kan åsidosättas genom redigering av interaktioner. Det går också att visa knappen Tillämpa på utsnitt och filter. Alternativen för utsnitt eller filter tillämpas inte förrän rapportanvändaren klickar på knappen. Om du aktiverar de här alternativen rekommenderar vi att du gör det när du först skapar rapporten.
- Använd filter först: När du först utformar rapporter rekommenderar vi att du tillämpar alla tillämpliga filter på rapport-, sid- eller visuell nivå innan du mappar fält till de visuella fälten. I stället för att till exempel dra i måtten CountryRegion och Sales och sedan filtrera efter ett visst år tillämpar du filtret på fältet År först. Det beror på att varje steg för att skapa ett visuellt objekt skickar en fråga, och även om det är möjligt att sedan göra ytterligare en ändring innan den första frågan har slutförts, lägger den fortfarande onödig belastning på den underliggande datakällan. Genom att använda filter tidigt gör det vanligtvis dessa mellanliggande frågor mindre kostsamma och snabbare. Om du inte tillämpar filter tidigt kan det dessutom leda till att gränsen på 1 miljon rader överskrids, enligt beskrivningen i om DirectQuery.
- Begränsa antalet visuella objekt på en sida: När en rapportsida öppnas (och när sidfilter tillämpas) uppdateras alla visuella objekt på en sida. Det finns dock en gräns för hur många frågor som kan skickas parallellt, som införts av Power BI-miljön och inställningen Maximalt antal anslutningar per datakälla enligt beskrivningen ovan. I takt med att antalet visuella sidobjekt ökar är risken större att de uppdateras på ett seriellt sätt. Det ökar den tid det tar att uppdatera hela sidan, och det ökar också risken för att visuella objekt visar inkonsekventa resultat (för flyktiga datakällor). Därför rekommenderar vi att du begränsar antalet visuella objekt på en sida och i stället har enklare sidor. Om du ersätter flera visuella kortobjekt med ett enda visuellt objekt med flera rader kan du få en liknande sidlayout.
- Stäng av interaktionen mellan visuella objekt: Interaktioner mellan markeringar och korsfiltrering kräver att frågor skickas till den underliggande källan. Om inte dessa interaktioner är nödvändiga rekommenderar vi att de stängs av om den tid det tar att svara på användarnas val skulle vara orimligt lång. Dessa interaktioner kan stängas av, antingen för hela rapporten (enligt beskrivningen ovan för alternativ för frågereduktion) eller från fall till fall. Mer information finns i Hur visuella objekt korsfiltrerar varandra i en Power BI-rapport.
Förutom listan ovan över optimeringstekniker kan var och en av följande rapporteringsfunktioner bidra till prestandaproblem:
Måttfilter: Visuella objekt som innehåller mått (eller aggregeringar av kolumner) kan ha filter som tillämpas på dessa mått. Det visuella objektet nedan visar till exempel Försäljning efter kategori, men bara för kategorier med mer än 15 miljoner usd i försäljning.
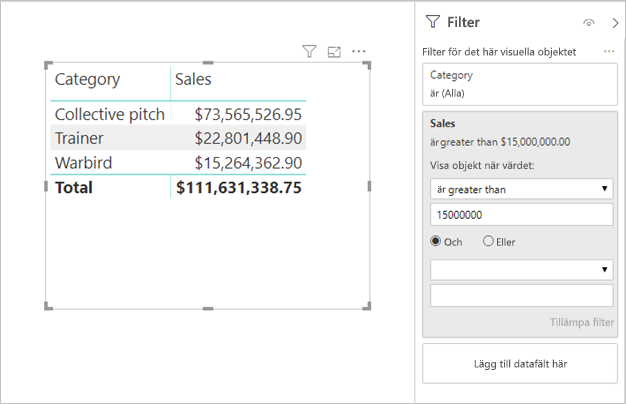
Det kan leda till att två frågor skickas till den underliggande källan:
- Den första frågan hämtar kategorierna som uppfyller villkoret (Försäljning > 15 miljoner USD)
- Den andra frågan hämtar sedan nödvändiga data för det visuella objektet och lägger till de kategorier som uppfyllde villkoret i WHERE-satsen
Det fungerar vanligtvis bra om det finns hundratals eller tusentals kategorier, som i det här exemplet. Prestanda kan dock försämras om antalet kategorier är mycket större (och frågan misslyckas om det finns fler än 1 miljon kategorier som uppfyller villkoret på grund av gränsen på 1 miljon rader som beskrivs ovan).
TopN-filter: Avancerade filter kan definieras för att endast filtrera på de översta (eller nedre) N-värdena rangordnade efter ett mått. Om du till exempel bara vill visa de fem främsta kategorierna i det visuella objektet ovan. Precis som måttfiltren resulterar det också i att två frågor skickas till den underliggande datakällan. Den första frågan returnerar dock alla kategorier från den underliggande källan och sedan bestäms det översta N baserat på de returnerade resultaten. Beroende på kardinaliteten i den aktuella kolumnen kan det leda till prestandaproblem (eller frågefel på grund av gränsen på 1 miljon rader).
Median: I allmänhet skickas alla aggregeringar (Sum, Count Distinct osv.) till den underliggande källan. Det är dock inte sant för Median eftersom den här aggregeringen inte stöds av den underliggande källan. I sådana fall hämtas informationsdata från den underliggande källan och Power BI utvärderar medianen från de returnerade resultaten. Det går bra när medianvärdet ska beräknas över ett relativt litet antal resultat, men prestandaproblem (eller frågefel på grund av gränsen på 1 miljon rader) inträffar om kardinaliteten är stor. Medianpopulationen för land/region kan till exempel vara rimlig, men medianförsäljningspriset kanske inte är det.
Utsnitt med flera val: Om du tillåter flera val i utsnitt och filter kan det orsaka prestandaproblem. Det beror på att när användaren väljer ytterligare utsnittsobjekt (till exempel att skapa upp till de 10 produkter som de är intresserade av) resulterar varje ny markering i att en ny fråga skickas till den underliggande källan. Användaren kan välja nästa objekt innan frågan slutförs, men det resulterar i extra belastning på den underliggande källan. Du kan undvika den här situationen genom att visa knappen Tillämpa enligt beskrivningen ovan i frågereduktionsteknikerna.
Visuella summor: Som standard visar tabeller och matriser summor och delsummor. I många fall måste ytterligare frågor skickas till den underliggande källan för att hämta värdena för summorna. Det gäller när du använder aggregat för antal distinkta värden eller medianvärden och i alla fall när du använder DirectQuery via SAP HANA eller SAP Business Warehouse. Sådana summor bör stängas av (med hjälp av fönstret Format) om det inte behövs.
Konvertera till en sammansatt modell
Fördelarna med import- och DirectQuery-modeller kan kombineras till en enda modell genom att konfigurera lagringsläget för modelltabellerna. Tabelllagringsläget kan vara Import eller DirectQuery, eller båda, som kallas Dubbla. När en modell innehåller tabeller med olika lagringslägen kallas den för en sammansatt modell. Mer information finns i Använda sammansatta modeller i Power BI Desktop.
Det finns många funktions- och prestandaförbättringar som kan uppnås genom att konvertera en DirectQuery-modell till en sammansatt modell. En sammansatt modell kan integrera mer än en DirectQuery-källa, och den kan även innehålla aggregeringar. Sammansättningstabeller kan läggas till i DirectQuery-tabeller för att importera en sammanfattad representation av tabellen. De kan få dramatiska prestandaförbättringar när visuella objekt frågar aggregeringar på högre nivå. Mer information finns i Sammansättningar i Power BI Desktop.
Utbilda användare
Det är viktigt att utbilda användarna om hur de effektivt kan arbeta med rapporter baserat på DirectQuery-semantiska modeller. Rapportförfattarna bör utbildas i det innehåll som beskrivs i avsnittet Optimera rapportdesign .
Vi rekommenderar att du utbildar rapportkonsumenterna om dina rapporter som baseras på DirectQuery-semantiska modeller. Det kan vara användbart för dem att förstå den allmänna dataarkitekturen, inklusive eventuella relevanta begränsningar som beskrivs i den här artikeln. Låt dem veta att uppdateringssvar och interaktiv filtrering ibland kan vara långsamma. När rapportanvändarna förstår varför prestandaförsämring inträffar är det mindre troligt att de förlorar förtroendet för rapporter och data.
När du levererar rapporter om flyktiga datakällor bör du informera rapportanvändarna om användningen av knappen Uppdatera. Låt dem också veta att det kan vara möjligt att se inkonsekventa resultat och att en uppdatering av rapporten kan lösa eventuella inkonsekvenser på rapportsidan.
Relaterat innehåll
Mer information om DirectQuery finns i följande resurser: